URLs – Following the Trail of Associative Thinking
URLs – Following the Trail of Associative Thinking
by SlashDB team.
We all understand that the human mind does not operate in a linear fashion. Despite this, people routinely rely on linearly arranged materials (reports, spreadsheets, articles, etc.) to review or study new information. Such materials are often organized into sections on individual topics, with each section consisting of paragraphs featuring a specific idea (effectively building a plodding, linear structure). This is antithetical to the associative nature of the human mind. It is only natural, then, that throughout history we have dreamt of machines that would one day allow us to review information and data in multilinear and tangential fashions.
“As We May Think” Is How We Really Think

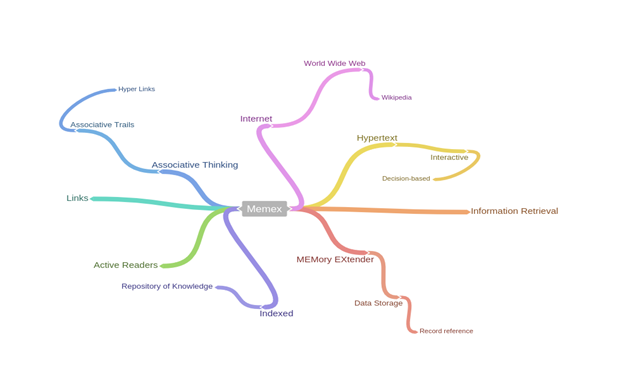
In 1945, Vannevar Bush published his renowned article, “As We May Think,” in which he discusses the associative nature of the human mind. Bush also wrote at length about the inadequate structure of data storage and his vision for a machine, the Memex (Memory Extender) that would mirror the associative qualities of the human mind while also relieving people of the burden of scouring through endless indexes for information. Bush maintained that the human mind “operates by association” and that once we grasp an idea, our minds “snap instantly to the next [idea] that is suggested by the association of thoughts, in accordance with some intricate web of trails carried by the cells of the brain.”
Bush’s admiration for the power of the human mind is evident from the following quote: “the speed of action, the intricacy of trails, the detail of mental pictures, is awe-inspiring beyond all else in nature.” It is natural, then, that Bush would propose the building of a machine that would mimic the abilities of the mind. Bush envisioned the Memex as operating with the speed and associative cap ability of the mind, in other words, a machine that would literally become an extension of memory and thought, stating that “selection by association, rather than indexing, may yet be mechanized.” Bush envisioned the mechanization of association by having the user of the Memex “build a trail” or mind map. This process of joining or linking information was an early call for the need and capabilities of URLs.
ability of the mind, in other words, a machine that would literally become an extension of memory and thought, stating that “selection by association, rather than indexing, may yet be mechanized.” Bush envisioned the mechanization of association by having the user of the Memex “build a trail” or mind map. This process of joining or linking information was an early call for the need and capabilities of URLs.
Data Pointers
There are many disadvantages to traditional data storage – one of the biggest disadvantages being that users must rely on complicated queries to search through linear, tabular data in order to find specific information. Computer memory is even more rudimentary – a contiguous string of seemingly meaningless zeroes and ones. In order to make use of computer memory, natural information gets digitized, transformed programmatically into appropriate data structures and stored as memory. Once this is accomplished, data can later be retrieved and interpreted as program logic at a location address or pointer which must also be memorized.
Data pointers have been used for years (since 1964 to be exact) to improve data retrieval and to help programmers ruminate about data at a higher level of abstraction. A pointer is a value that references or points to another value stored somewhere else within a program memory. Essentially, acting as something of a signpost, allowing users to more easily find the data they want to review. The obvious downside to this method is that the data pointer is limited to data contained within one machine – making building distributed systems problematic.
SlashDB as Your Innovative Solution
SlashDB technology takes the conc![]() ept of data pointers to the next level by using Uniform Resource Locators (URLs) as pointer structured data resources. SlashDB automatically assigns each data resource a URL which allows data to be sourced from one machine to another. This not only helps users navigate data and associate specific pieces of data more easily than ever before, but also allows software architects to think of disparate data in similar terms as if that data were contained within the program’s memory.
ept of data pointers to the next level by using Uniform Resource Locators (URLs) as pointer structured data resources. SlashDB automatically assigns each data resource a URL which allows data to be sourced from one machine to another. This not only helps users navigate data and associate specific pieces of data more easily than ever before, but also allows software architects to think of disparate data in similar terms as if that data were contained within the program’s memory.
For instance, a URL data pointer for a customer table will lead to a pointer for a specific customer within that table, which will, in turn, lead to a specific property of the customer, such as an email address or invoices. Data exposed at this granular level, like small breadcrumbs dropped along a logical path of thought, provide a trail or map that allows programmers to build applications spanning multiple machines. URL data pointers coupled with SlashDB technology sync seamlessly with thought processes and patterns, allowing URLs to perfectly imitate the highly associative nature of the human mind and memory.
SlashDB has made Bush’s concept a reality, and, in doing so, takes his vision of associative technology one step further by creating unique data pointers in the form of URLs for each piece of data – providing associative footholds for the mind to use with the greatest ease possible. SlashDB thoroughly understands that tools which share the same associative capabilities of the mind increase utilization and heighten productivity.
Associative technology melds with the mind, allowing for a rapidity of exploration based on association. This results in an intricate network of relationships that can range from the highly related to the tangential to the most tenuous of connections, all of which can work to create new and novel conceptions of data and data usage.
SlashDB has made it our mission to make data retrieval a highly accessible, searchable, and associative process. If you think our innovative methods will help streamline your business, contact us and we’ll work with you to find the best solution for your needs.
Sponsored by SlashDB.