Big Data is Not Big Hassle
Big Data is Not Big Hassle
by Rosaria Silipo (PhD), Principal Data Scientist, KNIME.com AG
Why Big Data. And Why Not.
It is undeniable that a big data platform might solve your problems of storing and processing the massive amount of data generated routinely by your company. It is undeniable that Spark might solve your problems of speeding up your analytics process to get the results in real time.
I know what you are thinking. “Big Data and Spark would be a nice to have, but a major change in my company organization. And I am not talking about the products and the licenses. I am talking about finding the expertise to write Spark scripts and Hadoop SQL-like instructions to make them productive. Such skills are rare on the data science market, and I have neither time nor resources to hunt them!”
This is often the main obstacle between turning your current data science strategy into a big data science strategy. But bear with me till the end of this post and I will show you that the solution is actually closer than you think. Taking advantage of its friendly graphical representation of data science workflows, KNIME Analytics Platform enables you to access big data in Hadoop like any other traditional database and to use Spark MLlib functions like any local machine learning library.
KNIME Analytics Platform is the open solution for data-driven innovation. It is fast to deploy, easy to scale, intuitive to learn – thanks to its graphical user interface- and covers the machine learning and statistics algorithm landscape extensively. KNIME Analytics Platform is open source and downloadable for free from the KNIME web site https://www.knime.org/downloads/overview .
Some time ago I developed a workflow using predictive analytics to deal with missing values in a data set. The idea was to separate records with missing values in a selected column from records with no missing values in the same columns. The second data subset was used to train a machine learning model to predict the missing values in the selected column from the other columns’ values. The workflow was using in-database processing for data transformation and a machine learning algorithm for the predictive model. Both parts were implemented and controlled from within the graphical UI of KNIME Analytics Platform. The workflow is shown in figure 1.
The workflow starts by connecting to a database (here an SQLite database for distribution purposes); continues by running some in-database aggregations, joining, and filtering; it exports the resulting data back into KNIME Analytics Platform (“Database Connection Table Reader” node); trains a decision tree on the subset of records with no missing values; applies the trained model to predict the missing values in the second subset; and finally overwrites the missing values with the predicted values in the original database table.
Three Very Appealing Features of the KNIME Big Data Extensions
Recently, I was asked to migrate this workflow to a Hadoop-Spark architecture. Once panic had settled, I started exploring KNIME Big Data Connectors and Spark Executor (under KNIME Big Data Extensions: https://www.knime.org/knime-big-data-extensions). These extensions belong to the group of KNIME commercial extensions and run on a yearly per user license. You can get a 30-day free trial license from https://www.knime.org/knime-big-data-extensions-free-30-day-trial.
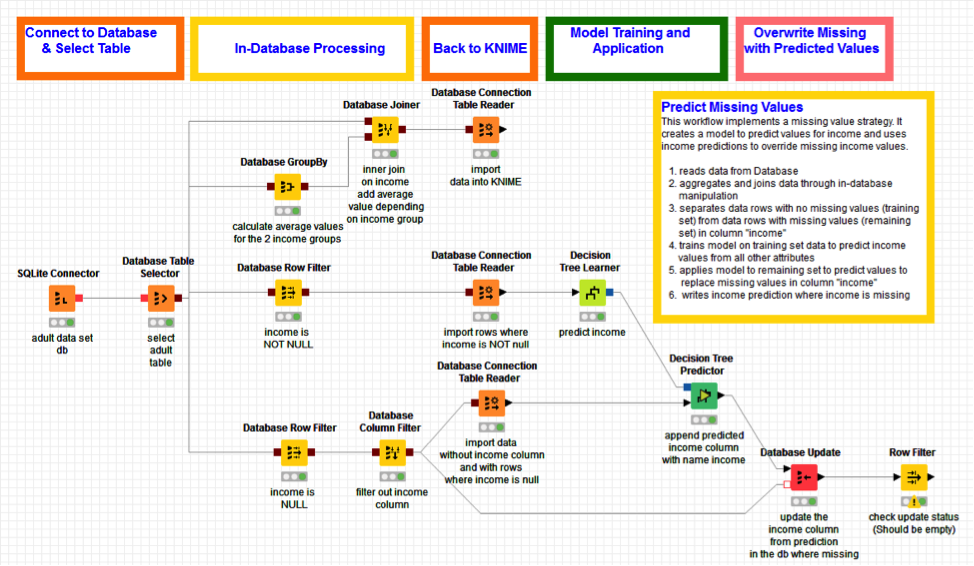
Figure 1. Workflow for replacing missing values with predictions from a machine learning model, including in-database processing and KNIME-native machine learning nodes.
The first appealing feature of the KNIME Big Data Extensions is that you use the same graphical user interface as in KNIME Analytics Platform. A number of nodes is available to work specifically on Hadoop and on Spark from within KNIME Analytics Platform, and they deploy the same node-based approach. All big data related nodes have the same configuration dialogs as the corresponding KNIME-native nodes. So, if you are familiar with KNIME you can quickly adapt your workflow to run on Spark and/or on Hadoop.
The second appealing feature is that the nodes used for traditional in-database processing are the same nodes used for Hadoop in-database processing. Exactly the same, not a copy or a similar node, but really the same nodes. When moving an in-database processing workflow from a traditional database to Hadoop, you only need to change the first node, the Database Connector, into – say a Hive Connector, for example. A number of Hadoop flavored connectors are available in category Database/Connector. I am sure you will find yours quickly!
Based on all that, in order to migrate the workflow in figure 1 to run on Hadoop all I need to do is:
- Change the Database Connector node from an SQLite Connector to a Hive Connector (or to whatever-flavor-of-Hadoop connector node)
In order to migrate only the decision tree model training and prediction onto Spark, I have to:
- Add a Table to Spark node
- Change the Decision Tree Learner and the Decision Tree Predictor node to a Spark Decision Tree Learner and a Spark Decision Tree Predictor node, respectively
- Add a Spark to Table node at the end – if I want to get the results back into KNIME Analytics Platform
Finally, in order to migrate the whole workflow to Hadoop (for in-database processing) and to Spark (for machine learning), I need to implement all of the previous steps, but could use a Hive to Spark and a Spark to Hive node rather than a Table to Spark and a Spark to Table node.
This also represents the third very appealing feature of the KNIME Big Data Extensions: you can mix and match on demand depending on how much processing you want to be run on Hadoop, how much on Spark, and how much on KNIME. No matter how you mix and match, the director of the whole orchestration system however remains KNIME Analytics Platform and the user throughout.
After migration to run in-database processing on Hadoop and machine learning on Spark, the workflow in figure 1 becomes the workflow shown in figure 2. Notice that:
- the workflow structure is the same as in figure 1;
- only a few nodes have changed and they have the same configuration dialogs as the KNIME-native corresponding nodes;
- execution on Hadoop and Spark is launched from within KNIME Analytics Platform. Elegant and easy!

Figure 2. Workflow in figure 1 after migration to run in-database processing on Hadoop and machine learning on Spark. Notice that the workflow structure is still the same, only a few nodes have changed, and the workflow can run on Hadoop and Spark from within KNIME Analytics Platform.
Big Data Does Not Have to be Big Hassle.
So, big data does not have to be big hassle. It is powerful, it is useful, it is faster … and with KNIME Big Data Extensions it is easy!
With the easy to use graphical user interface, its consistency with KNIME-native nodes, the mix and match approach, and the control of the remote execution, big data usage becomes an easy game that everyone can play.
Of course, you still need to have some knowledge about the data and the processing you are running, but this is true for big and small data alike. If you do have such knowledge, a new big data or Spark-based platform is not an obstacle anymore to move your data analytics to the next step in terms of data quantity and execution performance.
I hope I have convinced you of the little effort it takes to move an existing data analytics system to this new big data platform and I hope you can start thinking more of results and ROIs and worry less about skills and learning curves.