YCSB – KIVI VS DYNAMODB
October 29, 2019
Today, NoSQL databases are widely used with key-value datastores being one of the most used of all database varieties. The key-value database is designed for storing, retrieving, and managing associative arrays. Records are stored and retrieved using a uniquely identifying key to find data within the database quickly. These databases are used in many scenarios, such as AdTech for cache matching, TravelTech for real-time pricing, and IoT for enabling smart cities.
The most used key-value database is likely Amazon DynamoDB, although alternatives exist, including Microsoft Azure Cosmos DB and Aerospike. Amazon DynamoDB is fully granted to deliver single-digit, millisecond performance at any scale and provides an easy-to-use system managed and integrated within the Amazon Web Services (AWS) ecosystem. If a company needs to use a key-value, then it only needs to specify the format of the table, and a DynamoDB instance is deployed automatically in a few seconds that is ready to scale as required by the client. Many of the world’s fastest-growing businesses, such as Lyft and Airbnb, leverage DynamoDB as well as large enterprises, such as Samsung and Toyota, depending on its scalability and performance to support the company’s critical workloads.
LeanXcale provides an alternative key-value database named Kivi, which is a low-latency key-value datastore that grants fast bulk insertion, update, get, and scan operations. This system was carefully designed and implemented after many years of research on distributed systems. Some companies use Kivi for their most critical workloads, including VikData that uses Kivi to store all the data obtained monthly from more than 10 million profiles.
This article benchmark LeanXcale’s Kivi and DynamoDB with a comparison of the results, and the public Yahoo! Cloud Serving Benchmark (YSCB) is used.
DIMENSIONING AMAZON DYNAMODB
DynamoDB can deploy to an instance with a specific provisioned read and write capacity to block the auto-scaling functionalities of the system. This option is used to build a DynamoDB instance with enough capacity to run the YCSB benchmark. To determine the appropriate values for the provisioned capacity, we run Kivi on the c5d.xlarge AWS instances, which have four vCPUs and 8GB of RAM. However, only 6GB are assigned to Kivi, and the remaining are reserved for the operating system.
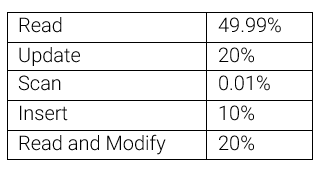
We run the YCSB client on c5.2xlarge AWS instances (eight vCPUs and 16GB of memory) using different YCSB client instances and thread numbers. The workload used for this benchmark is 49.99% read, 50% write, and 0.01% scan operations to retrieve 2,000 tuples each scan. In YCSB, each tuple has an average size of 1.1KB, and the key is a string. The evaluation starts populating the database with 400,000 tuples, and the benchmark runs 500,000 operations. The benchmark is run with 1, 2, 4, 6, and 10 different YCSB client instances and 1, 2, 5, 10, 20, and 30 threads.
With Kivi, we see that YCSB is running at more than 35,000 YSCB ops/sec. From this observation, we compute the DynamoDB capacity required to run the YSCB benchmark.

The YCSB tuple size is 1.1KB, meaning that DynamoDB needs at least two times the number of operations as computed before. Therefore, the following are the requirements of the DynamoDB system to compare with our Kivi installation:
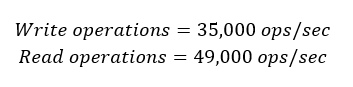
So, we have computed the capacity needed to provision DynamoDB to function similarly to Kivi.
YCSB THROUGHPUT RESULT
The following charts show the throughput obtained with Kivi and DynamoDB using the YCSB benchmark.
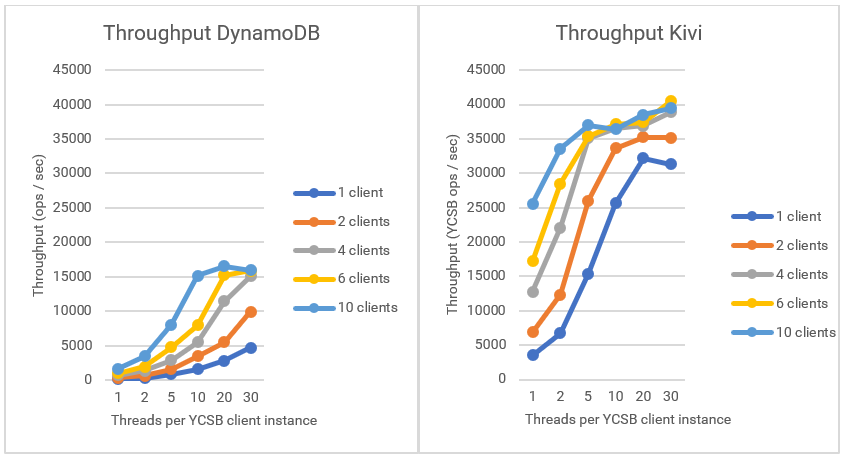
Even with the provisioned capacity, YCSB cannot run with more than 16,500 YCSB ops/sec in the best scenario. We must also check that the capacity of the DynamoDB instance is not fully used due to the latency that exists with YCSB. With Kivi, we obtained more than 35,000 YCSB ops/sec, and the maximum performance of the system occurs with just five threads per client, due to its low latency. The YCSB clients run synchronous operations for each thread, so if an operation takes less time, then it will take that thread less time to run for the next operation. With DynamoDB, we instead obtain a maximum latency with 10 or even 20 threads per client.
YCSB RESPONSE TIME
The second objective of this benchmark is to compare the latency of the operations between DynamoDB and Kivi. We demonstrate the average response times for the 95th and 99th percentiles. With the latter, we see if the system is stable and does not provide high latencies depending on the current load of the system showing the stability of both systems. In the following charts, we see the percentiles are good for both systems with the 99th percentile around four or five times more than the response time. In addition, the percentile 95th is similar to the average in most cases suggesting that most of the queries have a typical latency given by the average. However, the latency of Kivi is much better compared to DynamoDB for all the queries.
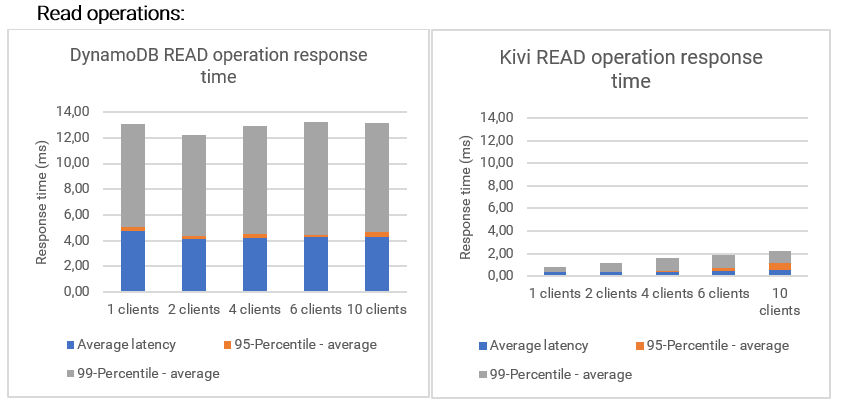
For read operations, Kivi is around ten times faster than DynamoDB, giving response times lower than 0.5 ms in all cases. DynamoDB has one-digit millisecond latencies, but Kivi is responding in less than 50 us.


A similar response occurs with inserts and updates as both operations in YCSB are managed like inserts for key-value databases. In fact, the response time is similar for insert and update operations. The response time of Kivi is short due to its cache system. Kivi pre-stores all new tuples before traversing the tree and placing them in the system. Observe that for DynamoDB we have to use a much bigger scale in the response time index than for LeanXcale, both for update and insert operations, such a big difference there is between their response times.
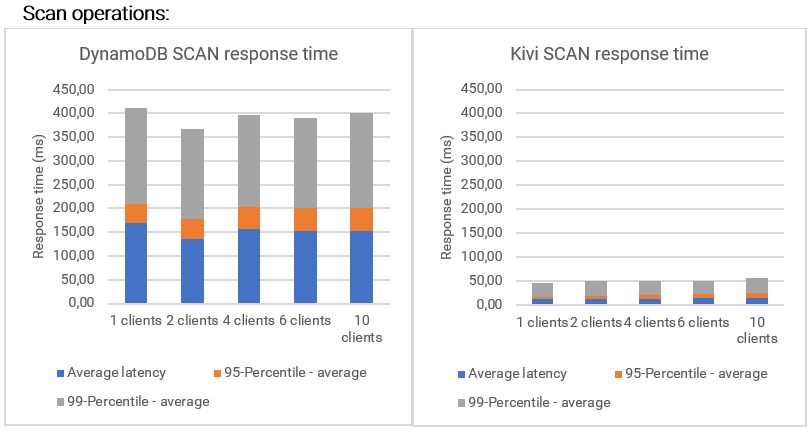
Kivi is nearly ten times faster than DynamoDB for scan operations. All scans chose a starting random key and read the subsequent 2,000 tuples from the database. The reason for this approach is that DynamoDB is not optimized for scan operations, while Kivi is ready for scan operations even when applying filters or aggregations.
THE TOTAL COST OF OWNERSHIP
The cost of DynamoDB for the provisioned capacity we need for this comparison is $21,665.28/month, which includes everything needed to operate DynamoDB.
The cost of Kivi depends on the underlying AWS instance selected. For this benchmark, we used the c5d.xlarge with 100GB of storage resulting in a total cost of the instance is $142.80/month. DynamoDB offers a replicated system, and Kivi has a costless (in terms of latency) replication but requires an additional instance. LeanXcale is a license-based product, so its cost with AWS is 80% in addition to the price of the AWS instance. In total, the Kivi deployment costs $514,25/month.
WRITTEN BY:
Diego Burgos Sancho, Software Engineer at LeanXcale

Jesús Manuel Gallego Romero, Software Engineer at LeanXcale

Sponsored by LeanXcale.