On InfluxDB new features. Q&A with Rick Spencer
We’ve announced a new series of capabilities for InfluxDB, Flux lang, and Telegraf at InfluxDays 2022 that accelerate application building for developers working with time series data. We put a lot of work into the tooling around InfluxDB the database and really think of it more as a platform with a complete toolset for users.
Q1. You recently announced InfluxDB features at InfluxDays that accelerate application building for developers. What are these new features?
We’ve announced a new series of capabilities for InfluxDB, Flux lang, and Telegraf at InfluxDays 2022 that accelerate application building for developers working with time series data. We put a lot of work into the tooling around InfluxDB the database and really think of it more as a platform with a complete toolset for users. The updated platform components include:
- Flux 1.0. Flux is our native scripting and query language. It’s incredibly powerful, but it does have a learning curve, so Flux 1.0 is all about bringing more collaboration/sharing, as well as stability and flexibility to the language. For example, we’ve introduced capabilities that allow users to easily share and repurpose Flux scripts across disparate buckets and sources, allowing users to do a lot more with a lot less effort. Flux 1.0 also includes a new feature called Flux Editions, which allows users to opt into new features that could otherwise be breaking changes and gives them control over upgrading to new features.
- Telegraf Custom Builder. Telegraf is our open source data collection agent. We announced Custom Builder, which reduces its footprint so it only includes the plugins developers need. This can drastically save space and compute resources, especially when it comes to low-power edge and IoT devices.
- Script Editor for the Query Experience. On the query side, we have revamped our Script Editor in InfluxDB Cloud, which now features a familiar and powerful schema browser, along with the ability to save and load your scripts right in the InfluxDB UI, something our community has been eager for. It also has improved performance when working with large data sets, and, in preparation for the IOx storage engine, supports multiple scripting languages.
Q2. How do these features build on InfluxData’s standing commitments of meeting developers where they areand delivering Time to Awesome?
In everything we build, we always consider:
- Where a developer is in their app-building journey.
- Their comfort level with time series data.
With each of these, the idea is for InfluxData to fit in their world as opposed to forcing them into ours. We go about that by offering a wide range of tools, features, and resources that meet developers on their terms. Whether that means Telegraf plugins for your systems, client libraries in the language(s) you know best, or providing cloud-to-cloud data collection, we want to facilitate as many options as possible to make every touchpoint experience with time series data as quick as possible.
In giving developers so many development tools and functions, we also give developers a customized experience tailored to support their individual preferences so they can quickly get started on building applications with time series data – we call that Time to Awesome.
Q3. This latest set of updates comes on the heels of your biggest news of the year announced last month – InfluxDB IOx.
Yes, last month we announced that we rebuilt the core time series engine using Rust and Apache Arrow. It delivers unbounded cardinality, real-time queries, tiered data storage, SQL compatibility, and so much more. The focus at InfluxData is to enable developers to create increasingly intelligent automated systems powered by time series data. InfluxDB IOx is the engine that makes this all possible.
IOx-powered InfluxDB is truly a game-changer for time series workloads and databases – it removes limits on cardinality and is built to support the full range of time series use cases: real-time applications that rely on metrics, events, traces, and other high-cardinality time-stamped data. IOx also brings SQL to InfluxDB for the first time (a common user request) – this will greatly increase the reach of the platform, more developers, more business users, and more data scientists should feel right at home.
Q4. Collaboration and stability seem to be the central themes in the Flux 1.0 release. Tell us what the new version means for Flux users.
Flux 1.0 is all about making the Flux experience as seamless as possible. On the collaboration side, we’ve introduced a feature called Polymorphism, which essentially allows users to use labels to write Flux scripts that are independent of their data schema. This makes it easier to share and repurpose Flux scripts across disparate buckets, so users can do a lot more with a lot less effort.
We’ve also added Flux Editions to improve stability with Flux. The language itself can have a bit of a learning curve, so Flux Editions ensure users don’t have to update the language if they don’t want to. Our goal here is to give users more granular control over their systems. By providing this kind of control, we can introduce breaking changes to Flux without forcing them on users. In fact, you can have different segments of your systems running on different Flux editions. So, if a Flux feature update is critical to certain aspects of your system, you can choose to only update those. As a result, you can prioritize the stability of your system against the need for new features and capabilities available in Flux.
Q5. What makes Telegraf Custom Builder so exciting for IoT deployments?
It makes Telegraf much more nimble and reduces its size to a much smaller footprint. So for IoT users, that opens a ton of really exciting use cases that weren’t possible before.
Telegraf includes more than 300 plugins written by our community members who are subject matter experts on the data. However, developers rarely need to use each of these plugins and many have limited resources that would benefit from a smaller binary. With Custom Builder, developers can operate Telegraf on a smaller scale that simply was not possible before, so this is really exciting in terms of what developers can do to gain real-time insights from IoT devices and sensors in real-time.
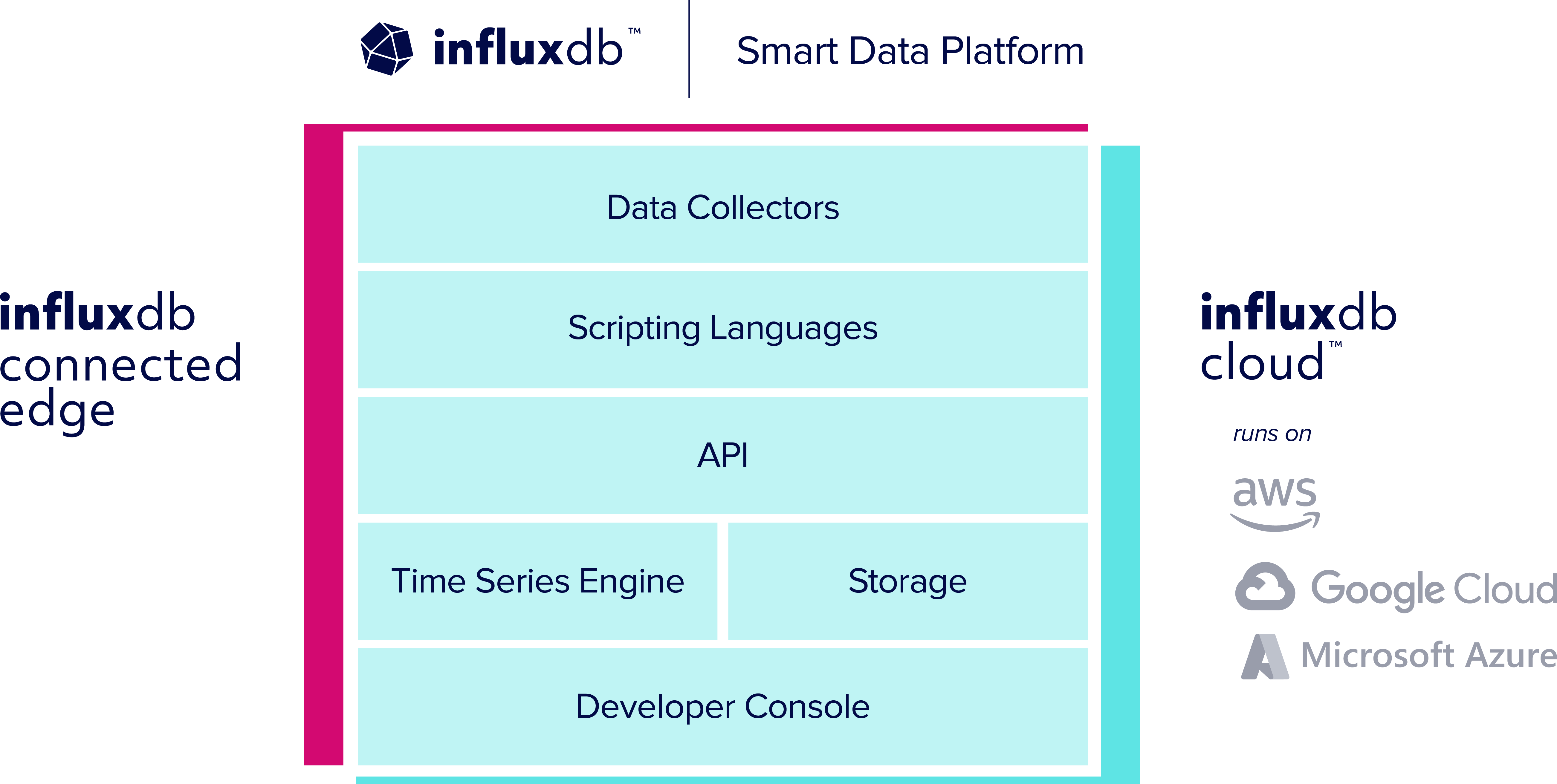
Q6. At this year’s InfluxDays, InfluxData introduced us to the Smart Data Platform. Tell us what that means.
InfluxDays 2022 showcased the next evolution of InfluxDB as the Smart Data Platform: where developers build, integrate, and run time series applications. The Smart Data Platform includes six individual components. Each addresses a particular function, but together, combine to form a powerful, cohesive, and evolving platform that is purpose-built to handle time series data.
The components include:
- Data Collectors
- Scripting Languages
- APIs
- InfluxDB
- Storage
- Developer Console
Q7. What were some of the biggest takeaways for developers at this year’s InfluxDays?
The biggest and most exciting development at InfluxDays was all discussion around InfluxDB IOx and what that means for the future of time series. In our estimation, this is a legitimate game-changer in the realm of time series and time series databases. IOx not only expands the types of use cases that InfluxDB supports, but it ensures that those use cases are performant right out of the box.
While IOx is the core of the platform, the other big takeaway is that InfluxDB is more than just a database. It is, in fact, an entire platform dedicated to time series workloads. We spend a lot of time thinking about how to optimize the platform for the unique characteristics of time series data. These new features really demonstrate our commitment to providing developers with the things they need to be successful with the least amount of effort on their part. And the launch of IOx represents a significant leap forward for InfluxDB – evolving it into a real-time analytics platform.
Q8. Anything else you wish to add?
The future is bright for time series and for InfluxDB. It’s a really exciting time right now with the new InfluxDB IOx engine. This is just the beginning of some really big and potentially paradigm-shifting developments in the world of time series.
We can’t wait to see where it all leads.
………………………………………………….
About Rick Spencer
Rick is the VP of Products at InfluxData. Rick’s 25 years of experience includes pioneering work on Developer Usability, leading popular Open Source projects, and packaging, delivering and maintaining cloud software. In his previous role as the VP of InfluxData’s Platform team, Rick focused on excellence in Cloud Native Delivery, including CI/CD, high availability, multi-cloud and multi-region deployments, and scale.
Currently, Rick resides outside of Washington, DC, where he continues to pursue his interest in developer usability as well as playing with embedded microcontrollers, music, gardening, and video games.

Sponsored by InfluxData.