Why is the SMACK stack all the rage lately?
Why is the SMACK stack all the rage lately?
By Natalino Busa.
Originally published at http://www.natalinobusa.com/2015/11/why-is-smack-stack-all-rage-lately.html.
In the past decade, we have learned how to handle and process increasingly bigger datasets. The focus so far has been mostly on how to collect, aggregate and crunch those large dataset in a reasonable amount of time.
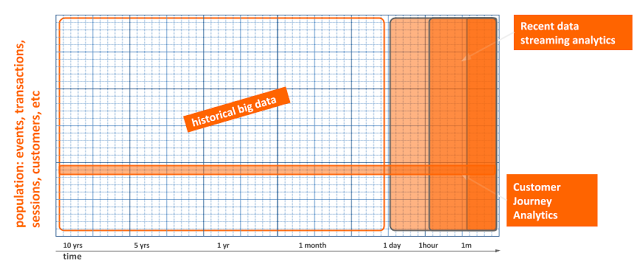
However, today it’s not always about Big Data. In many use cases, we need not one, but different data analysis paradigms. The following diagram shows how data can be categorized according to the way it’s used.
| Big, Fast and Event Data Processing |
Time plays an important role in many data-driven products and applications. If you would put time on one axis and facts (transactions, customer events, touch points, interactions) on the other axis, you can see how data can be segmented for a specific data analysis.
Why Big Data?
High quality and robust models rely on the quality and the amount of available data. The size of a dataset can be decisive in order to identify outliers and to provide enough samples for the machine learning algorithms.
More data can help reducing the generalization error of the model, a common problem in data science called “overfitting”. More data also allows us to detect weaker signals and small clusters which might not be visible in a smaller dataset. A problem usually defined as “data bias”.
What’s really important about Big Data, is to keep the productivity of the data pipeline as high as possible. So more nodes help, and so does more memory per node. A good improvement from the original MapReduce idea is to leverage data locality as much as possible in memory as done for instance in Spark.
Why Fast Data?
We understand that recent information is valuable, in particular, aggregated trends over recent facts, say of last minute, hours, day. By analyzing how those trends and aggregated signals evolve is the first step towards a new generation of machine aided apps, which will providing facts highlighting, personalized filtering on the event stream and, in general, better insight about the past events, and hinted prediction about future ones.
Why Event Processing?
Finally, you can follow a single stream of events related to a single user, customer, account. It allows us to build applications and products which quickly react on events as soon as they are coming in the processing pipeline. This way of computing is a must have for mission critical processing which must be completed within very short latency budgets.
This technologies can be combined in order to support model training, fast alerting/notifications and resource access via Web API’s
The Smack Stack
An architecture pattern which is quite popular today is the SMACK pattern.
It consists of the following technologies:
- Spark
- Mesos
- Akka
- Cassandra
- Kafka
Kafka takes care to event transport, Cassandra is used to persist and distribute events. While Spark and Akka can be combined to build various data analysis pipelines for both large data sets, event processing, in order to meet the required throughput, and latency constraints. Mesos serves as a task coordinator, facilitating the distribution of tasks and jobs in the cluster.

| SMACK stack: how to put the pieces together |
Spark
In contrast to Hadoop’s two-stage disk-based MapReduce paradigm, Spark’s multi-stage in-memory primitives provides performance up to 100 times faster for certain applications. By allowing user programs to load data into a cluster’s memory and query it repeatedly, Spark is well-suited to machine learning algorithms, and exposes its api in Scala, Python, R and Java. The approach of Spark is to provide a unified interface that can be used to mix SQL queries, machine learning, graph analysis, and streaming (micro-batched) processing.
Mesos
Apache Mesos is an open-source cluster manager that was developed at the University of California, Berkeley. It provides efficient resource isolation and sharing across distributed applications, or frameworks. The software enables resource sharing in a fine-grained manner, improving cluster utilization.
Mesos uses a two-level scheduling mechanism where resource offers are made to frameworks (applications that run on top of Mesos). The Mesos master node decides how many resources to offer each framework, while each framework determines the resources it accepts and what application to execute on those resources. This method of resource allocation allows near-optimal data locality when sharing a cluster of nodes amongst diverse frameworks.
Akka
Akka is an open-source toolkit and runtime simplifying the construction of concurrent and distributed applications on the JVM. Akka supports multiple programming models for concurrency, but it emphasizes actor-based concurrency, with inspiration drawn from Erlang.
The actor model in computer science is a mathematical model of concurrent computation that treats “actors” as the universal primitives of concurrent computation: in response to a message that it receives, an actor can make local decisions, create more actors, send more messages, and determine how to respond to the next message received.
Cassandra
Apache Cassandra is an open source distributed database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers robust support for clusters spanning multiple datacenters, with asynchronous masterless replication allowing low latency operations for all clients.
Cassandra also places a high value on performance. In 2012, University of Toronto researchers studying NoSQL systems concluded that “In terms of scalability, there is a clear winner throughout our experiments. Cassandra achieves the highest throughput for the maximum number of nodes in all experiments” although “this comes at the price of high write and read latencies.”
Kafka
The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. The design is heavily influenced by advances in the area of transaction logs, e.g database commit logs. Messages are persisted on disk and replicated within the cluster to prevent data loss. Each broker can handle terabytes of messages without performance impact.
Kafka is designed to allow a single cluster to serve as the central data backbone for a large organization. It can be elastically and transparently expanded without downtime. Data streams are partitioned and spread over a cluster of machines to allow data streams larger than the capability of any single machine and to allow clusters of co-ordinated consumers.