MOTIVATION: SUPPORTING HIGH DATA INGESTION RATES AND EFFICIENT SQL QUERIES

The cost of monitoring solutions highly depends on the required footprint to ingest the monitoring data and to query these data. Today there is a duality on existing data management solutions. On one hand, NoSQL technology and, more particularly, key-value data stores, are very efficient at ingesting data. However, queries are not efficiently processed since they have a dramatic tradeoff due to the data structures they use to manage data, this makes them very efficient for ingesting data, but very inefficient for querying data. On the other hand, SQL databases are symmetric. They are very efficient at querying data. However, they are very inefficient at ingesting data. Until now, architects of monitoring solutions had to choose one of the options, accepting its severe tradeoffs, or building complex architectures combining both kinds of data management that result in high cost of engineering and maintenance.
WHY DUAL INTERFACE SQL & NOSQL?
One differential key feature of LeanXcale is its dual interface SQL & NoSQL. LeanXcale’s architecture lies in three subsystems:
1) a relational distributed key-value data store
2) a transactional management system
3) an SQL query engine.
The relational key-value data store can ingest data at very high rates thanks to its unique architecture and underlying data structures to process updates and queries. It is able to cache updates and propagate them in batches to maximize the performance of every IO that is useful for multiple updates. This means it is able to ingest data very efficiently, unlike SQL databases that have to perform several IOs per updated row. At the same time, it provides efficient queries over the ingested data, since queries use a B+ tree as SQL databases. Cached updates are merged with the read data from the B+ tree to provide fully consistent reads. Therefore, LeanXcale has been able to provide the efficiency of data ingestion of key-value data stores, combined with the efficiency of query processing of SQL databases.
PROBLEMS WITH QUERIES IN NOSQL DATA STORES
What happens if we implement the monitoring system using a NoSQL data store? Let’s see. Ingestion is quite efficient, since key-value data stores are based on SSTables that cache updates and write them to disk periodically on a different file, therefore amortizing a few IOs to write many rows. However, they have a severe tradeoff with the efficiency of reads. Reads become very expensive. Why? Let’s analyze how they perform queries.
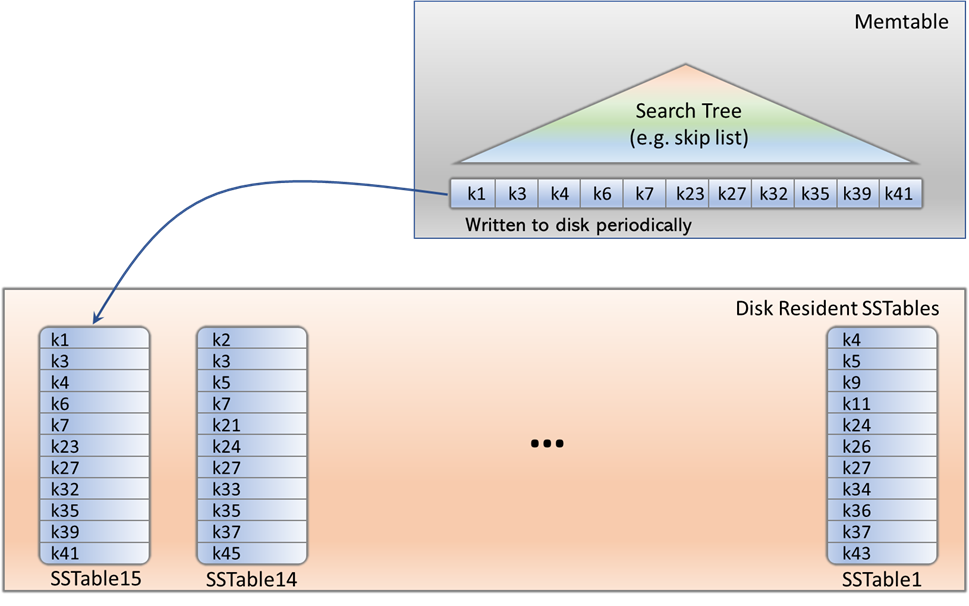
Assume a simple range query. In the SStable, a particular horizontal data fragment will be split across many different files. All these files have to be read to be able to perform the range query. This results in a high inefficiency when reading. SSTables can be improved so data are stored as B+ trees in each SSTable. Let’s study this case seeing as it is the most beneficial. Now the search must be performed across many B+ trees. Assume for simplicity that there are 16 SSFiles, each with a B+ tree, so we need to perform the search of the first key of the range in 16 B+ trees that will be 16 times smaller. Assume each B+ tree has 1024 blocks. So, each search will need to access log (1024) blocks = 10 blocks. There are 16 searches so it will result in reading 160 blocks. In the case of a single B+ tree we would have performed the search in a B+ tree with 16384 blocks and reading log (16384) = 14 blocks. So, the NoSQL solution is reading 160 blocks while the SQL is reading 14 blocks, more than an order of magnitude more blocks.
PROBLEMS IN INGESTING DATA WITH SQL DATABASES
SQL databases will process the queries efficiently thanks to the underlying data structure; the B+ tree. However, these data structure will also result in high inefficiency when it comes to ingesting the data. This is due to the size of targeted data, typically in the order of TBs, not fitting in the memory. Assume we have a table of 1TB. The B+ tree will grow to, for instance, 6 levels for storing all the data. If the database runs on a node with 128 GB of memory, it will fit below 25% of the data in the cache, typically nodes from the root and levels close to the root (see Figure 2).
This means that in practice every insertion has to reach the target leaf node that, in the example, will mean reading an average of 3 blocks from persistent storage. All these read blocks will force the eviction of the same number of blocks from the cache, causing an average of 3 blocks to be written to persistent storage. That is, a single row is causing 6 IOs. That is why SQL databases are very inefficient at ingesting data.
LEANXCALE SOLUTION: BLENDING NOSQL AND SQL
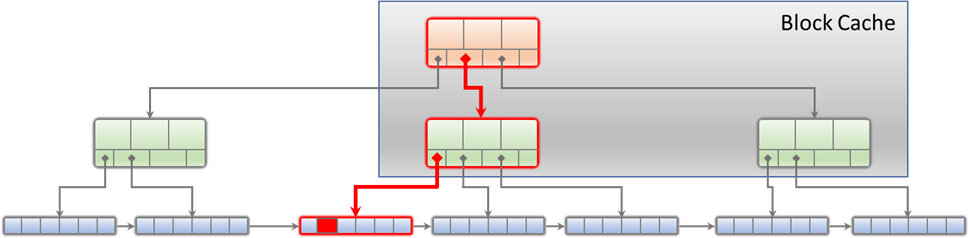
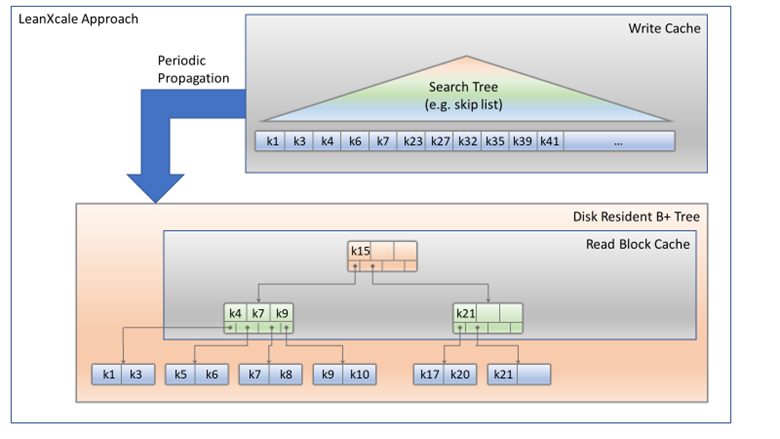
How does LeanXcale solve the problem? LeanXcale uses a relational key-value data store as storage engine which is quite unique because of this blend of relational and key-value natures. It does so at different levels. Firstly, due to the way updates and queries are processed, secondly, thanks to its NUMA aware architecture and thirdly, due to its dual interface. LeanXcale uses two different caches. One cache for reads and one cache for writes. The underlying data structure is the B+ tree plus the two caches. The write cache stores all insertions, updates and deletions of rows in its memory. The read cache is an LRU block cache that stores the most recently read blocks in its memory. The LRU policy is modified so it is still efficient when the write cache is propagated to persistent storage or in the presence of large queries reading many rows and requiring it to access many disk blocks. LeanXcale is storing the persistent data in B+ trees as SQL databases do (see Figure 3). A B+ tree is a search n-ary tree. Data are actually only stored on the leaf nodes.
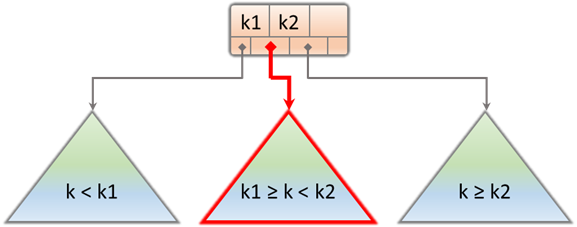
The intermediate nodes only store keys to enable them to perform the search. The stored keys are the split points of the data stored on the different children subtrees, as can be seen in Figure 4. Searching for a particular key, sk, allows one subtree to be chosen at each node of the tree, since it is known that the rest will not contain that key. For instance, if sk is higher than k1 but lower than k2, we know the data can only be on the middle subtree. This process is repeated iteratively until the leaf node that contains the searched row is reached (see Figure 3).
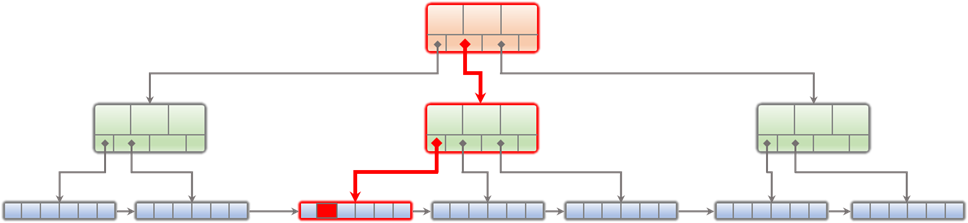
The search tree natures of the B+ tree guarantees that the leaf node(s) containing the targeted rows can be reached with a logarithmic number of blocks. This is why LeanXcale is as efficient in querying data as SQL databases. As previously mentioned, NoSQL data stores result in queries that are more than an order of magnitude less efficient in terms of read blocks from persistent storage (that make NoSQL more inefficient for IO bound workloads) and number of key comparisons performed (that make NoSQL more inefficient for CPU bound workloads). The way writes are processed overcomes the inefficiency of SQL databases that require multiple IOs to insert a single row. LeanXcale uses a cache of writes that prevents it from having to perform multiple access to reach the leaf node of each write (see Figure 5).
HOW DOES IT WORK LEANXCALE NOSQL AND SQL BLENDING?
LeanXcale B+ tree, plus the read and write caches, enables the following: by caching writes and propagating them only periodically to persistent storage, several writes going to the same leaf node amortize the necessary IOs across many different writes. Bidimensional partitioning enhances this efficient data ingestion (see our blog post on Bidimensional Partitioning). By using a B+ tree and caching blocks, it enables the number of read blocks from persistent storage to be minimized. Therefore, it is able to ingest data as efficiently as NoSQL and able to query data as efficiently as SQL.
Another factor that results in the LeanXcale efficiency is its architecture, which is designed for NUMA architectures. KiVi servers are allocated to CPU sockets and memory local to the CPU socket. That way, they prevent the expensive NUMA remote access (in terms of extra latency) and exhausting of the memory bandwidth that results in a bottleneck. The third factor for a better efficiency is that SQL databases rely on SQL for all operations over the database. SQL processing and associated interfaces (e.g., JDBC or ODBC) result in high overheads for insertion workloads. However, LeanXcale, thanks to its dual NoSQL and SQL interface, is able to perform the insertions/updates. This is done through the NoSQL API that is as highly efficient as other NoSQL APIs, yet avoids all the overhead of SQL and associated APIs such as JDBC.
AN EXAMPLE: INFRASTRUCTURE MONITORING TOOL
Monitoring tools have to face at least two data challenges:
Minimize the HW footprint to ingest the data stream generated by agents, probes, and device polling. The minimum required footprint defines the pricing/efficiency ratio which, in summary, strongly determines the TCO.
Reply to the recurrent queries in an end-user acceptable time. In other words, these data needs to be queried from the dashboards in order to provide a view of the evolution of different metrics and, in the case of incidences being able to drill down to the detailed data, to find out what caused the incidence.
We will define the following scenario: Monitoring 110 Virtual Machines polling a sample once every five minutes and collecting 10 metrics/samples. This scenario generates an incoming data stream of 366K samples/s and 3.666M metrics/s.
How does a traditional SQL open-source database deal with it? We may use as a reference around 15K samples/s as an optimal intaking pace for this type of database. In short, we need around 24 servers to handle the described workload.
How does key-value storage manage this scenario? Using as a reference this benchmark published by ScyllaDB, a key-value database in a three-node cluster of i3.8xlarge (32 vCPUs, 244GB) achieves a similar intaking rate (~320K).
On the other hand, LeanXcale can ingest this ingestion rate with a couple of four core servers (m5.xlarge) as we can see in the following demo. As we can appreciate, LeanXcale database reduces the deployment size and the TCO.
Ingestion velocity is only half of the job; user experience is also a key element for a tool of these characteristics. Doherty’s criteria says that the goal response time should be around 400ms. The 2009 Forrester & Akamai study indicates that the typical user threshold is a waiting time of two seconds. As commented, complex queries have a very different response time, just because of the nature of the underlying data-structure in SQL and NoSQL databases. Key-value data stores require data with an order of magnitude more resources than a relational database to be read. Some common queries, for instance, top 10 or the time-series of some monitored items that fulfill some features, are often time-demanding even in a relational database (3 or 4 seconds). Some queries on a key-value datastore become unacceptable since they require full scans, and often these queries require some complexity in the application level that increase the time-to-market.
MAIN TAKEAWAYS
NoSQL data stores are efficient at ingesting data but are more than an order of magnitude less efficient when it comes to querying data. SQL, on the other hand, is very efficient at querying data, since only a logarithmic number of blocks is required to be read. However, ingesting data is very inefficient because it requires several IO operations to insert a single row.
LeanXcale’s approach enables it to query data as efficiently as SQL, reading a logarithmic number of blocks and ingesting data as efficiently as NoSQL, thanks to its write cache and, when appropriate, bidimensional partitioning.
LeanXcale, thanks to its NUMA-aware architecture, reaches higher levels of efficiency than existing databases in these architectures. And finally, LeanXcale’s dual interface allows it to both write data very efficiently via the NoSQL API and query data very comfortably via SQL.
REFERENCES

[Özsu & Valduriez 2020] Tamer Özsu, Patrick Valduriez. Principles of Distributed Database Systems, 4th Edition, Springer, 2020.
RECOMMENDED POSTS

Scalability: Understanding Distributed Databases Scalability by Ricardo Jimenez-Peris and Patrick Valduriez
ABOUT THIS BLOG SERIES
This blog series aims at educating database practitioners on the differential features of LeanXcale, taking a deep dive on the technical and scientific underpinnings. The blog provides the foundations on which the new features are based and provides the reader with facts, allowing them to compare LeanXcale to existing technologies and learn its real capabilities.
ABOUT THE AUTHORS
- Dr. Ricardo Jimenez-Peris is the CEO and founder of LeanXcale. Before founding LeanXcale, for over 25 years he was a researcher in distributed database systems, director of the Distributed Systems Lab and a university professor teaching distributed systems.
- Dr. Patrick Valduriez is a researcher at Inria, co-author of the book “Principles of Distributed Database Systems” that has educated legions of students and engineers in this field and, more recently, Scientific Advisor of LeanXcale.
- Mr. Juan Mahillo is the CRO of LeanXcale and a former serial Entrepreneur. After selling and integrating several monitoring tools for the biggest Spanish banks and telco with HP and CA, he co-founded two APM companies: Lucierna and Vikinguard. The former was acquired by SmartBear in 2013 and named by Gartner as Cool Vendor.
ABOUT LEANXCALE
LeanXcale is a startup making an ultra-scalable NewSQL database that is able to ingest data at the speed and efficiency of NoSQL and query data with the ease and efficiency of SQL. Readers interested in LeanXcale can visit the LeanXcale website.
Sponsored by LeanXcale.