Many organizations are making the move to cloud-native platforms as part of their strategy for digital transformation. This allows them to deliver faster, user-friendly applications with greater agility. However, the architecture of the data behind a cloud-native transformation is often ignored, mostly because very few definitive guidelines or patterns exist today. Given that data is the information currency of every organization, how do you avoid common data mistakes and gain valuable insight from your data?
We recently discussed these topics during a webinar with Prasad Radhakrishnan, data architecture lead at Pivotal Software. Prasad’s charter is to help organizations make the right data decisions as they plan their cloud-native strategies. Working with many customers throughout their transformation journeys, he’s noticed helpful patterns and best practices that smart data architects use with the cloud-native Pivotal Cloud Foundry® (PCF) and Redis Enterprise data platforms. Here’s a recap of our insightful conversation with him.
1. Farewell, Service Oriented Architecture (SOA). Welcome, Microservices!
While many legacy applications are still SOA-based, the de facto mindset of most developers has changed, and microservice architectures have gained much popularity. Rather than building monolithic applications, developers achieve many benefits by creating several independent ‘services’ that work together in concert.
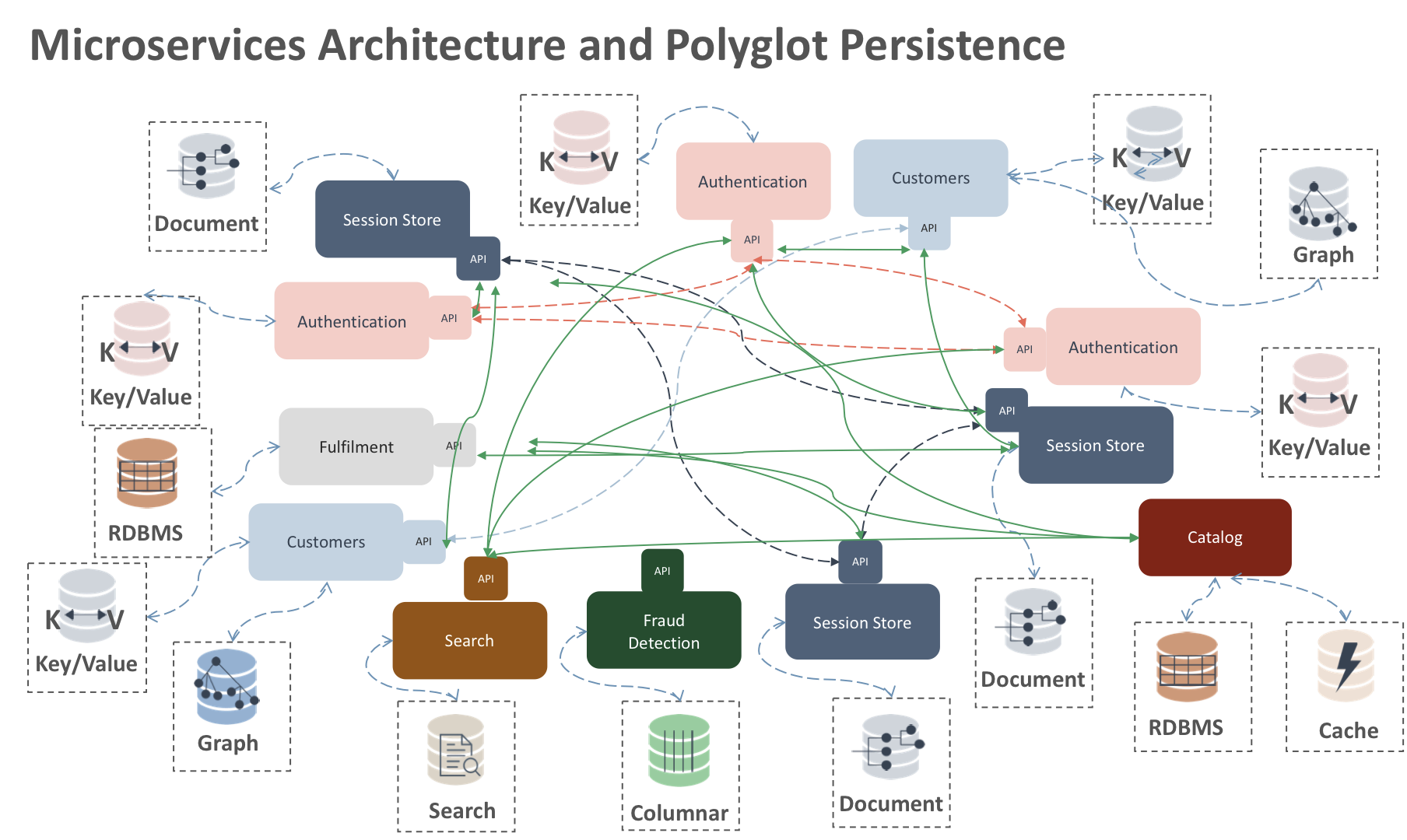
These microservice architectures deliver greater application development agility and simpler codebases. In addition, updates and scaling can be achieved for each microservice in isolation, and they can be written in different languages or connected to different data tiers and platforms of choice. However, this strategy brings a new set of challenges for delivery and operations teams. Through automation and ease of use, cloud platforms like Pivotal Cloud Foundry enable developers and operators to continuously deliver any app to every major private and public cloud with a single platform, which allows application teams to work together much more harmoniously. This type of delivery style and componentized architecture also demands a database platform, like Redis Enterprise, that can support different data types and structures, as well as different programming languages with ease.
2. The 12-Factor App and Cloud Native Microservices
The twelve-factor app is a set of rules and guidelines created to help organizations build cloud-native applications. They serve as an excellent starting point, but when it comes to data platforms, a couple of factors (#4 and #5) need further examination.
#4 – Treat backing services as attached resources: Backing services here refer to databases and data stores for the most part. This means that microservices require dedicated single ownership of schema and the underlying data store.
#5 – Strictly separate build and run stages: This means the application should be executed as one more stateless process, with the state often offloaded onto a backing service — further implying that databases and data stores should be stateful services.
The Redis Enterprise Kubernetes service on Pivotal Container Services (PKS) exposes Redis pods to the Kubernetes cluster, taking advantage of PV, PVC and StatefulSets primitives to
3. Continuous Integration/Continuous Delivery
The proliferation of service processes, in which each service is deployable independently, requires automated mechanisms for deployment and rollback, which is referred to as continuous integration or continuous delivery (CI/CD). Microservices require CI/CD tools and processes, which is why platforms like PCF were purpose-built for continuous delivery. In addition, they support self-service provisioning of data stores.
With Redis Enterprise purpose-built to work instantly on the PCF platform, developers can spin VMs running Redis Enterprise on the fly. Redis Enterprise handles data scaling and monitoring, triggering notices to add shards, re-balance, re-shard or failover if necessary. Solutions like PCF and Redis Enterprise together can reduce some operational burden, so companies are able to spend more time developing and deploying quality software.
4. The Importance of a Multi-Cloud Deployment Model
Enterprises today are adopting a multi-cloud strategy for several reasons: to support disaster recovery, to take advantage of pricing offers from different cloud infrastructure providers, for enhanced security or simply to avoid vendor lock-in. Your application code should be independent of the platform it’s expected to run on. For example, PCF provides “write once, deploy anywhere” capabilities that decouple the application from the infrastructure it is running on. Redis Enterprise on PCF adds to this flexibility by supporting multiple deployment options, allowing users to run it on virtually any popular cloud platform, on-premise, or a combination of the two.
5. Chiseling away the monoliths
Traditional approaches to data access and data movement are time-prohibitive. They usually involve creating replicas of data in the primary data store, in other operational data stores and in data warehouses/data lakes, where data is updated in batches every several hours or days. As organizations adopt microservices and design patterns, delays in data movement across different types of data stores impede agility and accuracy.
Many development teams are incrementally migrating their monolithic applications to a microservices architecture, e.g.the strangler pattern. As they do so, they gradually replace specific pieces of functionality with new applications and services. During this transition, any associated data stores also need to be compartmentalized and componentized — further reason for each microservice to have its own associated data store or database.
The Redis Enterprise service on PCF is built with this dynamic in mind. For instance, Redis Enterprise Modules provide flexible extensibility across any platform and language. This enables newly built microservices to communicate with each other through additional HTTP calls over convenient-to-use REST APIs. In many cases, microservices simply publish events that indicate changes, and listeners/subscribers update the associated applications – this is also easy to do through publish/subscribe in Redis.
6. Fundamental Requirements of a Cloud Native Database
Each of the previous five considerations are important as you think about how to store cloud-native data for your application. In particular, Prasad dove into the following key database requirements every company should consider.
High Performance: The key driver for microservice architectures is the need for modularity, which inherently makes these applications distributed systems. Of course, distributed systems introduce a different set of demands and complexities for application performance. For example, if your app needs to make multiple service calls, some of which return slowly, in order to complete an activity, you end up with a performance hot spot. In addition to architectural remedies, a high performance backing service would go a long way to mitigate this problem. Redis Enterprise recently set new industry benchmarks by linearly scaling to process over 50M ops/sec @ <1msec latency, on only 26 EC2 nodes — serving this need quite nicely.
Active-Active Data Replication: Batch data replication used to be a popular approach, but replication with event store and event sourcing are now gaining a lot more traction for real-time applications. With Redis Enterprise’s built-in support for Active-Active scenarios (using Conflict-Free Replicated Data Types (CRDT) technology), many customers employ these deployment models for:
- Seamlessly migrating data across data centers, so user experience is not impacted;
- Mitigating failure scenarios and managing failover to a second data center to minimize downtime;
- Handling a high volume of incoming traffic and distributing load across multiple servers with seamless syncs; and
- Geographically distributing applications (like a multi-player game or a real-time bidding/polling application) where data needs to be in sync across different geographies.
High Availability Data: Cloud-native app developers should choose their data store based on their Recovery Point Objective (RPO, meaning ‘how much data will I lose?’), Recovery Time Objective (RTO, meaning ‘when an event failure occurs, how long will it take for the service to come back online?’), high availability characteristics, installation topology and failover strategy. Single-node database instances affect not just failure scenarios, but also client downtime events that impact availability, like version upgrades.
Redis Enterprise for PCF supports the high availability requirements of microservice architectures by delivering in-memory replication based on diskless replication at both the master and slave. Additionally, once a failure event is detected, the Redis Enterprise cluster automatically and transparently runs a set of internal processes that failover relevant shards and endpoints to healthy cluster nodes within single digit seconds. It also takes care of rerouting user traffic through different proxies if necessary. Redis Enterprise is designed for data persistence and provides out-of-the-box support for backup and restore services in PCF environments.
Your availability requirements are typically dependant on the criticality of your application. Redis Enterprise for PCF supports various high availability installation strategies for a range of use cases, from internal to mission-critical applications.
Developer Agility: While Redis Enterprise for PCF abstracts the operational complexity of your database, to truly be agile in software development, developers need a database built for flexibility. Redis is the number one most-loved database by developers because it gives them exactly that. Its data structures provide built-in commands that process data optimally. Unlike other databases, applications using Redis can implement complex functionality, such as computing set intersections or range analyses, with simple commands and cleaner and more elegant code.
If you want more details on developing the right data strategy for your cloud-native apps, tune into the replay of this joint webinar with Prasad Radhakrishnan from Pivotal.
In the meantime, if you have questions, don’t hesitate to email us at expert@redislabs.com.
Sponsored by Redis Labs