

“The goal of in-database machine learning is to bring popular machine learning algorithms and advanced analytical functions directly to the data, where it most commonly resides – either in a data warehouse or a data lake.” — Waqas Dhillon.
I have interviewed Waqas Dhillon, Product Manager – Machine Learning at Vertica. We talked about in-database machine learning, and what are the new machine learning features of Vertica.
RVZ
Q1. What is in-database machine learning?
Waqas Dhillon: The goal of in-database machine learning is to bring popular machine learning algorithms and advanced analytical functions directly to the data, where it most commonly resides – either in a data warehouse or a data lake. While machine learning is a common mechanism used to develop insights across a variety use cases, the growing volume of data has increased the complexity of building predictive models, since few tools are capable of processing these massive datasets. As a result, most organizations are down-sampling, which can impact the accuracy of machine models and created unnecessary steps to the predictive analytics process.
In-database machine learning changes the scale and speed through which these machine learning algorithms can be trained and deployed, removing common barriers and accelerating time to insight on predictive analytics projects. To that end, we’ve built machine learning and data preparation functions natively into Vertica, so the computational processes can be parallelized across nodes –scaling-out to address performance requirements, larger data volumes, and serving many concurrent users. Vertica in-database machine learning aims to eliminate the need of downloading and installing separate packages, purchasing 3rd party tools, or moving data out of database. Unlike traditional statistical analysis tools, we’ve given users the ability to archive and manage machine learning models inside the database, so they can train, deploy, and manage their models with a few simple lines of SQL.
Q2. What problem domains are most suitable for using Predictive Analytics?
Waqas Dhillon: Most organizations are realizing the role that predictive analytics can play in addressing certain business challenges to create a competitive advantage. While simple business intelligence and reporting has played a key role in understanding how an organization operates and where improvements can be made, the volume of data available combined with the power of machine learning is driving the adoption of forward-looking, predictive analytics projects. This adoption is compounded by an increase in end-user/customer demand for applications with embedded intelligence that no longer just identified ‘what happened’ but predicts ‘what will happen’.
In general, machine learning models using linear regression, logistic regression, naïve Bayes, etc. are better suited for problem domains involving structured data analysis. Beyond this, the most suitable domains for using predictive analytics are driven by the use cases and business applications that drive new revenue opportunities, increase operational efficiencies, or both.
Q3. Can you give us some examples?
Waqas Dhillon: In-database machine learning and the use of predictive analytics can drive tangible business benefits across a broad range of industries. Below are some of the most common industries and use cases where I’ve seen an adoption of predictive analytics capabilities:
• Financial services organizations can discover fraud, detect investment opportunities, identify clients with high-risk profiles, or determine the probability of an applicant defaulting on a loan.
• Communication service providers can leverage a variety of network probe and sensor data to analyze network performance, predict capacity constraints, and ensure quality service delivery to end customers.
• Marketing and sales organizations can use machine learning to analyze buying patterns, segment customers, personalize the shopping experience, and predict which targeted marketing campaigns will be most effective.
• Oil and gas organizations can leverage machine learning to analyze minerals to find new energy sources, streamline oil distribution for increased efficiency and cost effectiveness, or predict mechanical or sensor failures for proactive maintenance.
• Transportation organizations can analyze trends and identify patterns that can be used to enhance customer service, optimize routes, and increase profitability.
Q4. How do you handle machine learning on Big Data using an in-database approach?
Waqas Dhillon: The Vertica Analytics Platform was always built specifically for Big Data analytics and other analytical workloads where speed, scalability, and simplicity are crucial requirements.
Since we had spent years building out such a high-performance, scalable SQL engine, we started to ask ourselves, “Why should we limit the scope of our platform to standard SQL functions and descriptive analytics? Why not extend the power of Vertica to include more advanced analytics and machine learning functions?”
While some solutions might be limited by inherent architectural problems, such as lacking a shared-nothing-cluster architecture suitable for big data analytics, Vertica has an incredible engine for performing analytics on large scale data. That’s why we felt it was such an obvious choice to build machine learning functions natively into the platform. By building these machine learning capabilities on top of a foundation that already provides a tested, reliable distributed architecture and columnar compression, customers can now leverage these core features for advanced and predictive analytics uses cases.
In Vertica, we have implemented all in-database algorithms from scratch to run in parallel across multiple nodes in a cluster. Using parallel execution for model training, as well as scoring, not only results in extremely fast performance but also extends the capability of these algorithms to run on much larger datasets in comparison to traditional machine learning tools.
Using Vertica for machine learning provides another great advantage born from the fact that the computation engine and data storage management system are combined – this combination eliminates the need to move data between a database and a statistical analysis tool. You can build, share and deploy your machine learning pipelines in-place, where the data lives. This is a very important consideration when working with Big Data since it’s not just difficult, but sometimes outright impossible to move data at that scale between different tools.
Q5. How does Vertica support the machine learning process? Can you give some examples?
Waqas Dhillon: Vertica supports the entire machine learning workflow from data exploration and preparation to model deployment.
Users can explore their data using native database functions. As an analytics database, Vertica includes a large number of functions to support data exploration, and many more have recently been added to the machine learning library. Users can also prepare data with functions for normalization, outlier detection, sampling, imbalanced data processing, missing value imputation and many other native SQL and extended functions. They can also train and test advanced machine learning models like random forests and support vector machines on very large data sets.
There are multiple model evaluation metrics likes ROC, lift-table, AUC, etc. which can be used to assess your existing trained models. Any models built within Vertica can be stored inside the platform, shared with other users using the same instance of Vertica, or exported out to other Vertica databases. This can be quite useful while training models in test clusters and then moving them to production clusters. Training and managing models inside the database also reduces the overhead needed to transfer data into another system for analysis, along with the maintenance of that system.
Q6. How did you take advantage of a Massively Parallel Processing (MPP) Architecture, when implementing in-database machine learning in Vertica?
Waqas Dhillon: Vertica’s MPP architecture provided a great foundation on top of which we built a range of in-database machine learning functions, from data ingestion to model storage and scoring capabilities.
For data ingestion, there was already an extremely fast copy command used to move data in parallel into Vertica, where it’s stored on multiple nodes in a cluster. When we were writing our distributed machine learning algorithms, we could already rely on the data distribution across various nodes and instead focus our engineering efforts on the computation logic used to parallelize model training. We have also used a built-in distributed file system to maintain intermediate results as well as the final, trained models. These machine learning functions are mainly developed using Vertica’s C++ SDK, and are executed with Vertica’s distributed execution-engine.
To give an example of a machine learning algorithm used natively within Vertica leveraging the MPP architecture, let’s look at Random Forests. Random Forests is a popular algorithm among data scientists for training predictive models that can be applied to both regression and classification problems. It provides good prediction performance, and is quite robust against overfitting. The running time and memory footprint of this algorithm in R-randomForest package or Python-sklearn can be a major hurdle when working with large data volumes.
Our distributed implementation of Random Forest overcomes these obstacles. Model training is distributed across multiple nodes in a distributed architecture with multiple trees possibly being trained on the various nodes in the network, and then combining these results to provide a classification model. This model can then be used to perform scoring in parallel on data that might be distributed across multiple nodes (possibly hundreds) in a cluster.
Q7. You offer SQL-based machine learning functions. Is this an extension to SQL? Can you give us some examples?
Waqas Dhillon: Although Vertica follows the SQL standard, it offers multiple SQL extensions such as windowing functions and pattern matching. In-database machine learning algorithms are now part of the database’s analytical toolset, allowing users to write SQL like commands to run machine learning processes. They go beyond other, simpler SQL extensions users will find within Vertica.
For example, a simpler SQL extension in Vertica would be event series pattern matching. Event patterns are simply a series of events that occur in an order, or pattern that you specify. Vertica evaluates each row in your table, looking for the event you define. When Vertica finds a sequence of rows that conform to your pattern among a dataset of possibly hundreds of billions of rows or more, it outputs the rows that contribute to the match.
An example of a SQL extension for machine learning would be support vector machines (SVM). SVM is a very powerful algorithm that can be applied to large data sets for both classification and regression problems. For instance, an SVM model can be trained to predict the sales revenue of an e-commerce platform. There are many other extended SQL functions in Vertica as well to support a typical machine learning workflow from data preparation to model deployment.
Q8. What are the common barriers to Applying Machine Learning at Scale?
Waqas Dhillon: There are several challenges when it comes to applying machine learning to massive volumes of data. Predictive analytics can be complex, especially when big data is added to the mix. Since larger data sets yield more accurate results, high-performance, distributed, and parallel processing is required to obtain insights at a reasonable speed suitable for today’s business.
Traditional machine learning tools require data scientists to build and tune models using only small subsets of data (called down-sampling) and move data across different databases and tools, often resulting in inaccuracies, delays, increased costs, and slower access to critical insights:
• Slower development: Delays in moving large volumes of data between systems increases the amount of time data scientists spend creating predictive analytics models, which delays time-to-value.
• Inaccurate predictions: Since large data sets cannot be processed due to memory and computational limitations with traditional methods, only a subset of the data is analyzed, reducing the accuracy of subsequent insights and putting at risk any business decisions based on these insights.
• Delayed deployment: Owing to complex processes, deploying predictive models into production is often slow and tedious, jeopardizing the success of big data initiatives.
• Increased costs: Additional hardware, software tools, and administrator and developer resources are required for moving data, building duplicate predictive models, and running them on multiple platforms to obtain the desired results.
• Model management: Archiving and managing the machine learning models is a challenge when using most of the data science tools as they usually lack a mechanism for model management.
Q9. How do you overcome such barriers in Vertica?
Waqas Dhillon: Capable of storing large amounts of diverse data while also providing key built-in machine learning algorithms, Vertica eliminates or minimizes many of these barriers. Built from the ground up to handle massive volumes of data, Vertica is designed specifically to address the challenges of big data analytics using a balanced, distributed, compressed columnar paradigm.
Massively parallel processing enables data to be handled at petabyte scale for your most demanding use cases. Column store capabilities provide data compression, reducing big data analytics query times from hours to minutes or minutes to seconds, compared to legacy technologies. In addition, as a full-featured analytics system, Vertica provides advanced SQL-based analytics including pattern matching, geospatial analytics and many more capabilities.
As an optimized platform enabling advanced predictive modeling to be run from within the database and across large data sets, Vertica eliminates the need for data duplication and processing on alternative platforms—typically requiring multi-vendor offerings—that add complexity and cost. Now that same speed, scale, and performance used for SQL-based analytics can be applied to machine learning algorithms, with both running on a single system for additional simplification and cost savings.
————————————-

Waqas Dhillon, Product Manager – Machine Learning, Vertica
Waqas is the product management lead for machine learning with Vertica. In his current role, he drives the strategy and implementation of advanced analytics and machine learning features in the Vertica MPP platform. Waqas holds a bachelor’s degree in computer software engineering from NUST and a master’s degree in management from Harvard University.
Prior to his current role, Waqas has worked in multiple positions where he applied data analytics and machine learning for consumer research and revenue growth for companies in consumer packaged goods and telecommunication industries.
Resources
– Vertica in-database machine learning: product page.
– Vertica in-database machine learning: full documentation.
– Try version of Vertica for free
Related Posts
– On using AI and Data Analytics in Pharmaceutical Research. Interview with Bryn Roberts ODBMS Industry Watch, Published on 2018-09-10
– On AI and Data Technology Innovation in the Rail Industry. Interview with Gerhard Kress ODBMS Industry Watch, Published on 2018-07-31
– On Artificial Intelligence, Machine Learning, and Deep Learning. Interview with Pedro Domingos ODBMS Industry Watch, Published on 2018-06-18
Follow us on Twitter: @odbmsorg
##
Are computer system designers (i.e. Software Developers, Software Engineers, Data Scientists, Data Engineers, etc,), the ones who will decide what the impact of these technologies are and whether to replace or augment humans in society?
Big Data, AI and Intelligent systems are becoming sophisticated tools in the hands of a variety of stakeholders, including political leaders.
Some AI applications may raise new ethical and legal questions, for example related to liability or potentially biased decision-making.
I recently gave a talk at UC Berkeley on the Ethical and Societal implications of Big Data and AI and what designers of intelligent systems can do to take responsibility, not only for policy makers and lawyers.
You can find copy of the presentation here:
http://www.odbms.org/wp-content/uploads/2018/10/Zicari.UCBerkeley.2018.pdf
I am interested to hear from you and receive your feedback.
RVZ
“Creating a suitable ethical and legal framework is key to our European approach on AI and draft AI ethics guidelines will be developed by the end of the year.”– Roberto Viola
I have interviewed Roberto Viola, Director General of DG CONNECT (Directorate General of Communication Networks, Content and Technology) at the European Commission. We talked about the future of AI in Europe, and the new initiatives of the European Commission to foster public and private investment in AI, and to create a “Digital Europe programme”.
RVZ
Q1. Companies with big data pools do have great economic power. Today, that shortlist includes USA companies such as Google, Microsoft, Facebook, Amazon, Apple, and Chinese companies such as Baidu. None of these companies are European.
USA and China are ahead of Europe in developing Data-driven services and solutions, often based on AI. Would you like to comment on this?
Roberto Viola: Europe is quite strong in many areas of AI: it is home to world-class researchers, labs and start-ups, and we have a strong industrial base that can be at the forefront of the adoption of AI. We can capitalise on our assets and strengthen European leadership by supporting excellence in research, particularly in areas where we already lead e.g. in robotics.
However, it is true that, overall Europe is behind in private investment in AI, compared to North America and Asia, and that is why it is crucial that the EU creates an environment that stimulates investment. Our goal is to build on our strengths and support the European entrepreneurial spirit. We must also ensure broader and easier access to services for citizens and industry and address socio-economic and legal issues, based on strong European values such as privacy and data protection.
It is important for European countries and various stakeholders to work together when trying to accomplish these things.
That is why we created the European AI Alliance. Here, everyone with an interest in AI can imagine its future shape, discuss how to maximise the benefits for everyone or debate how to develop ethical AI. I would also like to use this opportunity to invite everyone with an expertise or interest in AI to join the AI Alliance and actively participate in it.
Q2. What are in your opinion the main challenges in the adoption of AI in Europe?
Roberto Viola: The biggest challenge is the adoption of AI all over Europe by organisations of any size and in all fields, not just in the tech sector. This is a key priority for us. AI is already in use in many areas in Europe, and surveys show that the benefits of adopting AI are widely recognised by European businesses. However, only a fraction of European companies have already adopted digital technologies. This situation is particularly acute in the SME category: last year for example, only 10% of SMEs in the EU were using big data analytics, which could in turn be used to build AI technologies.
Europe can only reap the full benefits of AI if all have easy access to the technology and to related knowledge and services. That is why we focus on facilitating access for all potential users to AI technologies, in particular SMEs, companies from non-tech sectors and public administrations, and encourage them to test AI solutions. We aim to achieve this by setting up an AI-on-demand platform and via a network of Digital Innovation Hubs (DIHs). This includes both an existing network of more than 400 DIHs and a new dedicated network of AI-focused DIHs.
Q3. AI technologies can be used either to automate or to augment humans. In the first case, machines replace people, in the second case machine complements people (at least in theory). What is your take on this?
Roberto Viola: I believe that AI cannot only make the lives of workers easier, for example by helping with repetitive, strenuous or dangerous tasks but that it can also provide new solutions by supporting more people to participate and remain in the labour market, including people with disabilities. It is estimated, for example, that around 90% of road accidents are caused by human errors. AI can help to reduce this number. It is vital, however, that these new developments and uses of AI are carried out in an environment of trust and accountability. Creating a suitable ethical and legal framework is key to our European approach on AI and draft AI ethics guidelines will be developed by the end of the year.
AI will both create and destroy jobs, and it will certainly transform many of the existing jobs. AI, like other new technologies before it, is expected to change the nature of work and transform the labour market. It remains unclear what the net effect will be, and studies of the subject differ widely. However, it is obvious that our workforce will have to re-skill and up-skill to be able to master these changes. The ICT sector has created 1.8 million jobs since 2011 and the need for ICT specialists continues to grow. There are now at least 350,000 vacancies for such professionals in Europe pointing to significant skills gaps. Preparing for these socioeconomic changes is one of the three main dimensions of the EU initiative on AI: we need to prepare society as a whole, help workers in jobs that are most likely to be transformed or to disappear, and train more specialists in AI.
Q4. The European Commission has recently proposed an approach to increase public and private investment in AI in Europe. Can you elaborate on this?
Roberto Viola: Our ambitious proposals for investment in AI include a total of EUR20 billion in public and private funding for the period 2018-2020, and then reaching a yearly average of EUR20 billion in the decade after 2020.
The Commission is stepping up its own investment to roughly EUR1.5 billion by the end of 2020 – an increase of around 70%.
The total amounts that we have proposed can be achieved if Member States and the private sector make similar investment efforts, and we are working closely with the Member States on a coordinated action plan on AI to be agreed by the end of 2018, with a view to maximising the impact of such investments at EU and national level.
Under the next multiannual budget of the EU, the Commission plans to increase its investment in AI further, mainly through two programmes: the research and innovation framework programme Horizon Europe, and a new programme called Digital Europe.
Out of a total of nearly EUR100 billion for 2021-2027 under Horizon Europe, the Commission proposes to invest EUR15 billion in the Digital and Industry cluster, which also includes AI as a key activity.
We intend to fund both research and innovation and the accelerating adoption of AI. We will support basic and industrial research, and breakthrough market-creating innovation. Building on Member States’ efforts to establish joint AI-focused research centres, the objective is to strengthen AI excellence centres across Europe by facilitating collaboration and networking between them. Furthermore, the Commission will provide support for testing and experimentation infrastructures that are open to businesses of all sizes and from all regions.
Q5. What instruments do you have to assess the impact of such a plan?
Roberto Viola: We will monitor the adoption of AI across the economy and identify potential shifts in industrial value chains caused by AI as well as societal and legal developments and the situation on the labour market.
We will also regularly evaluate progress towards our objectives. This will involve a systematic analysis of AI-related developments such as advances in AI capabilities, policy initiatives in the Member States, the application of AI solutions in different sectors of the economy, and the effects that the spread of AI applications will have on labour markets.
Q6. Professional codes of ethics do little to change peoples’ behaviour. How is it possible to define incentives for using an ethical approach to software development, especially in the area of AI?
Roberto Viola: AI has great potential benefits – ranging from making our IT systems more efficient to solving some of the world’s greatest challenges, but it also comes with considerable challenges and risks. Some AI applications may indeed raise new ethical and legal questions, for example related to liability or potentially biased decision-making.
For example, algorithms are used to review loan applications, recruit new employees and assess potential customers, and if the data are skewed the decisions recommended by such algorithms may be discriminatory against certain categories or groups.
Given such risks, there is strong demand for the EU to ensure that AI is developed and applied within an appropriate framework that promotes innovation but at the same time also protects our values and fundamental rights.
As a first step, we have initiated the process of drawing up draft AI ethics guidelines with the involvement of all relevant stakeholders. The Commission has set up a new High-Level Expert Group on Artificial Intelligence and a European AI Alliance that brings together a large number of stakeholders. They will work together in close cooperation with representatives from EU Member States to prepare draft AI ethics guidelines that will cover aspects such as the future of work, fairness, safety, security, social inclusion and algorithmic transparency.
While self-regulation can be a first stage in applying an ethical approach, public authorities must ensure that the regulatory framework that applies to AI technologies is fit for purpose and in line with our values and fundamental rights.
For example, the Commission is currently assessing the safety and national and EU liability frameworks in light of the new challenges, and we will examine whether any legislative changes are required. Evaluations of the Product Liability Directive and the Machinery Directive have already been conducted. On the evaluation of the Product Liability Directive, the Commission will issue an interpretative guidance document by mid-2019. The Commission has also carried out an initial assessment of the current liability frameworks. An expert group will help the Commission to analyse these challenges further. We will publish a report, by mid-2019, on the broader implications for, potential gaps in, and orientations for the liability and safety frameworks for AI, Internet of Things and robotics.
Q7. The European Commission has also proposed to create a “Digital Europe programme”. What is it? What are the areas that the Commission will support under such program?
Roberto Viola: Digital Europe is a new programme that builds on the EU’s Digital Single Market strategy launched in 2015 and its achievements so far, and it is aimed at aligning the next multiannual EU budget with increasing digital challenges. The total amount proposed under Digital Europe is €9.2 billion, targeting five areas of investment: digital skills, cybersecurity, high performance computing, artificial intelligence, and public administration.
€2.5 billion of Digital Europe are earmarked for AI: the funding will target in particular testing and experimentation facilities and data platforms. Digital Europe also provides for investing €700 million in supporting the development of advanced digital skills, and €1.3 billion in support for deployment projects, notably in areas like AI.
Q9. Data, AI and Intelligent systems are becoming sophisticated tools in the hands of a variety of stakeholders, including political leaders. “Under the label of “nudging,” and on massive scale, some governments are trying to steer citizens towards healthier or more environmentally friendly behaviour by means of a “nudge”—a modern form of paternalism.
The magic phrase is “big nudging“, which is the combination of big data with nudging.” Is the European Commission doing anything to avoid this in Europe?
Roberto Viola: Like every technology or tool, AI generates new opportunities, but also poses new challenges and risks. Such risks will be addressed in the draft AI ethics guidelines that will be prepared by the High-Level Expert Group on Artificial Intelligence. AI systems have to be developed and used within a framework of trust and accountability.
Citizens and businesses alike need to be able to trust the technology they interact with, and have effective safeguards protecting fundamental rights and freedoms. In order to increase transparency and minimise the risk of bias, AI systems should be developed and deployed in a manner that allows humans to understand the basis of their actions. Explainable AI is an essential factor in the process of strengthening people’s trust in such systems.
Q10. Do we need to regulate the development of artificial intelligence?
Roberto Viola: The Commission closely monitors all relevant developments related to AI and, if necessary, we will review our existing legal framework. The EU has a strong and balanced regulatory framework to build on in order to develop a sustainable approach to AI technologies. This includes high standards in terms of safety and product liability, EU-wide rules on network and information systems security and stronger protection of personal data that came into force in May 2018.
——————————————————

Roberto Viola is Director General of DG CONNECT (Directorate General of Communication Networks, Content and Technology) at the European Commission.
He was the Deputy Director-General of DG CONNECT, European Commission from 2012 to 2015.
Roberto Viola served as Chairman of the European Radio Spectrum Policy group (RSPG) from 2012 to 2013, as Deputy Chairman in 2011 and Chairman in 2010. He was a member of the BEREC Board (Body of European Telecom Regulators), and Chairman of the European Regulatory Group (ERG).
He held the position of Secretary General in charge of managing AGCOM, from 2005 to 2012. Prior to this, he served as Director of Regulation Department and Technical Director in AGCOM from 1999 to 2004.
From 1985-1999 he served in various positions including Head of Telecommunication and Broadcasting Satellite Services at the European Space Agency (ESA).
Roberto Viola holds a Doctorate in Electronic Engineering and a Masters in Business Administration (MBA).
Resources
– High Level Expert group on AI
– Communication Artificial Intelligence for Europe
– European Commission website on AI policy
Digital Europe:
Link to press release: http://europa.eu/rapid/press-release_IP-18-4043_en.htm
Link to regulation page: https://ec.europa.eu/info/law/better-regulation/initiatives/com-2018-434_fr
– According to McKinsey (2016), European companies operating at the digital frontier only reach a digitisation level of 60% compared to their US peers. Source: https://ec.europa.eu/digital-single-market/digital-scoreboard.
Related Posts
– On Artificial Intelligence, Machine Learning, and Deep Learning. Interview with Pedro Domingos, ODBMS Industry Watch, June 6, 2018
– On Technology Innovation, AI and IoT. Interview with Philippe Kahn , ODBMS Industry Watch, January 27, 2018
– Will Democracy Survive Big Data and Artificial Intelligence? — Dirk Helbing, Bruno S. Frey, Gerd Gigerenzer, Ernst Hafen, Michael Hagner, Yvonne Hofstetter, Jeroen van den Hoven, Roberto V. Zicari and Andrej Zwitter, Scientific America, February 25, 2017
Follow us on Twitter: @odbmsorg
##
“The efficacy of any recommendations or results is entirely dependent on ensuring the right data is being fed into purpose-built models — not simply enabling a connection to Google TensorFlow or Apache Spark MLlib.”– Ravi Mayuram
I have interviewed Ravi Mayuram, Senior Vice President of Engineering and CTO of Couchbase. Main topics of the interview are: how the latest technology trends are influencing the database market, what is an engagement database, and how Couchbase plan to extend their data platform.
RVZ
Q1. How are the latest technology trends- such as for example cloud-native, containers, IoT, edge computing- influencing the database market?
Ravi Mayuram: Businesses today are tasked with solving much harder technological problems than ever before.
A massive amount of data is being generated at an unprecedented pace, and companies are pursuing several technology trends (cloud-native architectures, containerization, IoT data management solutions, edge computing) to maintain or uncover new competitive advantages.
This wide array of trends require a combination of several types of solutions. Common approaches of adding yet another backend toolkit are no longer competitive. Instead, bringing the power of high speed data interaction out of the database and into the hands of users has stretched developers and the tools they use.
What’s becoming more apparent is that while the latest technologies can certainly address capturing and managing this data explosion, the hard part is to minimize database sprawl by meeting different use cases in a consolidated platform. Only then can you get the full benefit of intelligently combining different data sources and technologies. And that’s precisely where I see these trends influencing the database market: a need to consolidate multiple point solutions into a single platform that will allow us to cover a much wider range of use cases, and at the same time, contain the sprawl.
With a database technology like Couchbase, we’ve recognized this challenge and built a single platform to manage that convergence, giving you access to your data in a flexible, intuitive way. The database itself is more intelligent than ever before – self-managing, more easily deployable, and handling failures better. We’ve focused on introducing new features that allow developers to extract more value (intelligently!) from their data sources via new analytics, eventing, and text search services – all in a single platform. The end result is a more seamless experience across a wider range of technology trends and endpoints, helping our customers gain actionable insights from data captured and stored in Couchbase yet pushed out to the edge to enable user interaction better than ever before.
Q2. How have databases changed over the last 5 years?
Ravi Mayuram: Over the last 7-8 years, the NoSQL movement has matured tremendously. Initially, there was a vast divide in what traditional database systems offered and what NoSQL databases held promise to deliver. While the new databases solved the scale and performance problems, they were not mature in their industrial strength or were not enterprise-grade. These issues have been addressed, and more and more business-critical data now sits in NoSQL systems. These modern database systems are also getting battle tested under production workloads, across every industry imaginable. This has made our engagement database increasingly robust and dependable for developers to stand up far more complex applications, while delivering significant value to the customers they serve.
Q3. What are the main use cases where organisations will benefit in transitioning workloads from relational databases to non relational multi-cloud environments?
Ravi Mayuram: Enterprises have chosen Couchbase to run their most mission critical applications for its rich set of capabilities – from the cloud to the edge.
Today’s database capabilities are increasingly defined by the end user application of the tool. For example, due to the dynamic nature of applications as they mature, the database must have a flexible schema that can adapt as needed. Similarly, it must support both clustered server environments as well as in “always on” mobile applications. The database must also be able to grow and scale as needed along with supporting highly available environments and global, replicated, environments.
At a high level, our customers are building user profiles, session stores, operational dashboarding, and personalization services for their Customer 360, Field Service, Catalog & Inventory Management, and IoT Data Management solutions.
And that’s because relational databases can’t keep up with the demands of these types of applications anymore. More data than ever before is now being generated at every single customer and employee touch point, and the ability to capture new types of data on the fly, and securely move, query, and analyze that data requires a flexible, geo-distributed, robust data platform. Couchbase Data Platform consolidates many tiers into one – caching, database, full text search, database replication technologies, mobile back end services, and mobile databases. This consolidation of tiers enables architects and developers to build and deliver application that have not been brought to market before, and at the same time, modernize existing applications efficiently and quickly.
Specifically, some use-cases include content entitlement, site monitoring, shopping cart, inventory/pricing engine, recommendation engine, fleet tracking, identity platform, work order management, and mobile wallet to name a few.
Q4. How do you define an end-to-end platform?
Ravi Mayuram: From a technical requirements perspective, there are six key concerns I believe a true end-to-end platforms solves for:
- Intuitive: Accessing data has to be easy. It must follow industry conventions that are familiar to SQL database users. Using standard SQL query patterns allows applications to be developed faster by leveraging existing database knowledge whether for ad hoc querying, real-time analytics, or text search.
- Cloud: The platform must be built for any type of cloud: private, public, hybrid, on-premises. And it has to be global, always available, all the time.
- Scale: The platform must be built for scale. This is a given. As your user demand spikes, your data platform needs to support that.
- Mobile: The platform must be seamlessly mobile. Data must be available at the point of interaction in today’s digital world, and that has grown ever-so important as more customers and employees have moved to mobile devices for their everyday activities.
- Always-on availability: The platform should always be on (five nines availability), and always be fast. No downtime, because who can afford downtime in today’s global economy?
- Security across the stack: The platform needs to be secure, end-to-end. A lot of customer and business data sits in these databases. You must be able to encrypt, audit, protect, and secure your data wherever it lives – on the device, over the internet, in the cloud.
Based on these criteria, I’d define an end-to-end platform as one just like Couchbase provides.
Q5. You have positioned Couchbase as the ‘engagement database’. How would you define an engagement database? What are the competitive differentiators compared with other types of databases?
Ravi Mayuram: An engagement database makes it easier to capture, manipulate, and retrieve the data involved in every interaction between customers, employees, and machines. The exponential rise of big data is making it more costly and technically challenging for massively interactive enterprises to process – and leverage – those interactions, especially as they become richer and more complex in terms of the data, documents, and information that are shared and created.
Many organizations have been forced to deploy a hard-to-manage collection of disparate point solutions. These overly complex systems are difficult to change, expensive to maintain, and slow, and that ultimately harms the customer experience.
An engagement database enhances application development agility by capitalizing on a declarative query language, full-text search, and adaptive indexing capabilities, plus seamless data mobility. It offers unparalleled performance at scale – any volume, volatility, or speed of data, any number of data sources, and any number of end users with an in-memory dataset process, smart optimization, and highly performant indexing. And it does all this while remaining simple to configure and set up, easy to manage across the multi-cloud environments common in today’s enterprises, as well as globally reliable and secure in context of the stringent uptime requirements for business-critical applications.
Q6. Often software vendors offer managed services within their own cloud environments. Why did you partner with Rackspace instead?
Ravi Mayuram: One of the key tenets of Couchbase Managed Cloud was to offer our customers maximum flexibility without compromise – with respect to performance, security and manageability. By deploying within the customer’s cloud environment, we can achieve all three without any compromises:
- Co-locating applications and databases within the same cloud environment eliminates expensive hops of traversing cloud environment boundaries thus offering the maximum performance possible at the lowest possible latency.
- Enables the infrastructure and data to reside within the security boundaries defined by the customer to ensure a consistent security and compliance enforcement across their entire cloud infrastructure.
- Lastly it gives our customers choice and flexibility to get the best pricing on their cloud infrastructure from their provider of choice without a vendor in the middle charging a premium for the same infrastructure as some of our competitors force them to.
Along with our design principles, it also became evident to us early on, that instead of building this on our own we would serve our customers better by partnering with someone who has developed significant managed services expertise. We quickly zoned in on Rackspace – a pioneer in the managed services industry – as our partner of choice. We believe this best of breed combination of Couchbase’s database expertise with our powerful NOSQL technology and Rackspace’s fanatical support model and dev-ops expertise offers our customer a compelling option as evidenced by the overwhelming response to the product since its launch.
Q7. What technical challenges do developers need to overcome as they begin to integrate emerging technologies such as AI, machine learning and edge computing into their applications?
Ravi Mayuram: AI/ML brings together multiple disciplines from data engineering to data science, and the cross-disciplinary nature of these implementations is often at the core of the technical challenges for developers. Combining the knowledge of how the models and algorithms work with a firm and grounding in the data being fed into those models, is critical yet challenging. Moreover, with machine learning we have a fundamentally difficult debugging problem, rooted in requisite modeling creativity and extensive experimentation. Thus the efficacy of any recommendations or results is entirely dependent on ensuring the right data is being fed into purpose-built models — not simply enabling a connection to Google TensorFlow or Apache Spark MLlib.
Add in edge computing, and we are further confounded by the challenges of big data, from streaming analytics requiring active queries where the answers update in real-time as the data changes, to long-term storage and management of real-time data, both on the cloud and on the edge.
Q8. Talking with your customers, what are their biggest unmet, underserved needs?
Ravi Mayuram: For many of our customers, it comes down to a matter of scale. Information architectures in enterprises have evolved over time to include many solutions, all aimed at different needs. That makes it hard to really capitalize on the data that is now an asset for every business. As traffic grows, it can be impossible to adequately scale performance, a headache to manage multiple complex software solutions, avoid duplication of data, and difficult to quickly develop applications that meet the modern expectations for user experience.
As we continue to evolve our platform, we look for opportunities to solve for these challenges. We architected the platform from the ground up to meet the demands of enterprise performance. We are consolidating more services in the database tier, bringing logic to the data layer to make sure these businesses are more efficient about how they capitalize on their data assets. We make sure we leverage language familiar to developers and we contribute to and build toward industry standards.
Ultimately, we want to provide a data platform that both empowers architects to solve their near-term issues and supports their long-term digital strategy, whatever that may be.
Q9. What advice would you offer enterprises for managing database sprawl?
Ravi Mayuram: “Database sprawl” has continued to be one of the biggest issues facing companies today.
As applications continue to evolve, rapidly changing requirements have led to a growing number of point solutions at the data layer. The organization is then forced to stitch together a broad array of niche solutions and manage the complexity of changing API’s and versions. Without a platform to contain this sprawl, companies are moving data between systems, inexplicably duplicating data, changing the data model or format to suit each individual technology while working to learn the internal skills necessary to manage all of them. That’s why so many companies are choosing a platform like Couchbase, to consolidate these technologies, enabling them to bring their solutions faster to market with streamlined data management.
Q10. How do you plan to extend your platform?
Ravi Mayuram: As our customers continue to converge data technologies onto Couchbase, we will remain steadfast on building the most robust, highly-performant enterprise platform for data management. At the same time, systems are expected to become more and more intelligent. As we automate more and more database services, we envision increasingly autonomous systems – that can self-manage, and be self-healing. We’ve already built tools like our Autonomous Operator for Kubernetes that help with the heavy lifting in cloud environments. We’re providing new capabilities like the Couchbase Analytics service that will allow users to get real-time analytics from their operational data, and Couchbase Eventing for server-side processing.
Meanwhile, as the amount of data grows, so does the need to extract more value from that data. We are aiming to further decrease the total cost of ownership by reducing operational complexity and supporting more multi-tenancy and high application density scenarios. All of these features will extend our platform into a more manageable, responsive, and intelligent system for our users.
———————————————-

Ravi Mayuram
As Senior Vice President of Engineering and CTO, Ravi is responsible for product development and delivery of the Couchbase Data Platform, which includes Couchbase Server and Couchbase Mobile. He came to Couchbase from Oracle, where he served as senior director of engineering and led innovation in the areas of recommender systems and social graph, search and analytics, and lightweight client frameworks. Also while at Oracle, Ravi was responsible for kickstarting the cloud collaboration platform. Previously in his career, Ravi held senior technical and management positions at BEA, Siebel, Informix, HP, and startup BroadBand Office. Ravi holds a Master of Science degree in Mathematics from University of Delhi.
Resources
– Couchbase Announces First Commercial Implementation of SQL++ with N1QL for Analytics
– Don Chamberlin’s SQL++ Tutorial (LINK to .PDF registration required)
Related Posts
Follow us on Twitter: @odbmsorg
##
” I’m intrigued by the general trend towards empowering individuals to share their data in a secure and controlled environment. Democratisation of data in this way has to be the future. Imagine what we will be able to do in decades to come, when individuals have access to their complete healthcare records in electronic form, paired with high quality data from genomics, epigenetics, microbiome, imaging, activity and lifestyle profiles, etc., supported by a platform that enables individuals to share all or parts of their data with partners of their choice, for purposes they care about, in return for services they value – very exciting! “ —Bryn Roberts
I have interviewed Bryn Roberts, Global Head of Operations for Roche Pharmaceutical Research & Early Development, and Site Head in Basel. We talked about using AI and Data Analytics in Pharmaceutical Research.
RVZ
Q1. What are your responsibilities as Global Head of Operations for Roche Pharmaceutical Research & Early Development, and Site Head in Basel?
Bryn Roberts: I have a broad range of responsibilities that center around creating and operating a highly innovative global R&D enterprise, Roche pRED, where excellent scientific decision making is optimised along with efficiency, effectiveness, sustainability and compliance. Informatics is my largest department and includes workflow platforms in discovery and early development, architecture, infrastructure and software development, data science and digital solutions.
Facilities, infrastructure and end-to-end lab services, including three new R&D center building projects, provide state-of-the-art innovation centers and labs that integrate the latest architectural concepts, instrumentation, automation, robotics and supply chain to facilitate cutting-edge science.
These more tangible assets are complemented by a number of business operations teams, who oversee quality, compliance, risk management and business continuity, information and knowledge management, research contracts, academic and industrial collaborations, change and transformation, procurement, safety-health-environment, etc.
Finally, leadership of our Personalised Healthcare and Medical Genomics strategies and initiatives, ensuring close collaboration and insight sharing across the Roche Group.
As the Site Head for the Roche Innovation Center in Basel, I am, together with my local leadership team, accountable for the engagement and well-being of more than a thousand Research and Early Development colleagues at our headquarter site.
Our task is to create a vibrant environment that attracts, motivates and equips world-class talent. Initiatives range from scientific meetings, wellbeing programmes, workplace improvements, communication and knowledge sharing, celebrations and social events, to engagement of local academic and governmental organizations, sponsorship of local scientific conferences, and contribution to the overall Roche site development in Basel and Kaiseraugst.
Q2. Understanding a disease now requires integrated data and advanced analytics. What are the most common problems you encounter when integrating data from different sources and how you solve them?
Bryn Roberts: The challenges often relate to the topics represented by the FAIR acronym. These are Findability, Accessibility, Interoperability and Reusability. As with all organizations where large data assets have been generated and acquired over a long period of time, across many departments and projects, it is challenging to establish and maintain these FAIR Data principles. We have been committed to FAIR data for many years and continue to increase our investment in ‘FAIRification’, with particular emphasis currently on clinical trial and real-world data. Addressing the challenges requires a well thought through, and robustly implemented, information architecture incorporating data catalogues based on high quality meta-data, a holistic terminology service that enables semantic data integration, curation processes supporting data quality and annotation, appropriate application of data standards, etc.
On the advanced analytics side, it is very helpful to establish mechanisms for sharing algorithms and analysis pipelines, such as code repositories, and for annotating derived data and insights. Applying the FAIR principles to algorithms and analysis pipelines, as well as datasets, is an excellent way of sharing knowledge and leveraging expertise in an organization.
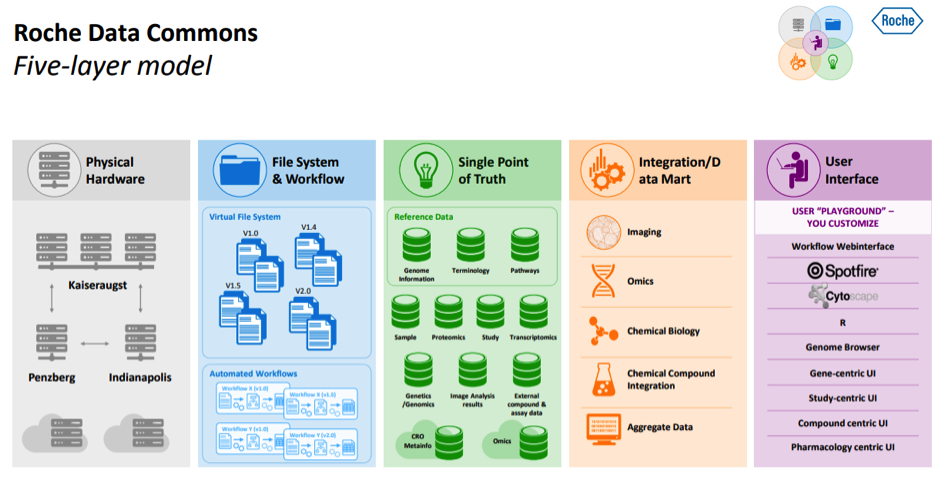
We are currently implementing a ‘Data Commons’ architecture framework to facilitate data management, integration, ‘FAIRification’, and to enable analysts of different types to leverage fully the data, as well as insights and analyses from their colleagues. Frameworks like this are essential in a large R&D enterprise, utilising complex high-dimensional data (e.g. genomics, imaging, digital monitoring), requiring federation of data and/or analyses, robust single-point-of-truth or master data management, access control, etc. In this regard, we are in our second generation architecture for our platform supporting disease understanding. My colleague, Jan Kuentzer, presented an excellent overview at the PRISME Forum last year and the slides are available if people would like to learn more (Roche Data Commons).
Q3. How do you judge the quality of data, before and after you have done data integration?
Bryn Roberts: This question of data quality is even more complicated than it may first appear. Although there are some more elaborate models out there, conceptualising data quality in two broad perspectives may help.
Firstly, what we might call prescriptive quality, where we can test data against pre-determined standards such as vocabularies, ontologies, allowed values or ranges, counts, etc. This is an obvious step in data quality assessment and can be automated to a large degree, including in database schema and constraints. A very challenging aspect of prescriptive quality is judging the upstream processes involved in data collection and pre-processing. For example, determining: if analytical data have been associated with the correct samples, if a manual entry was correctly read and typed, if data from a collaborator have been falsified. The probability of quality issues such as these can be reduced through robust protocols, in-process QA steps, automation, and algorithms to detect systematic anomalies, etc. In the standard data quality models, we might consider prescriptive quality as covering dimensions such as accuracy, integrity, completeness, conformity, consistency and validity.
Secondly, what we might call the interpretive quality perspective, relating to the way the data will be interpreted and used for decision making. For example, the smoking status of patients with lung diseases may be recorded simply as: current, former or never. Despite the data meeting the prescribed standards, being accurate, complete and conforming to the model, they may not be of sufficient quality to address the complexities of the biology underlying the diseases, where one might need information describing the number of cigarettes smoked per day and the time since the individual smoked their last cigarette.
Similarly, when working with derived data from an algorithm, one may need to understand the training set and boundaries of the model to understand how far the derived data can be interpreted for specific input conditions. One can address some of these issues with meta-data describing how data were generated in lab, clinic or silico.
Q4. What are the criteria you use to select the data to be integrated?
Bryn Roberts: Certainly the quality aspects above play a key role. We have, for example, discarded historical laboratory results when, after careful consideration, we decided that the meta-data (lab protocols, association with target information, etc.) were insufficient for anyone to make meaningful use of them. Data derived from old technologies, despite being valuable at some point in the past, may have been superseded or may not meet today’s requirements, so will have lower priority for integration, although may still be archived for specialist reference. Relevance is another critical factor – we prioritise the integration of data relating to our current molecules or disease targets, and data that we deem to have the most valuable content.
Q5. Is there a risk that data integration introduces unwanted noise or bias? If yes, how do you cope with that?
Bryn Roberts: I’m not too concerned about these aspects when the above architectures and principles are applied. There is clearly a risk of bias when the integrated landscape is incomplete, so understanding what you have, and what you don’t, when searching is important. Storing only aggregated or derived data can be risky, as aggregation can mask properties such as skewness and outliers, and there are obviously benefits in having the ability to access and re-analyse upstream and raw data, as models and algorithms improve or an analyst has a specific use-case. Integration, if performed well, should not introduce additional noise, although noise reduction may potentially mask signals in data when they are aggregated or transformed in other ways.
I often hear people talking about Data Lakes and it certainly seems to be one of the hype terms of the last couple of years. This approach to data ‘integration’ does concern me if not implemented thoughtfully, especially for the complex scientific and clinical data used in R&D. Given that the Big Data stack allows for data to be poured into the metaphorical ‘Lake’ with a very low cost of entry, it is tempting to throw everything in, getting caught up with KPIs such as volume captured, with little thought to the backend use-cases and costs incurred when utilising the data. I also wouldn’t advocate the opposite extreme of RDBMS-only data Warehousing, where the front-end costs and timelines escalate to unreasonable levels and the models struggle to incorporate new data types. There is a pragmatic middle-ground, where up-front work on the majority of data has a positive return on investment, but challenging data are not excluded from the integration. This complementary Warehouse+Lake approach allows for continuous refinement, based on ongoing use of the data, to maximize value over the longer-term.
Q6. What specific data analytics techniques are most effective in pharma R&D?
Bryn Roberts: We have so many data types and use-cases, spanning chemistry, biology, clinic, business, etc. that we apply almost every analytic technique you can think of. Classical statistical methods and visual analytics have broad application, as do modelling and simulation. The latter being used extensively in areas from molecular simulations and computational chemistry to genotype-phenotype associations, pharmacokinetics and epidemiology. We are increasingly using Artificial Intelligence (AI), Machine Learning and Deep Learning, in applications such as image analysis, large scale clinico-genomic analysis, phenotypic profiling and analysis of high dimensional time-series data.
Q7. What are your current main projects in the so called “Precision Medicine”?
Bryn Roberts: In Roche we tend to use the term Personalised Healthcare rather than Precision Medicine, since we have both Pharmaceuticals and Diagnostics divisions. However, the intention is similar in that we want to identify which treatments and other interventions will be effective and safe for which patients, based on profiling, which may include genetics, genomics, proteomics, imaging, etc. We have many initiatives ongoing in research, development and for established products. Developing a deeper understanding how mutational and immunological status of tumours influences response to targeted therapeutics, immunotherapies and combinations is one example. Forward and reverse translation in such examples is critical, as we design clinical trials and select participants then, in turn, inform new research initiatives based on data fed back from the clinic. We have made considerable headway in this space thanks to progress in genomic analysis and quantitative digital pathology, supported by collaborations across the Roche Group, including organizations such as Tissue Diagnostics, Foundation Medicine and Flatiron.
Another example is in ophthalmology, where we are trying to identify biomarkers that predict disease progression and drug response to enable appropriate treatment selection, including prophylaxis.
A third quite different example is our application of mobile and sensor technology to monitor symptoms, disease progression and treatment response – the so called “Digital Biomarkers”. We have our most advanced programmes in Multiple Sclerosis (MS) and Parkinson’s Disease (PD), with several more in development. Using these tools, a longitudinal real-world profile is built that, in these complex syndromes, helps us to identify signals and changes in symptoms or general living factors, which may have several potential benefits. In clinical trials we hope to generate more sensitive and objective endpoints with high clinical relevance, with the potential to support smaller and shorter studies, and possibly validate targets in earlier studies that might otherwise be overlooked. In the general healthcare setting, tools like these may have great value for patients, physicians and healthcare systems if they are used to inform tailored treatment regimens and enable supportive interventions such as the timing of home visits or provision of walking aids to reduce falls. For those interested in learning more about our work in MS there is more information available online about our Floodlight Open programme.
Q8. You have been working on trying to detect Parkinson disease. What is your experience of using Deep Learning of that purpose?
Bryn Roberts: The data we collect with the digital biomarker apps fall into two classes: 1) active test data, where the subject performs specific tasks on a daily basis, and 2) continuous passive monitoring data, where the subject carries the device (e.g. smartphone) with them as they go about their daily lives and sensors, such as accelerometers and gyrometers, collect data continuously. These latter data form complex time series, with acceleration and rotation being measured in 3 axes each, many times per second. From these data, we build a picture of the individual’s daily activities and performance, which is ultimately what we hope to improve for patients with our new therapies. We apply Deep Learning to do this activity-performance classification, or Human Activity Recognition (HAR), using deep artificial neural networks that have been trained using well-annotated datasets. Since the data are time-series, the network utilises Long Short-Term Memory (LSTM) layers to provide recurrence, hence the name “Recurrent Neural Network” or RNN. Examples of what we might study here are how well a patient with PD is able to stand up from a chair or climb a staircase.
The advantages of using digital, mobile and AI technologies in this way, compared to infrequent in-clinic assessments, is that they are highly objective and sensitive, have the possibility to detect symptom fluctuations day-to-day, they are performed in the real-world setting providing increased relevance, they have a relatively low burden for patients, and data can be assessed by the patient and/or physician in near real-time so they become better informed and empowered.
Extending the application beyond clinical trials, disease monitoring and management, these technologies have the potential, in some disorders, to deliver solutions with a direct beneficial effect that can be measured objectively through improved outcomes. Thus, this work is also laying the foundation for advances in digital therapeutics, or “digiceuticals”, where we’ve seen a huge increase in interest, and the first regulatory approvals, over the last year or so.
With great power comes great responsibility, so we work closely with the participants and regulators to ensure that data protection and privacy are upheld to the highest standards and that participants are fully informed and consent.
As we have developed the platform over the past few years, the establishment of robust end-to-end data processes and the building of trust has run side-by-side with the technology innovation.
Q9. What kind of public data did you use for training your models?
Bryn Roberts: The Human Activity Recognition (HAR) model was initially trained using two independent public datasets of everyday activity from normal individuals. The first from Stisen et al. (“Smart devices are different: Assessing and mitigating mobile sensing heterogeneities for activity recognition”, Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, 2015.) and the second from Weiss et al. (“The impact of personalization on smartphone-based activity recognition”, AAAI Workshop on Activity Context Representation: Techniques and Languages, 2012.). From these data, 90% were used to train the model and 10% for model validation.
Q10. What results did you obtain so far?
Bryn Roberts: In passive monitoring of gait and mobility we have published, for example, significant differences between healthy subjects and PD patients in parameters such as sitting-to-standing transitions, turning speed when walking and in overall gait parameters. In the active test panel, we have demonstrated correlation with the current standard rating scale for PD (MDS-UPDRS) in symptom areas such as tremor, dexterity, balance and postural stability. However, in some measurements (e.g. rest tremor) the digital biomarker appears to be more sensitive at detecting low-intensity symptoms than the in-clinic rating, and corresponds better with patients’ self-reported data.
For more information, see, for example: “Evaluation of Smartphone-Based Testing to Generate Exploratory Outcome Measures in a Phase 1 Parkinson’s Disease Clinical Trial”, Lipsmeier et al., Movement Disorders, 2018.
Q11. Are there any other technological advances on the horizon that you are excited about?
Bryn Roberts: There’s a lot of activity in the healthcare and pharma sector at the moment around blockchain. Some of the use-cases have potential interest to us in R&D, such as secure sharing of genomic and medical data.
I don’t think blockchain is a requirement to do this effectively but may be an enabler, especially if it gains broad adoption.
I’m intrigued by the general trend towards empowering individuals to share their data in a secure and controlled environment. Democratisation of data in this way has to be the future. Imagine what we will be able to do in decades to come, when individuals have access to their complete healthcare records in electronic form, paired with high quality data from genomics, epigenetics, microbiome, imaging, activity and lifestyle profiles, etc., supported by a platform that enables individuals to share all or parts of their data with partners of their choice, for purposes they care about, in return for services they value – very exciting!
This vision, and even the large datasets available today, are driving a paradigm shift in data management and compute for us. The need to federate, both data and compute, across multiple locations and organisations is a change from the recent past, when we could internalise all the data of interest into our own data centers. Cloud, Hadoop, containers and other technologies that support federation are maturing quickly and are a great enabler to big data and advanced analytics in R&D.
What I’m particularly excited about just now is the potential of universal quantum computing (QC). Progress made over the last couple of years gives us more confidence that a fault-tolerant universal quantum computer could become a reality, at a useful scale, in the coming years. We’ve begun to invest time, and explore collaborations, in this field. Initially, we want to understand where and how we could apply QC to yield meaningful value in our space. Quantum mechanics and molecular dynamics simulation are obvious targets, however, there are other potential applications in areas such as Machine Learning.
I guess the big impacts for us will follow “quantum inimitability” (to borrow a term from Simon Benjamin from Oxford) in our use-cases, possibly in the 5-15 year timeframe, so this is a rather longer-term endeavour.
————————————————–

Dr Bryn Roberts
Bryn gained his BSc and PhD in pharmacology from the University of Bristol, UK. Following post-doctoral work in neuropharmacology, he joined Organon as Senior Scientist in 1996. A number of roles followed with Zeneca and AstraZeneca, including team and project leader roles in high throughput screening and research informatics. In 2004 he became head of Discovery Informatics at the AstraZeneca sites in Cheshire, UK.
Bryn joined Roche in Basel in 2006, and his role as Global Head of Informatics was expanded in 2014 to Global Head of Operations for Pharma Research and Early Development. He is also the Centre Head for the Roche Innovation Centre Basel.
Beyond Roche, Bryn is a Visiting Fellow at the University of Oxford, where he is a member of the External Advisory Board of the Dept. of Statistics and the Scientific Management Committee for the Systems Approaches to Biomedical Sciences Centre for Doctoral Training. He is a member of the Advisory Board to the Pistoia Alliance. Bryn was recognized in the Fierce Biotech IT list of Top 10 Biotech Techies 2013 and in the Top 50 Big Data Influencers in Precision Medicine by the Big Data Leaders Forum in 2016.
Resources
– How artificial intelligence is changing drug discovery. Nature, 30 May 2018
Related Posts
– AI, Mental Health & Youper. Q&A with Jose Hamilton Vargas. ODBMS.org, August 23, 2018
– On Precision Medicine. Q&A with Todd Winey. ODBMS.org, February 14, 2018
Follow us on Twitter: @odbmsorg
##
On Using Blockchain and NoSQL at the German Federal Printing Office. Interview with Ilya Komarov
“Bundesdruckerei has transformed itself from a traditional manufacturer of official documents such as passports and ID cards to one of the leading companies for security solutions, also in the digital sector.”–Ilya Komarov
I have interviewed Ilya Komarov, researcher at the German Federal Printing Office (“Bundesdruckerei“). We talked about how they use Blockchain and a NoSQL database – Cortex -for their identity and rights management system, FIDES.
RVZ
Q1. The “Bundesdruckerei” (Federal Printing Office), a German public company, is since 1951, the manufacturer of banknotes, stamps, identity cards, passports, visas, driving licences, and vehicle registration certificates. What do you now?
Ilya Komarov: Bundesdruckerei has transformed itself from a traditional manufacturer of official documents such as passports and ID cards to one of the leading companies for security solutions, also in the digital sector. For the development of further, safety-relevant products, the innovation department now relies on the CortexDB platform.
Q2. Do you use blockchain technology? If yes, for what?
Ilya Komarov: Although Bundesdruckerei’s ID-Chain technology is based on the data integrity principle of a blockchain, it is adapted to the requirements of powerful and secure identity and rights management.
The difference to blockchain, however, is the bi-directional linking of the blocks as well as the generation of many individual chains rather than a single, increasingly longer chain. Unlike with blockchain, the chain links are connected to each other in both directions, i.e. a block hence knows the next block as well as its predecessor block.
This chain structure makes it possible to quickly check the integrity of the blocks and that of their respective neighbours in both directions and in detail, right down to the very last link. Functions from quantum-mechanical analytics rather than hash values are used as a security mechanism. This mechanism begins with the generation of an atomic wave function for each block in the chain. The blocks can then be idealized as atoms and described in quantum-mechanical terms.
In analogy to nature, these atoms can then join up with other atoms (blocks) to form molecules (blockchains).
By applying these principles, two blocks form unique molecular connections that are used as a security mechanism for the blocks and for the chain as a whole. The ID-Chains now offer the security of linked data structures combined with a high level of flexibility and performance.
Q3. What is Bundesdruckerei using CortexDB for?
Ilya Komarov: We are running the FIDES development project in cooperation with Cortex AG.
The user-centered identity and rights management system is based on a modified blockchain. It integrates Bundesdruckerei’s security functions into the core of the database. People, machines, processes and objects can be integrated into administration and companies of all industries. Legal requirements, such as the European Data Protection Regulation (GDPR), are implemented technologically.
The FIDES development project aims to develop an identity and rights management system in which the user alone has control over his data. Each authorization is stored in the form of a digital authorization blockchain and is inseparably linked to the identity of the data owner. Each blockchain represents a unique link between an authorization, the owner of the authorization, and a user identity. At any time it is possible to determine who accessed which data with which authorizations and when and where these authorizations come from.
Bundesdruckerei is using CortexDB as part of its revolutionary identity and rights management system FIDES where the user alone determines what happens with their data. This user-centric identity management system is based on derived blockchain and cognitive database technologies.
Identities and rights are managed in FIDES in the form of digital rights chains, so-called ID-Chains. An individual ID-Chain is created for each right owned by an identity. This means that the system is made up of millions of chains that have to be searched in a split second.
Within the scope of a development partnership, the NoSQL database from Cortex AG has been specially optimized to meet the requirements of FIDES.
Thanks to smart data normalization, this data can be accessed as fast as lightning without the need for time-consuming searches. As a supplier of high-security solutions, Bundesdruckerei was involved in the development process and integrated the security functions directly into the core of the database, for instance, for encryption and ID-Chain creation and validation.
Q4. What are the typical problems you encounter in ID Management Systems (IDMS) based on encrypted block chain technology?
Ilya Komarov: Blockchain is opening up a vast range of new possibilities, however, due to its technical limits it is not suitable for every situation. The ID-Chains take the principle of linked blocks and adapt it to the requirements of powerful and secure identity and rights management.
The biggest difference to the blockchain is the generation of many individual ID-Chains rather than one ever-longer chain. Each of these is a separate chain that can be easily saved or discontinued. This means, for instance, that individual chains can be marked as invalid, making it technically possible to implement the right to be forgotten. This is neither possible nor aimed for with conventional blockchains.
Q5. What are the lessons learned so far?
Ilya Komarov: FIDES is currently being used in proof-of-concept projects by our customers. The scope of application is wide: from small private businesses to large groups and public authorities.
Problem trials conducted at our customers show that many of the problems are related to identification and the possession of data.
As soon as the data owner has full control over the data, many privacy problems will become irrelevant. This is the case, for instance, with patient data in the field of healthcare or personal data in dealings with public authorities.
Access control systems as well as IoT devices also require secure administration of identity and rights.
Thanks to the flexibility of CortexDB and ID-Chains, FIDES has what it takes to solve these problems.
—————————-

Ilya Komarov
Ilya Komarov has been working at Bundesdruckerei’s research and development departments since 2008. His research subjects include identity management, security systems and big data. In 2017, he started to work on developing new blockchain technologies for the secure management of identities and authorisations.
Mr. Komarov received his degree in Computer Science at Humboldt University in Berlin.
Resources
– Bundesdruckerei under new leadership. Dr. Stefan Hofschen new CEO 6 February 2018
Related Posts
– The architecture of the CortexDB in comparison. Thomas Kalippke, Medium, June 13, 2018
– Analysing 1.4 Billion dataset with CortexDB. Q&A with Thomas Kalippke. ODBMS.org, 11 MAY, 2018
Follow us on Twitter: @odbmsorg
##
“I think the biggest challenge is that in the rail business we have a very large set of old and country specific regulations that date back many decades. These regulations are meant to protect passengers, but some of them are not anymore fitting to the modern capabilities of technology and instead drive cost and slow innovation down dramatically.” –Gerhard Kress
Artificial intelligence acts as an enabler for many innovations in the rail industry.
In this interview, I have spoken with Gerhard Kress, who is heading Data Services globally for the Rail business, and is responsible for the Railigent ® solution at Siemens. We discussed innovation and the use of AI and Data-driven technologies in the transport sector, and specifically how the Siemens´ Railigent solution is implemented.
Railigent is cloud based, designed to help rail operators and rail asset owners, to improve fleet availability and improve operations, for example by enabling intelligent data gathering, monitoring, and analysis for prescriptive maintenance in the rail transport industry.
This interview is conducted in the context of a new EU funded project, called (LeMO (“Leveraging Big Data to Manage Transport Operations“). The LeMO project studies and analyses big data in the European transport domain, with focus to five transport dimensions: mode, sector, technology, policy and evaluation.
LeMO conducts a series of case studies, in order to provide recommendations on the prerequisites of effective big data implementation in the transport field. The LeMO project has selected Siemens´ Railigent as one of the main seven case studies in transport in Europe.
RVZ
Q1. What is your role at Siemens?
Gerhard Kress: At Siemens, I am heading Data Services globally for the Rail business. This means that I am heading all MindSphere Aplication Centers that focus on rail topics from the United States to Australia.
Q2. What are in your opinion the main challenges, barriers and limitations that transport researchers, engineers and policy makers today face as they work to build efficient, safe, and sustainable transportation systems?
Gerhard Kress: I think the biggest challenge is that in the rail business we have a very large set of old and country specific regulations that date back many decades. These regulations are meant to protect passengers, but some of them are not anymore fitting to the modern capabilities of technology and instead drive cost and slow innovation down dramatically.
Q3. You manage all the data analytics centers of Siemens for rail transport globally. What are the main challenges you face and how you solve them?
Gerhard Kress: There are a number of key challenges. First challenge is to develop offerings that are globally relevant for our customers. The rail industry is very different across the continents and with country specific legislation there is a very diverse landscape of requirements to address. Another important challenge is to manage the network of data analytics centers in such a way that they on leverage local specifics but at the same time learn from each other and act as a true global network.
The way we have addressed these issues is to set up in each MindSphere Application Center small agile teams that work very closely with customers to understand their issues and understand how they create tangible value. These teams create customer specific solutions, but use existing reusable analytics elements to build these solutions. In order to make this happen globally, we have created a simple set of tools and processes and have also centralized the product development function across all of the data analytics centers.
Q4. You are responsible for the Railigent Asset Management Solution at Siemens. What is it?
Gerhard Kress: Railigent is our solution to help customers manage their rail assets smarter and get more return from them. Therefore Railigent contains a cloud based platform layer to support ingest and storage of large and diverse data sets, high end data analytics and applications. This layer is open, both for customers and partners.
On top of this layer, Railigent provides a large set of applications for monitoring and analyzing rail assets. Also here applications and components can be provided by partners or customers. Target is to help customers improve fleet availability, maintenance and improve operations.
When I am talking about rail assets, this implies rolling stock / vehicles, signaling systems including field devices and also rail infrastructure.
Q5. Who are the customers for Railigent, and what benefits do they have in using Railigent?
Gerhard Kress: Customers for Railigent are for example rail operators and rail asset owners. The key benefits for them are that they can improve asset and system availability and therefore offer more services with the same fleet size. Railigent also helps these customers reduce lifecycle costs for their assets and improve their operations.
Q6. What are the main technological components of Railigent?
Gerhard Kress: Basically Railigent builds on technologies from Mindsphere, enlarged with rail specific elements like data models / semantics, rail specific format translators and of course our applications and data analytics models.
The foundation is a data lake in the cloud (AWS) in which we store the data in a loosely coupled format and create the use case specific structures on read.
Data gets ingested in batch or stream, depending on the source and during the data ingest we already apply the first analytics models to validate and augment the data.
For every step in the data lifecycle we use active notifications to move the data to the next stage and as much as it is possible we rely on platform services from AWS to build the applications.
Our applications consist out of micro services which we bundle in a common UI framework. And we have deployed a full CI/CD pipeline based on Jenkins.
Data analytics happens either in sand boxes, when the model is still in development or in the full platform.
We use mostly Python and pySpark, but are also using other technologies when needed (e.g. deep learning driven approaches).
Q7. MindSphere is Siemens´ cloud-based, open IoT operating system for the Industrial Internet of Things. What specific functionalities of MindSphere did you use when implementing Railigent and why?
Gerhard Kress: MindSphere and Railigent share a lot of core functions, especially in the way how the data connectivity and data handling is implemented and how IT security of the system is ensured. The key reason to use the same technology is that it is essential for our customers to have a secure and reliable platform. And the key differentiator we provide is generating the insight. Therefore the pure platform functionalities are not differentiating and therefore there is no rational for developing them all over again.
Q8. What other technologies did you use for implementing Railigent?
Gerhard Kress: The key elements of Railigent are not its platform components, but the reusable analytics elements as well as the rail specific applications.
For the analytics side, Railigent uses all types of analytics libraries, but also mathematical approaches newly developed by Siemens. Especially for the industrial data area, new mathematical approaches are often required and such approaches were then integrated into Railigent.
Q9. The foundation of Railigent is a data lake in the cloud (AWS) in which you store the data in a loosely coupled format and create the use case specific structures on read. Can you elaborate on how you handle batch and/ or stream of data?
Gerhard Kress: Railigent has to handle a large number of data formats, like diagnostic messages, sensor data, work orders, spare part movements, images, etc.
We receive data in all sorts of legacy formats, most of them are batch formats. These files we decrypt and then annotate them with specific information to enable us to quickly find the data back again and also to ensure it can be attributed to the right fleet and the right customer. Then we create a generic JSON file which we store in our data lake.
For stream data we use mostly MQTT as transfer protocol and then create the same JSON file format to persist this data in our data lake.
Q10. What data analytics do you perform?
Gerhard Kress: Most of the data analytics in Railigent is based on machine learning or deep learning. This can be classifiers to identify components which are already showing distress, or it can be prediction algorithms to identify the remaining useful life of a component. Most of the machine learning is supervised learning, but there are aso cases where unsupervised learning techniques are implemented.
Q11. Is there a difference in performing analytics when the model is still in development or in the full platform?
Gerhard Kress: We develop models usually in a type of sandbox environment so that we can quickly iterate the model on real data, validate the results and improve the model further. Once a certain quality is reached, we transfer the model into the operational environment of Railigent. This requires us to be much more formal in the deployment so that results are correct and the performance is predictable. And, of course, the model then needs to be integrated into the production data pipeline in order to be available 24/7
Q12. What are the lessons learned so far in using Railigent?
Gerhard Kress: So far we have quite a few lessons learnt from Railigent deployments and most of them deal with the value generation for our customers.
We have learned that we needed to be closer to our customers in creating applications. For this we have set up an agile “Accelerator” team, developing the first insights with the customer in the first week and making this all accessible through a first web application. These teams are often collocated with the customers so that we can jointly create the right solution for the customer problem.
In our customer activities, we have learned to see the customer value as the main driver of our activities. We try now to quickly deliver a first application which we then improve later, but we also focus on making the insights actionable so that the customer can immediately start implementing and gaining the promised value.
With regards to handling data, we have learned that in a complex big data world with many different types of data elements, we have to resort to a schema on read approach as an integrated and overarching logical data model would not be feasible.
These learnings we have implemented already and we can see the value which the changes helped create for our customers.
Q13. What is the roadmap ahead for Railigent?
Gerhard Kress: Railigent is just going to be released in Version 2.0 in July and we are aiming for Version 3 in December. On the roadmap we do not only have customer facing application features for rolling stock and signaling, but also technical building blocks, analytics components as well as platform topics. Our focus in V3 is on features to better integrate partners, capabilities to allow partners and customers easier access to analytics elements inside Railigent and handling of realtime data. Additionally we will improve the operations topics and deploy a new type of highly scalable and overarching analytical capabilities to be used by any application inside Railigent.
Our target is to become even more relevant for our customers and provide tangible value.
———————————————-

Gerhard Kreß is responsible for Data services in the Siemens Mobility GmbH, aiming to build up new customer offerings enabled by data analytics for both rail vehicles and rail infrastructure.
Before that he was in Siemens Corporate Technology responsible for implementing the corporate big data initiative “Smart Data to Business” and he worked for 3 years in Siemens Corporate Strategy in the corporate program to refine the IT strategy for the Siemens businesses. There he was also responsible for setting up the Siemens big data initiative.
Prior to his work in Corporate Strategy he spent 8 years working in Siemens IT Solutions and Services (SIS), managing systems and technologies for the global service desks and in the project management of major IT outsourcing projects.
Gerhard Kreß started his professional career in McKinsey & Company, where he focused on growth initiatives and high tech industries.
He holds a German diploma in Theoretical Physics and a Master of Arts in International Relations and European Studies.
During his studies, Gerhard Kreß worked for the student NGO “AEGEE-Europe” where he was President and Member of the European board of the organisation.
Resources
– Railigent® – the application suite to manage your assets smarter – mov, (Link to YouTube Video), May 13, 2018
– Heading for Data-Driven Rail Systems, Siemens, 15 December 2017
– UNDERSTANDING AND MAPPING BIG DATA In Transport Sector, LeMo Project Deliverable D1.1, May 13, 2018 (Link to .PDF 78 pages)
– BIG DATA POLICIES In Transportation, LeMo Project Deliverable D1.2, May 31, 2018 (Link to .PDF 60 pages)
– BIG DATA METHODOLOGIES, TOOLS AND INFRASTRUCTURES in Transportation, LeMo Project Deliverable D1.3, July 16, 2018 (Link to .PDF 50 pages)
– LeMO Project Web site (LINK). The LeMO project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement no. 770038.
Related Posts
– Generating Transport Data, by Filipe Teixeira, ODBMS.org,May 16, 2018
– On Smart Cities and Mobility. Q&A with Praveen Subramani, ODBMS.org, May 28, 2018
– On Data and Transportation. Q&A with Carlo Ratti, ODBMS.org, Apr. 11, 2018
– On Logistics and 3D printing. Q&A with Alan P. Amling, Vice President, UPS Corporate Strategy, ODBMS.org, Apr, 2018
Follow us on Twitter: @odbmsorg
##
“We’ve corrected a major human resource burden that has led to an exponential decrease in the amount of developer-operations staff hours required each month to keep our activity feed running. This means they can focus on other areas of our infrastructure that need attention, versus spending time frustratingly micro-managing the activity infrastructure. ” –David Fox
I have interviewed David Fox. David is a Software Engineer at Adobe, responsible for backend infrastructure and performance of Behance – a social network for creatives, serving over 10 million members. Behance is owned by Adobe.
RVZ
Q1. Who is using Behance and for what? How many users do you have, and what data volume and data types do you handle?
David Fox: Behance is the leading online platform to showcase and discover creative work. Every single day, hundreds of thousands of creative individuals update and publish new projects to the Behance platform allowing for advanced collaboration and an efficient means to solicit helpful feedback on both final work and ‘works in progress.’
Not only does Behance offer an outlet for peer-to-peer sharing among creatives, it’s a top destination for companies looking to hire creative talent on a global scale. With over 10 million members, our ‘activity feed’ infrastructure serves millions of feed loads daily.
Q2. What specific data requirements do you have from your users?
David Fox: Our users expect the ability to access current and past projects within Behance that’s both relevant to their core interest areas while also offering discovery tools/functionality. The ‘Activity Feed Feature’ allows users to follow their favorite creatives and curate galleries based on preferences. When a user follows a creative, they receive alerts and an updated feed whenever that creative logs an activity within Behance, e.g. when they ‘appreciate’ a project, publish a project, comment on a project. Users can also follow pre-curated galleries, selected by the Behance curation team, which highlight a creative theme, e.g. graphic design, photography, illustration.
Q3. You have implemented an activity feed for many years. What challenges did you have with the previous implementation?
David Fox: Our previous implementation of ‘Activity Feed’ was built with Cassandra. It was designed for optimized ‘reads’ (when we showed a user their activity feed), but consequently, it was very storage/write-heavy.
We needed 48 large Cassandra instances to power the feature, and even with those, there were still many limitations and bottlenecks on the system. We had to devote a large amount of app resources to populate Cassandra with activity feed data. For every action a user took on our app, we would use a “fanout” method to populate the activity feed of every user that followed them with the new activity item. For users who were followed by thousands of people, resource utilization skyrocketed every time they took an action. Our application worker processes that processed those items would experience delays in their work because of all the work they needed to do to populate the activity feeds in Cassandra.
We also had a lot of challenges maintaining our Cassandra cluster, which led to us having to devote a significant amount of ops/developer time to supporting the cluster. With our schema format, we didn’t have an efficient way to delete feed items from our database, so the disk usage began to add up quickly on each node. When disk usage became high, we would have to perform maintenance tasks to stabilize the cluster. The rigid schema structure also meant we couldn’t easily make any improvements to our activity feed feature, and we were just working to keep it running with little hope of improving it.
Q4. What are the goals you set for the new implementation of the activity feed? How does the activity feed relate to the rest of the data platform?
David Fox: We had several goals for our new activity feed implementation.
- Ensure the new infrastructure significantly reduced human-maintenance costs and required minimal effort and resources to keep running.
- Reduce the complexity of the system as a whole.
- Significantly improve the performance of writes while keeping reads fast.
- Increase the flexibility of the system, in turn making it easier to add new features.
- Reduce data storage size.
Q5. Can you share with us some details of the new implementation?
David Fox: Our new activity feed implementation, built on top of Neo4j, uses a simple graph model where we store relationships between users and the entities they follow. We then store simple “action” relationships that represent a user or curated gallery taking an action on a project (ex. commenting, publishing, appreciating, etc.). This data model produces very little repeating data so data maintenance is simple for our application layer, doesn’t use a lot of resources, and provides good flexibility on how we can query the data.
Q6. Why was removing activity items when you unfollowed a user “impossible” with the previous implementation? How is it done now? What about scalability?
David Fox: In our previous implementation, our Cassandra schema didn’t allow for us to efficiently delete data at any scale since it was highly optimized for reads, and there was significant data repetition. So, when a user unfollowed another user, since their activity feed was pre-written to Cassandra in-full, they would still see items from users they unfollowed. Now, we simply delete the “follows” relationship from the user to the person they unfollowed, instantly reflecting the change in their feed. This instant change is possible since we don’t store any data about individual activity feeds, and instead, only store data modeling on who users follow and actions taken on projects.
Q7. In the previous implementation you could only “backfill” 30 items per category during on boarding. Why was this a problem? How is it done now?
David Fox: This limitation was a significant struggle for us. When a user creates an account with Behance, they select one or more curated categories they want to follow. At that point, with our old implementation, we would have to backfill their feed with activity items since all the items we could show them needed to be stored in Cassandra – one row for each project in their feed. So, when a user signed up, they would need to wait the amount of time it took for us to fill Cassandra with activity items for the curated categories they selected. Because of that delay, we minimized the number of projects we backfilled to make sure there wasn’t too long of a delay (only a few seconds) between finishing sign-up and seeing the initial Behance experience. Unfortunately, limiting the backfill to 30 items meant after sign-up, a user could only scroll through 30 x (number of categories selected) items on their feed, and then they’d reach the end.
Now, with our new activity feed implementation, there is no backfill required at all. When a user creates an account and selects the curated categories they want to follow, all we have to do is create the “follows” relationships in Neo4j between the user and the categories, and their feed will instantly be available. Since we store about 1,000 latest items for each curated category in Neo4j, that means that users can now almost instantly see 1,000 x (number of categories selected) items in their feed. That’s a much better initial experience on our application!
Q8. How did you implement the ability to add new features like “newest projects from your network” ?
David Fox: The flexibility of the graph data model allowed us to easily add this new activity view to the activity feed feature. Instead of having to load a user’s activity based on a pre-existing stored structure, we were able to simply query by action type in Neo4j to create a specific view of the activity feed, analyzing only “published project” actions instead of all our usual activity actions.
Q9. Why is selectively writing for users with lots of followers no longer needed?
David Fox: Previously, if a user was followed by a significant amount of people, we were unable to share an activity update to the user’s full group of followers due to the ‘fan out’ action for each follower. Now, the number of people following a user has no impact on the time/complexity for creating the action since the same action relationship is shared by all followers of that user – meaning very little repeating data.
Q10. Can you share any numbers around the performance of the new implementation?
David Fox: We’ve seen some significant performance improvements with the new implementation. We’ve been able to cut the time from sign-up to initial activity experience from 1.4 seconds to 400 milliseconds on average. In addition to the speed improvement, users’ initial curated feed is now much more complete.
We’ve seen the most significant improvements in writing activity data. For example, one of our write job processes (when a project was featured in a curated gallery) used to take 12 minutes on average to run and consumed significant application resources. Now, on average, that write operation takes 106 milliseconds.
Q11. What about COGS, Storage Costs and Complexity?
David Fox: Our Neo4j activity implementation has led to a great decrease in complexity, storage, and infrastructure costs. Our full dataset size is now around 40 GB, down from 50 TB of data that we had stored in Cassandra. We’re able to power our entire activity feed infrastructure using a cluster of 3 Neo4j instances, down from 48 Cassandra instances of pretty much equal specs. That has also led to reduced infrastructure costs. Most importantly, it’s been a breeze for our operations staff to manage since the architecture is simple and lean.
Q12. What is the road map ahead for data projects at Behance?
David Fox: We want to continue to take advantage of our new, flexible graph infrastructure to improve our activity feed feature and make it more useful. We recently built “newest projects from your network” view for activity and we will be launching it soon. This feature is a great example of our ability to move quickly and nimbly, and we’ll continue to add more compelling features to our activity experience moving forward.
Just as important as new features, we’ve corrected a major human resource burden that has led to an exponential decrease in the amount of developer-operations staff hours required each month to keep our activity feed running. This means they can focus on other areas of our infrastructure that need attention, versus spending time frustratingly micro-managing the activity infrastructure.
———————————-

David Fox is an application developer/data engineer specializing in the development of high-performance backend systems and working with a large variety of databases alongside massive datasets. He is a Software Engineer at Adobe, responsible for backend infrastructure and performance of Behance – the premier social network for creatives, serving over 10 million members.
Resources
GRAPH DATA STORES – Free Downloads for:
Articles, Papers, Presentations
Related Posts
– On RDBMS, NoSQL and NewSQL databases. Interview with John Ryan , ODBMS Industry Watch, March 9, 2018
– Identity Graph Analysis at Scale. Interview with Niels Meersschaert, ODBMS Industry Watch, May 9, 2017
Follow us on Twitter: @odbmsorg
##
“We made it a point to hire really smart, visionary people and then let them do their work.
I wanted to delegate and let people be in charge of things. My own decision-making process was to decide who got to decide. To make decisions, you have to first outline the problem, and if you hire really great people, they’re going to know more about the problem they’re dealing with than you ever will.”–Scott McNealy
I have interviewed Scott McNealy. Scott is a Silicon Valley pioneer, most famous for co-founding Sun Microsystems in 1982. We talked about Innovation, AI, Big Data, Redis, Curriki and Wayin.
RVZ
Q1. You co-Founded Sun Microsystems in 1982, and served as CEO and Chairman of the Board for 22 years. What are the main lessons learned in all these years?
Scott McNealy: Companies and technologies can go down as fast as they go up. Smart people make leading easier. Managerial courage is hard to find. Tech has the shelf life of a banana. Being CEO is a young person’s game.
Luck helps. Data is the new oil. It used to be Microsoft and Apple, but now it’s Google, Facebook and Amazon. As things continue to evolve, it’ll be someone else tomorrow. Have lunch or be lunch, or get tenure and do lunch.
Q2. You piloted the company from startup to legendary Silicon Valley giant. What were the main reasons for this success?
Scott McNealy: We made it a point to hire really smart, visionary people and then let them do their work.
I wanted to delegate and let people be in charge of things. My own decision-making process was to decide who got to decide. To make decisions, you have to first outline the problem, and if you hire really great people, they’re going to know more about the problem they’re dealing with than you ever will.
Then, once the parameters of each problem were clear, we would make decisions and take decisive action quickly. There was no time to grind out and wait until answers became obvious because competition wasn’t going to wait. I put a lot of pressure on my managers to be quick decision makers and let them know that it was okay to fail if they failed fast, applied that to their next endeavor.
Q3. What are in your opinion the top 3 criteria for successful innovation?
Scott McNealy: Quality of the people with whom you hire; participative but not consensus management, listening to both customers and engineers.
Q4. In your opinion how can we create a culture that supports and sustains innovation?
Scott McNealy: You have to have a common purpose that everyone can rally around. At Sun, we always had a cause and a very specific set of enemies, and while we drew from a diverse array of backgrounds, ideas and cultures, we always maintained that emphasis. Diversity of race, culture, gender was not as important as having a diversity of backgrounds and perspectives while most importantly having a commonality of purpose. Fostering that commonality of purpose is what really great organizations do and something I am very proud of from my time at Sun.
Q5. What do you think stops/slows down innovation?
Scott McNealy: Innovation and entrepreneurship are inherently risky, so a general climate averse to risk is a definite innovation killer. I’ve spoken in Japan on numerous occasions, and as smart and industrious as the people are, the innovation is lacking solely because of the pervasive cultural aversion to failure. Failure happens. Get over it. Just try to make bets small enough that they won’t bury the company if they fail. The other problem comes when managers are afraid to cannibalize their own products and revenue. If you dont, someone else surely will.
Q6. Do you think becoming an innovator can be taught?
Scott McNealy: Innovation is probably like leadership. It really can’t be taught but it can be identified and allowed to succeed. Not all employees are equally talented. Bill Joy and Andy Bechtolsheim and James Gosling are special people. They had a virtual carte blanche to do what they thought was right. And they were usually right. So making a company innovative is correctly identifying the innovators and letting them do their thing.
Q7. You have been quoted saying “In a world without fences, who needs gates?” Do you really believe that people can’t hide things anymore?
Scott McNealy: People haven’t been able to hide anything for a long time—it’s just coming to light more prominently now. I’ve been saying since the 90’s that privacy is a myth. A lot of people bristled when I said it then, but with all the news around Facebook and Cambridge Analytica, it’s staring them in the face now. The only organization that should terrify you regarding privacy is government. They are the ones that can actually negatively impact your life through IRS audits, student loan grants/ forgiveness, health care choices, judicial decisions, etc. It is truly scary how much the government knows about you and how much they can change your life. You can leave FB but you cant escape the Feds or even the local governments with their regulations and permits, etc.
Q8. Big Data, Machine Learning, AI driven algorithms: How these new technologies will change the world (for the better or the worst)?
Scott McNealy: All these new technologies will drive massive changes in the landscape from a business sense—the gorillas of today are not the gorillas of tomorrow. Of the three, though, big data is the most overarching and still the largest challenge organizations face today. And frankly it is something that will only compound as the years go on.
First and foremost, machine learning and AI driven algorithms are a byproduct of big data, and the more sophisticated those technologies become, the more data, insights and inferences can be made – ultimately resulting in more data. The ability to not only store, but make better use of data, will always be at the center of innovation.
Opening that whole data market to innovation is why we bought MySQL when I was at Sun — it’s a huge opportunity and a necessary step in the evolution of the technology. Now, as data continues to get bigger and the use cases and applications require faster transactions and 99.99% uptime, it’s critical that organizations have the right database for the right time.
At this point, however, web applications and the infinite number of edge and IoT use cases are multiplying by the day and a common theme underlying each of them is speed and reliability. And because of this shifting landscape, the incumbents are not in the best position to drive that innovation. This is why new approaches and open-source friendly solutions such as Redis are so critical.
Q9: Why did you join Redis Labs’ advisory board?
Scott McNealy: I love the management team, the technology, and their desire to use me as a mentor and advisor.
Q10. Curriki: What is the road ahead?
Scott McNealy: Curriki (curricula + Wiki) was founded over 11 years ago with the idea of creating a free and open community for teachers, parents and students where they could go to find, share, and contribute learning resources. It was modeled after the success of the Java Developer Community. At the time this was a completely new and innovative concept for K-12.
Today we are the leaders in this space with close to 15 Million users from 194 countries around the world that have touched over 200 Million students since our inception. We have over 250,000 multi media learning resources and over 1,000 groups of educators collaborating on creating free and open content. Our vision is to build out this high quality content into full K-12 multi media curricula, that can be used in the classroom or self paced. We want it to be real time scored so that students and educators know exactly where they stand and what resources they need to access to improve their outcomes.
Q11. Wayin: What is the road ahead?
Scott McNealy: Wayin has been used by major brands such as Coca Cola, IBM, P&G, and Nordstrom a number of years to create interactive experiences that collect first party data. These experiences have lived on clients owned and earned channels.
Wayin has just released the capability to publish these data collecting experiences inside Google DoubleClick ad units, Snapchat ads, as well as call to actions on Instagram and Facebook ads. Being able to deliver paid media ads, that aren’t just trying to force someone to watch a video or look at an image, but instead deliver an interactive experience, where the brand can collect first party data and marketing optins in return for entering into something like a competition is exciting. It’s changing the relationship of ads being interruptive on digital channels to something participatory with a value exchange. And given the risks brands now have with using third party data for targeting ads, after the Cambridge Analytica fallout and the EU’s enforcement of GDPR, marketers are now all trying to build up their own first party datasets around consumers. So this solution is timely.
———————————

Scott McNealy (@ScottMcNealy)
Co-Founder, Former Chairman of the Board, and CEO, Sun Microsystems, Inc.
Co-Founder, and Board Member, Curriki
Co-Founder, and Executive Chairman of the Board, Wayin
Board Member, San Jose Sharks Sports and Entertainment
Scott McNealy is an outspoken advocate for personal liberty, small government, and free-market competition.
In 1982, he co-Founded Sun Microsystems and served as CEO and Chairman of the Board for 22 years. He piloted the company from startup to legendary Silicon Valley giant in computing infrastructure, network computing, and open source software.
Today McNealy is heavily involved in advisory roles for companies that range from startup stage to large corporations, including Curriki and Wayin. Curriki (curriculum + wiki) is an independent 501(c)(3) organization working toward eliminating the education divide by providing free K-12 curricula and collaboration tools through an open-source platform. Wayin, the Digital Campaign CMS platform enables marketers and agencies to deliver authentic interactive campaign experiences across all digital properties including web, social, mobile and partner channels. Wayin services more than 300 brands across 80 countries and 10 industries.
Scott McNealy is an enthusiastic ice hockey fan, and an avid golfer with a single digit handicap. He resides in California with his wife, Susan, and they have 4 sons.
Resources
– Technology Pioneer Scott McNealy Joins Redis Labs Advisory Board
Related Posts
– On Artificial Intelligence, Machine Learning, and Deep Learning. Interview with Pedro Domingos. ODBMS Industry Watch, 2018-06-18
– On Technology Innovation, AI and IoT. Interview with Philippe Kahn. ODBMS Industry Watch, 2018-01-27
Follow us on Twitter: @odbmsorg
##
On Artificial Intelligence, Machine Learning, and Deep Learning. Interview with Pedro Domingos
“Debugging AI systems is harder than debugging traditional ones, but not impossible. Mainly it requires a different mindset, that allows for nondeterminism and a partial understanding of what’s going on. Is the problem in the data, the system, or in how the system is being applied to the data? Debugging an AI is more like domesticating an animal than debugging a program.”– Pedro Domingos.
I have interviewed Pedro Domingos, professor of computer science at the University of Washington and the author of “The Master Algorithm“, a bestselling introduction to machine learning for non-specialists. We talked about various topics related to Artificial Intelligence, Machine Learning, and Deep Learning.
RVZ
Q1. What’s the difference between Artificial Intelligence, Machine Learning, and Deep Learning?
Pedro Domingos: The goal of AI is to get computers to do things that in the past have required human intelligence: commonsense reasoning, problem-solving, planning, decision-making, vision, speech and language understanding, and so on. Machine learning is the subfield of AI that deals with a particularly important ability: learning. Just as in humans the ability to learn underpins all else, so machine learning is behind the growing successes of AI.
Deep learning is a specific type of machine learning loosely based on emulating the brain. Technically, it refers to learning neural networks with many hidden layers, but these days it’s used to refer to all neural networks.
Q2. Several AI scientists around the world would like to make computers learn so much about the world, so rapidly and flexibly, as humans (or even more). How can learned results by machines be physically plausible or be made understandable by us?
Pedro Domingos: The results can be in the form of “if . . . then” rules, decision trees, or other representations that are easy for humans to understand. Some types of models can be visualized. Neural networks are opaque, but other types of model don’t have to be.
Q3. It seems no one really knows how the most advanced AI algorithms do what they do. Why?
Pedro Domingos: Since the algorithms learn from data, it’s not as easy to understand what they do as it would be if they were programmed by us, like traditional algorithms. But that’s the essence of machine learning: that it can go beyond our knowledge to discover new things. A phenomenon may be more complex than a human can understand, but not more complex than a computer can understand. And in many cases we also don’t know what humans do: for example, we know how to drive a car, but we don’t know how to program a car to drive itself. But with machine learning the car can learn to drive by watching video of humans drive.
Q4. That could be a problem. Do you agree?
Pedro Domingos: It’s a disadvantage, but how much of a problem it is depends on the application. If an AI algorithm that predicts the stock market consistently makes money, the fact that it can’t explain how it did it is something investors can live with. But in areas where decisions must be justified, some learning algorithms can’t be used, or at least their results have to be post-processed to give explanations (and there’s lots of research on this).
Q5. Let`s consider an autonomous car that relies entirely on an algorithm that had taught itself to drive by watching a human do it. What if one day the car crashed into a tree, or even worst killed a pedestrian?
Pedro Domingos: If the learning took place before the car was delivered to the customer, the car’s manufacturer would be liable, just as with any other machinery. The more interesting problem is if the car learned from its driver. Did the driver set a bad example, or did the car not learn properly?
Q6. Would it be possible to create some sort of “AI-debugger” that let you see what the code does while making a decision?
Pedro Domingos: Yes, and many researchers are hard at work on this problem. Debugging AI systems is harder than debugging traditional ones, but not impossible. Mainly it requires a different mindset, that allows for nondeterminism and a partial understanding of what’s going on. Is the problem in the data, the system, or in how the system is being applied to the data? Debugging an AI is more like domesticating an animal than debugging a program.
Q7. How can computers learn together with us still in the loop?
Pedro Domingos: In so-called online learning, the system is continually learning and performing, like humans. And in mixed-initiative learning, the human may deliberately teach something to the computer, the computer may ask the human a question, and so on. These types of learning are not widespread in industry yet, but they exist in the lab, and they’re coming.
Q8. Professional codes of ethics do little to change peoples’ behaviour. How is it possible to define incentives for using an ethical approach to software development, especially in the area of AI?
Pedro Domingos: I think ethical software development for AI is not fundamentally different from ethical software development in general. The interesting new question is: when AIs learn by themselves, how do we keep them from gowing astray? Fixed rules of ethics, like Asimov’s three laws of robotics, are too rigid and fail easily. (That’s what his robot stories were about.) But if we just let machines learn ethics by observing and emulating us, they will learn to do lots of unethical things. So maybe AI will force us to confront what we really mean by ethics before we can decide how we want AIs to be ethical.
Q9. Who will control in the future the Algorithms and Big Data that drive AI?
Pedro Domingos: It should be all of us. Right now it is mainly the companies that have lots of data and sophisticated machine learning systems, but all of us – as citizens and professionals and in our personal lives – should become aware of what AI is and what we can do with it. That’s why I wrote “The Master Algorithm”: so everyone can understand machine learning well enough to make the best use of it. How can I use AI to do my job better, to find the things I need, to build a better society? Just like driving a car does not require knowing how the engine works, but it does require knowing how to use the steering wheel and pedals, everyone needs to know how to control an AI system, and to have AIs that work for them and not for others, just like they have cars and TVs that work for them.
Q10. What are your current research projects?
Pedro Domingos: Today’s machine learning algorithms are still very limited compared to humans. In particular, they’re not able to generalize very far from the data.
A robot can learn to pick up a bottle in a hundred trials, but if it then needs to pick up a cup it has to start again from scratch. In contrast, a three-year-old can effortlessly pick anything up.
So I’m working on a new machine learning paradigm, called symmetry-based learning, where the machine learns individual transformations from data that preserve the essential properties of an object, and can then compose the transformations in many different ways to generalize very far from the data. For example, if I rotate a cup it’s still the same cup, and if I replace a word by a synonym in a sentence the meaning of the sentence is unchanged. By composing transformations like this I can arrive at a picture or a sentence that looks nothing like the original, but still means the same.
It’s called symmetry-based learning because the theoretical framework to do this comes from symmetry group theory, an area of mathematics that is also the foundation of modern physics.
————————————————

Pedro Domingos is a professor of computer science at the University of Washington and the author of “The Master Algorithm”, a bestselling introduction to machine learning for non-specialists.
He is a winner of the SIGKDD Innovation Award, the highest honour in data science, and a Fellow of the Association for the Advancement of Artificial Intelligence. He has received a Fulbright Scholarship, a Sloan Fellowship, the National Science Foundation’s CAREER Award, and numerous best paper awards.
He received his Ph.D. from the University of California at Irvine and is the author or co-author of over 200 technical publications. He has held visiting positions at Stanford, Carnegie Mellon, and MIT. He co-founded the International Machine Learning Society in 2001. His research spans a wide variety of topics in machine learning, artificial intelligence, and data science, including scaling learning algorithms to big data, maximizing word of mouth in social networks, unifying logic and probability, and deep learning.
Resources
The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World. New York: Basic Books, 2015.
What’s Missing in AI: The Interface Layer. In P. Cohen (ed.), Artificial Intelligence: The First Hundred Years. Menlo Park, CA: AAAI Press. To appear.
How Not to Regulate the Data Economy. Medium, 2018.
Ten Myths About Machine Learning. Medium, 2016.
Debugging data: Microsoft researchers look at ways to train AI systems to reflect the real world. Microsoft AI Blog. | John Roach
Software
– Alchemy: Statistical relational AI.
– SPN: Sum-product networks for tractable deep learning.
– RDIS: Recursive decomposition for nonconvex optimization.
– BVD: Bias-variance decomposition for zero-one loss.
– NBE: Bayesian learner with very fast inference.
– RISE: Unified rule- and instance-based learner.
– VFML: Toolkit for mining massive data sources.
Online Course
– online machine learning class. Pedro Domingos (Link to series of YouTube videos)
Related Posts
– On Technology Innovation, AI and IoT. Interview with Philippe Kahn ODBMS Industry Watch, January 27, 2018
– On Artificial Intelligence and Analytics. Interview with Narendra Mulani ODBMS Industry Watch, August 12, 2017
– How Algorithms can untangle Human Questions. Interview with Brian Christian. ODBMS Industry Watch, March 31, 2017
–Big Data and The Great A.I. Awakening. Interview with Steve Lohr. ODBMS Industry Watch, December 19, 2016
–Machines of Loving Grace. Interview with John Markoff. ODBMS Indutry Watch, August 11, 2016
–On Artificial Intelligence and Society. Interview with Oren Etzioni. ODBMS Industry Watch, January 15, 2016
Follow us on Twitter: @odbmsorg
##