On InfluxDB Clustered, the Latest 3.0 Release from Time Series Leader InfluxData. Q&A with Gunnar Aasen
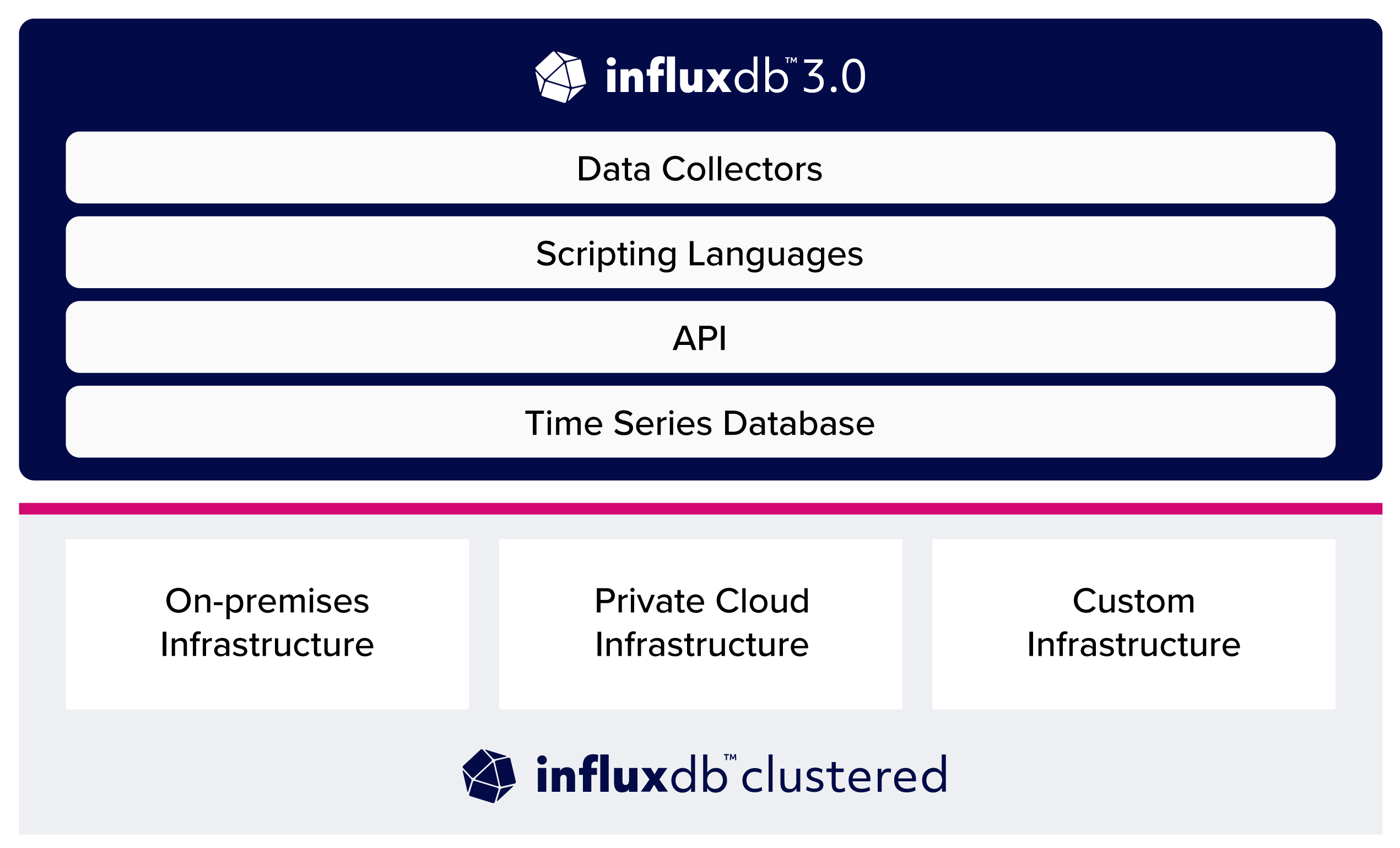
Q1. InfluxData just announced InfluxDB Clustered, its latest product developed on the InfluxDB 3.0 architecture. Can you tell us about it?
InfluxDB Clustered is the first version of InfluxDB 3.0 that is available as an on-prem, self-managed solution that users can deploy on their own hardware or in private cloud environments. InfluxDB Clustered can be considered the next evolution of our existing InfluxDB Enterprise product.
Q2. What are the key features of InfluxDB Clustered?
Here is an overview of some of the most important features that are new to InfluxDB Clustered:
- Decoupled architecture: InfluxDB 3.0 is built using a decoupled architecture that separates compute and storage. From a compute perspective, this is taken a step further by allowing ingest and query capabilities to scale independently. This means that you can fine-tune InfluxDB 3.0 for your own workload, increasing the number of ingesters for write-heavy workloads and the number of query nodes for high volumes of queries or complex queries that require more resources.
- Tiered storage: InfluxDB 3.0 is able to efficiently move data between “hot” in-memory storage for fast queries and cheaper “cold” object storage. This allows InfluxDB to provide the best of both worlds with fast query performance and cheap long-term storage of your data.
- Open data architecture: InfluxDB 3.0 is built around a number of open source standards that make it easy to integrate InfluxDB into your architecture. Apache Arrow is used as the in-memory data format. This enables integrations with many libraries and frameworks as well as great performance when working with your time series data. Apache Parquet is used for persisting data, which allows for interoperability with many other tools.
- Enterprise security: InfluxDB Clustered allows InfluxDB to be deployed in air-gapped environments for use cases that require high security guarantees. Clustered also provides support for SSO, audit logging, fine-grained access control, and private connectivity.
- Advanced configuration options: InfluxDB Clustered gives users even more control over how they configure their database. In addition to things like query and ingest performance mentioned above, users can also modify how data is partitioned, indexed, and even how data is sorted on disk to optimize performance for specific types of queries.
- SQL support: InfluxDB 3.0 adds support for SQL, making it easier to get started with InfluxDB and integrate it into your application. InfluxDB 3.0 also supports InfluxQL.
Q3. How does the architecture of InfluxDB Clustered make it well-suited for enterprise workloads?
From an architectural perspective, the main benefit of InfluxDB Clustered for enterprise users is the flexibility it provides in terms of deployment and configuration. For many enterprise workloads a cloud-hosted database isn’t an ideal solution due to low latency requirements, security regulations, and potential network disruptions. InfluxDB Clustered solves these problems by allowing users to deploy InfluxDB on their own hardware.
Another key part of InfluxDB Clustered for enterprise users is that it can be fine-tuned to match more specific workload requirements. InfluxDB 3.0 separates compute and storage, so depending on the use case, users can scale the amount of hardware dedicated for ingesting, querying, and storing data up and down independently. Other configurations include how long data should be kept in “hot” storage for faster query times and how data is partitioned. This allows users to optimize between cost and performance to match their requirements as needed based on their specific workload.
Q4. What other aspects of InfluxDB Clustered are InfluxDB Enterprise users most excited about?
One of the biggest benefits we are seeing with InfluxDB 3.0 users is that in many cases they don’t have to worry as much about data lifecycle management. Because InfluxDB 3.0 is so much cheaper in terms of storage costs (potentially 90% or higher reduction in costs) things like downsampling or retention policies are more relaxed. This not only helps make life easier for developers but it also improves data analysis accuracy because more historical data can be stored with higher granularity.
Another feature of InfluxDB Clustered that is critical for many enterprise users are newer security features like support for private networking, single sign-on integrations, audit logging, and attribute-based access control (ABAC).
A final aspect of InfluxDB Clustered and InfluxDB 3.0 that users are excited about is SQL support. This allows users to utilize a query language many are familiar with and also opens up a number of integrations with other tools they use in their workflow.
Q5. Low storage costs seem to be a key feature of the announcement. How is InfluxDB 3.0 architected to reduce these costs so drastically?
There are two factors that enable the reduced storage costs seen with InfluxDB 3.0. The first is that the new storage engine built on Apache Arrow is able to compress data more efficiently, reducing the overall size of the data being stored. The second is that InfluxDB 3.0 is able to use cheaper object storage for persisting data rather than alternatives like SSD. This means that data is much cheaper on a per-unit basis.
Q6. InfluxData recently rolled out preliminary benchmarks about InfluxDB 3.0. What are some of the highlights?
Our benchmarks compared InfluxDB 3.0 to open source InfluxDB 1.8 and showed significant improvements across just about every performance metric possible for a database. Here are some of the main highlights (as compared to InfluxDB OSS):
- InfluxDB 3.0 provides 45x better write throughput.
- InfluxDB 3.0 has 4.5x better storage compression.
- InfluxDB 3.0 is more efficient for given hardware resources and can reduce storage costs by more than 90%.
- InfluxDB 3.0 queries are 2.5-45x faster across a broad range of query types for recent data (5m).
- InfluxDB 3.0 queries are 5-25x faster across a broad range of query types for past 1-hour time ranges.
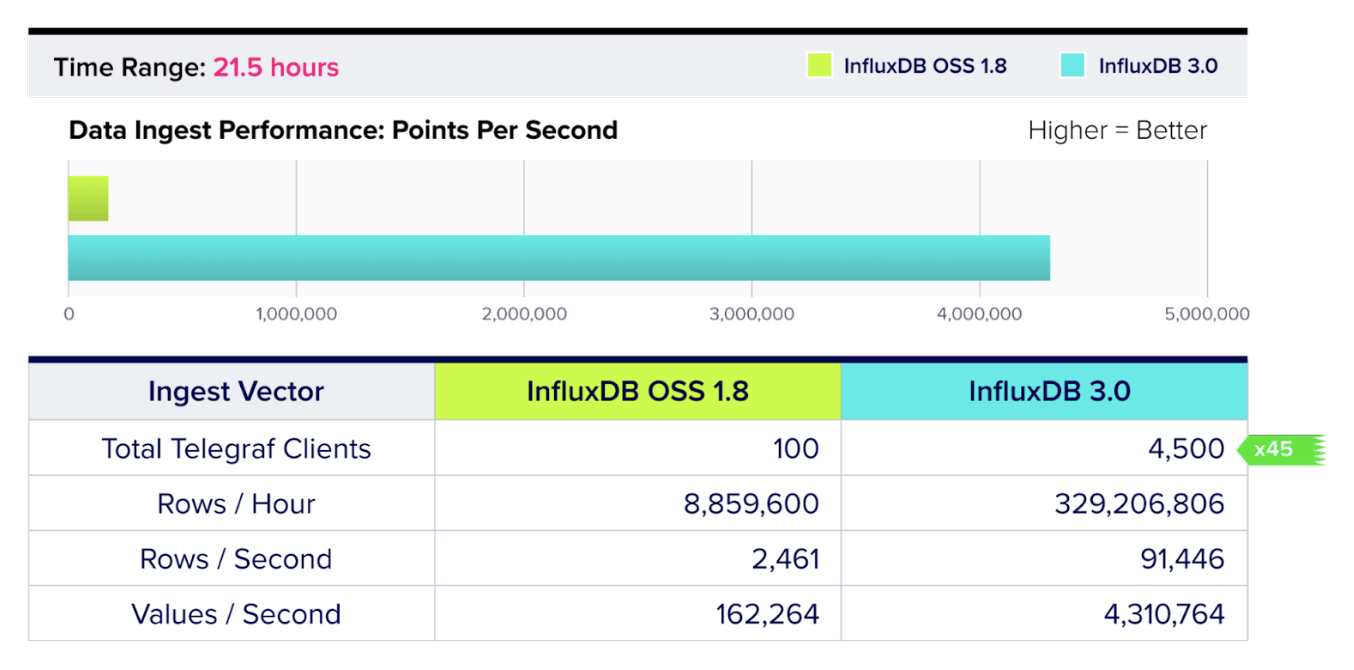
You can check out the benchmark summary here and also download the full report with methodology and technical breakdown of the benchmarks. InfluxData already has more benchmarks in progress against other time series databases that will be released in the weeks ahead.
Q8. Anything else you want to share?
InfluxDB 3.0 is a massive step forward in terms of performance for a database that was already the most popular open source time series database in the market. If you are working with time series data, now is a good time to get started with InfluxDB.
If you don’t know which version of InfluxDB is right for you, you can check out this page to see which works best for your use case.
………………………………………..

Gunnar Aasen is a Senior Product Manager at InfluxData. Gunnar was an early employee and the first support engineer at InfluxData. He now enjoys applying his deep technical expertise toward building developer-oriented products. He is based in Berkeley, California.
Sponsored by InfluxData