Data Acceleration Architecture/ Agile Analytics
Data Acceleration Architecture/ Agile Analytics
By Thomas Zarinac, Principal Director, CTO Analytics ASG, Accenture Digital
Through new hardware and software concepts such as In-Memory databases or Big Data technologies in general more and more data can be utilized for analytical purposes. Where in the past classical reports or lists on historic data have been the de-facto standard, data can nowadays be processed in near-real time to discover data patterns and predict potential outcomes. Also by integrating various data sources.
Especially in well-established industries such as insurances or the automobile industry more and more research is being performed on future-proof business models based on data. The driver is the increasing market pressure, increased regulatory requirements, increasing cost pressure and last but not least the increasing Analytics mind-set.
To fulfill all Analytics requirements the importance for integrating data with more flexibility becomes crucial. Established architectures (e.g. classical data warehouses), technologies (e.g. relational databases and methodologies (e.g. V-Model) cannot keep the pace. The answer so far where so called “Sandboxes” or other concepts that allowed to quickly deliver silo solution with no reuse. Important cross-functional requirements such as data governance, metadata management or data quality management have been excluded intentionally.
To solve the dilemma of time-to-market, quality, delivery reliability and technologies many approaches have been tested. Typical approaches like agile methodologies such as adaptive software development, Crystal, Extreme Programming, feature driven programming, Kanban or SCRUM have been a limited solution to data-driven and analytical challenges. Questions like data persistence, technology, architecture, ‘identification and meaning of data’ are rarely addressed with agile methodologies. Especially the sourcing and integration of data is a mountain to climb for many enterprises.
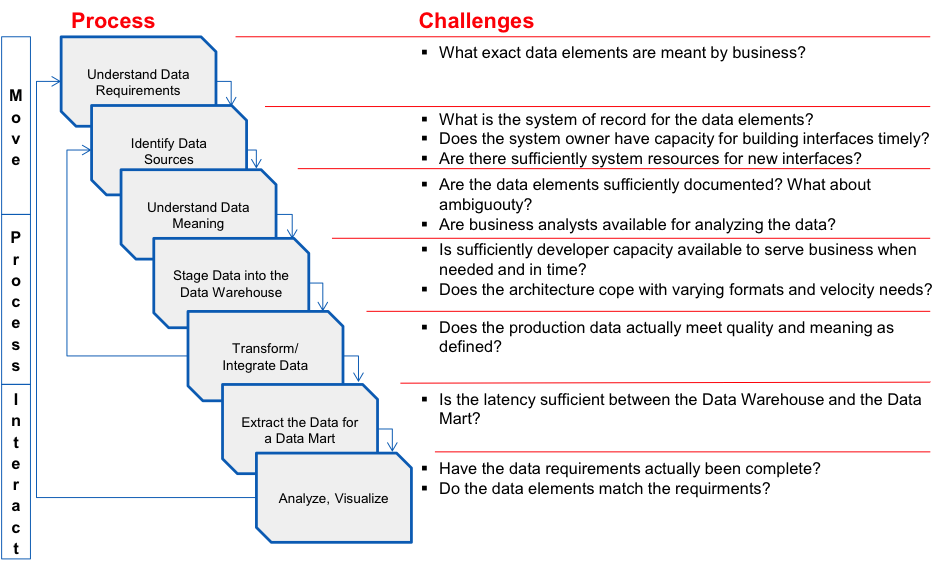
Looking on the current process of providing data insight the first step starts with understanding data requirements that Business might not be able sufficiently define. After identifying data sources the required attributes are sourced and then and analyzed in detail. If data profiling tools are used and data security allows to get in touch with production data, some surprises might be caught early; however, this is not the standard case. After some modelling work has been done the data is staged and integrated into a core model. If some data has been missed or productive data does not fully match the expectations, sourcing mainly starts from the beginning. If all required data is available and verified the actual insight generation can be started. Up to this point Business might not have seen the data, not to mention applying any agile methodologies. From this point on agile methodologies will work pretty much.
To accelerate the sourcing and processing part some changes are needed in the overall architecture. A HDFS-based Data Lake will help to get hold of data more quickly. The souring approach also changes from “selective needed data elements” to “all you can get data elements” as storage costs are lower. With HDFS the paradigm of persisting data also will be changed from “Think first, write next” or “Schema-on-write” to the easier way of “Write first, think later” or “Schema-on-read”. This architectural change is the basis for Agile Analytics; data is first put into the Data Lake and then used for data integration AND data analysis/ discovery by Business.
Especially the enablement of Business allows to independently of project-based data integration work preparing data for Analytical purposes. However with the introduction of a data lake agility will not be achieved in the first pass as there is no data in place, yet. In later stages the process changes as Business is able to source data, perform discovery, explore more data requirements with limited involvement of IT.
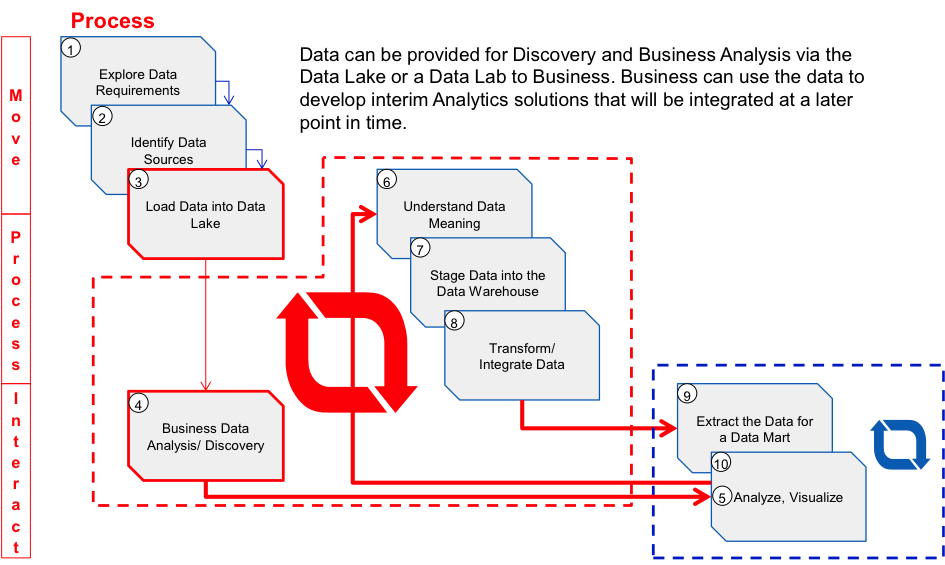
The delivery sprints are initially mainly business-driven. First analytics results can be delivered in a prototyping, agile fashion. Business has the opportunity to explorer there data requirements by looking at real data persisting in the Data Lake and the actual Data Warehouse. This is an essential step towards agility as business users can figure out, what they exactly need instead of documenting it in theory. With the right data at hand, the data can be analyzed and visualized until the expected result has been identified.
IT will take over the well understood data into the integration process and deliver it for “enterprise-like” regular processing in 2-3 week lasting sprints. After developing such standard reports, dashboards or any other analytic results, the prototyped version developed driven by Business can be decommissioned. At the same time Business continues exploring more data for more insight results.
Summary:
Agile Analytics will require architectural changes by incorporating a Data Lake based on Big Data technology. Business will be enabled to analyze and perform discovery based on real productive data in early stages of development. Once data has been understood and temporary final results have been build the classical Data Warehouse will be enhanced with new data.