The technical white paper presents Datometry Adaptive Data Virtualization™ (ADV) technology which solves the problem of migrating to cloud data warehouses effectively and at a fraction of the cost of other approaches. The ADV approach enables database or data warehouse applications—originally developed for a specific database or data warehouse on-premises—to run instantly and natively in the cloud, without requiring modifications to the applications.
The key principle of ADV is the interception of application queries as they are emitted by an application and subsequent on-the-fly translation of those queries from the language used by the application (SQL-A) into the language provided by the cloud data warehouse (SQL-B), as shown in Figure 1. The translation must be aware of semantic differences between the systems and compensate for missing functionality in many cases.
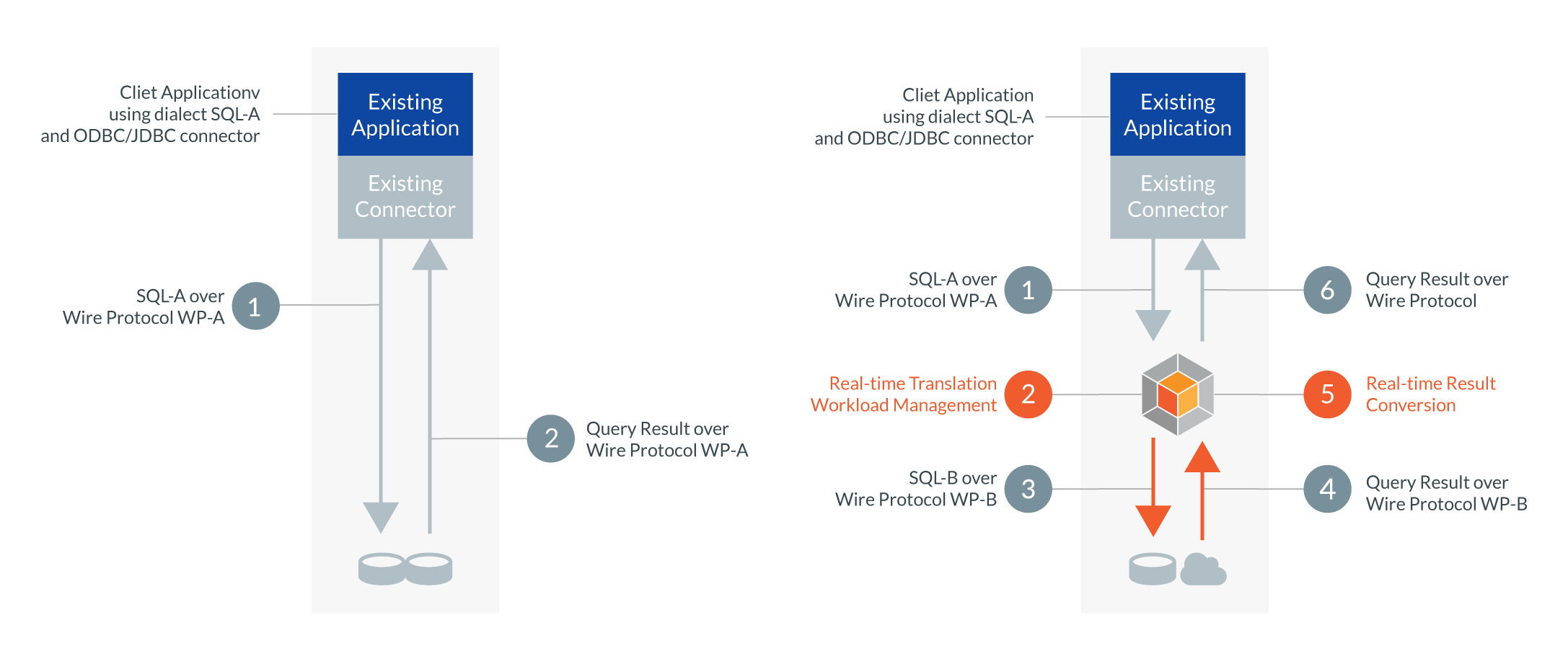
Figure 1: Application/database communication before re-platforming (left) and after (right). Applications remain unchanged and continue to use query language SQL-A.
Benefits of Adaptive Data Virtualization Over a Conventional Migration
The overwhelmingly positive reception by customers and technology partners alike underlines the benefits of ADV over a conventional data warehouse migration approach along three dimensions:
- Short time to value: ADV can be deployed instantly and requires little or no build-out and implementation. This eliminates the time for adjusting, rewriting or otherwise making existing database or data warehouse applications compatible with the new target data warehouse platform.
- Low cost: Much of the cost in migration projects is incurred by the manual translation of SQL embedded in applications and subsequent iterations of testing the rewrites. Being a software solution, ADV eliminates both manual interaction and time-consuming and expensive test phases entirely.
- Reduced risk: As ADV leaves existing applications unchanged, new database technology can be adopted rapidly and without having to commit significant resources or time. This reduces the risk to the enterprise substantially as data warehouse re-platforming projects can be fully tested in advance and, in the unlikely event that results do not meet expectations, switching back to the original stack is instant and inexpensive.
Conventional Data Warehouse Migration
The migrating or re-platforming of a database or data warehouse and its dependent application is a highly involved process with multiple steps and around which an entire industry has been established. The steps are briefly described below.
Discovery of Data Warehouse Applications
First, to compile a realistic project plan, a full inventory of all enterprise data management technologies used, that is, all applications connected to the database, is needed. This activity needs to look at every single component and determine among other things:
- Application type and technology for every single client needs to be evaluated including Business Intelligence (BI) and reporting and ad-hoc uses. This includes proprietary and third-party clients, including embedded use cases where seemingly innocuous business applications, such as Microsoft Excel emit queries.
- Drivers and libraries used by every connecting component need to be cataloged to understand if they can be replaced. This step often uncovers surprising incompatibilities with respect to the new target database or data warehouse system and may require custom builds of connectors.
- SQL language. A gap analysis determining what features—specifically complex features—are being used. A clear understanding of which features may not be available on the downstream database or data warehouse system, for example, recursive queries, as well as proprietary features that predate standardization, for example, pre-ISO rank implementations, will drive the design and implementation of equivalent queries and expressions based only on primitives of the new database system.
The discovery phase is a function of the size and complexity of the ecosystem. This phase of a database or data warehouse migration can typically take up to 3-6 months or more.
Data Warehouse Content Transfer
The most prominent task, though frequently neither the most challenging nor the costliest, is the transfer of the content of the original database to the cloud database.
Schema Conversion
Transferring the schema from one database or data warehouse to another needs to replicate all relevant structures in the schema definition language of the new system. While most databases by now other equivalent structures, there are certain structural features that may not be transferable due to limitations in the new system, for example, Global Temporary Tables, Stored Procedures.
In contrast to logical design features, physical database design including indexes or other physical structures do not necessarily need to be transferred or require separate treatment once the database is transferred. Frequently, physical design choices are not portable or do not even apply to the new database system and can, therefore, be ignored. A more recent trend is to increasingly eliminate physical design choices altogether, for example, as in the case of Snowflake and XtremeData.
Treating schema conversion as a separate discipline has severe shortcomings: certain features that cannot be transcribed directly require a workaround that all applications need be made aware of, that is, simply transcribing the schema in isolation is bound to generate functionally incomplete results.
Data Transfer
Once a schema is transferred and established, data needs to be transferred in bulk or incrementally. More than a semantic problem, this is typically a logistical issue: for large amounts of data, most cloud service providers offer bulk transfer through online means, such as disk arrays shipped via courier services or similar. With today’s standard bandwidth available between data centers and the widespread network of cloud data centers, data transfer expect for very large data warehouses rarely constitutes a problem though.
Data Warehouse Application Migration
Adjusting applications to work with the new database is a multi-faceted undertaking. On a technical level, drivers, connectivity, and so forth need to be established. Then, SQL (embedded or in stand-alone scripts) needs to be rewritten, and any enclosing application logic may need to be adjusted accordingly.
To demonstrate some of the challenges when translating queries from one SQL dialect to another, consider the following query written in Teradata SQL dialect:
SEL
PRODUCT_NAME,
SALES AS SALES_BASE,
SALES_BASE + 100 AS SALES_OFFSET
FROM PRODUCT
QUALIFY
10 < SUM(SALES)
OVER (PARTITION BY STORE)
ORDER BY STORE, PRODUCT_NAME
WHERE CHARS(PRODUCT_NAME) > 4;
There are several vendor-specific constructs which make the above application query non-portable. For example, SEL is a shortcut for SELECT keyword and QUALIFY filters the output based on the result of a window operation, similar to the HAVING clause for GROUP BY clause.
Moreover, the order of the various clauses does not follow the standard: ORDER BY precedes WHERE which is not accepted by most other data warehouse systems. Built-in functions and operators, such as computing the length of a string or date arithmetic, frequently differ in syntax across vendors.
Another widely used construct not typically available in other systems is the ability to reference named expressions in the same query block. For example, the definition of SALES_OFFSET uses the expression SALES_BASE defined in the same block…
Download White Paper to learn more
Sponsored by Datometry