On Zilliz Cloud, a Fully Managed AI-Native Vector Database. Q&A with James Luan
Zilliz, a leading vector database provider, has just launched the latest update of their fully-managed, AI-native vector database, Zilliz Cloud. This revolutionary update introduces many new features and offerings. Today, we have James Luan, Partner and Director of Engineering at Zilliz, with us to share his thoughts on vector databases and what is so exciting about the latest version of Zilliz Cloud.
Q1. What is a vector database, and how does it differ from traditional databases?
Traditional relational or NoSQL databases store and organize data in structured formats, such as tables, documents, or key-value pairs, making it easy to search and process such data with standard programming languages.
In contrast, vector databases are purpose-built to store and manage unstructured data, such as images, audio, video, and text, in numeric representations, called embeddings, transformed by deep neural networks and machine learning models.
Vector databases are essential for similarity searches using the Approximate Nearest Neighbor (ANN)algorithm. This algorithm is a form of proximity search that finds the point closest to a given point in a given set. Vector databases are useful in semantic search, recommender systems, and clustering analysis, where similarity and distance computations are crucial.
Q2. What are the typical use cases of vector databases? How do vector databases empower LLMs like ChatGPT?
Vector databases are most efficient in cases that include image, video, audio, text, and molecular similarity searching. They are also valuable for recommender systems, anomaly detection, question-and-answer systems, and many more AI-related use cases.
With the rise of AI and large language models (LLMs) like ChatGPT, vector databases have become an essential infrastructure for LLMs and the retrieval augmented generation (RAG).
In LLM deployments, vector databases are crucial in storing the vector embeddings generated during training. By accommodating billions of embeddings representing the extensive training of the LLM, the vector database performs the essential task of similarity search. This search process matches the user’s prompt (the question a user asks) with the relevant vector embedding, ensuring accurate and precise responses.
While LLMs are powerful, they do have a few limitations. For instance, they are pre-trained offline on broad domain knowledge, making the model uninformed of the most recent information and less effective on domain-specific tasks. We can strengthen LLMs using a RAG method to overcome these difficulties. RAG is a language generation model that combines pre-trained parametric and non-parametric memory for language generation. It retrieves data from outside the language model and augments prompts by adding the relevant retrieved data in context. Vector databases are essential to store and retrieve all external data. Therefore, RAG can also be considered a combination of an LLM and a vector database.
In addition, the combination of ChatGPT, vector databases, and prompts is another brand-new AI stack or the CVP stack. We have developed OSS Chat as a working demonstration of the CVP stack. OSS Chat uses various GitHub repositories of open-source projects and associated documentation pages as the source of truth. We convert this data into embeddings and store them in Zilliz Cloud, the fully managed vector searching service built on Milvus, while storing the related content in a separate data store. When users interact with OSS Chat by asking questions about any open-source project, we trigger a similarity search in Zilliz Cloud to find a relevant match. The retrieved data is fed into ChatGPT to generate a precise and accurate response.
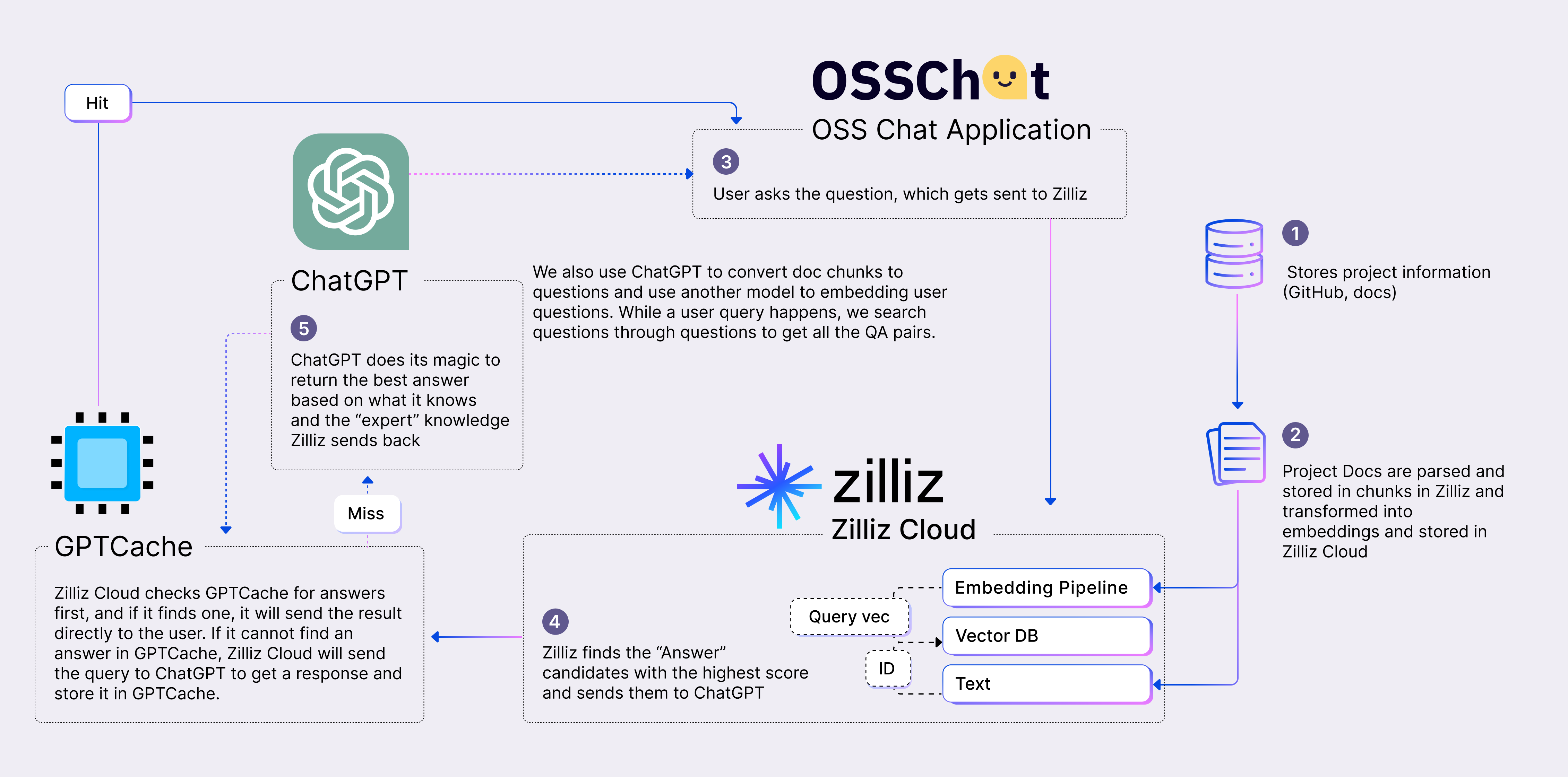
OSS Chat Architecture | Zilliz
In addition, in some cases, LLMs may provide hallucinatory answers due to their limited knowledge base. To address this issue, we can use a vector database to store domain-specific or proprietary facts to update or expand the LLMs’ knowledge base. In other words, vector databases serve as the long-term memory of LLMs.
Q3. What is Milvus? What is Zilliz Cloud?
Milvus is a highly flexible, reliable, and blazing-fast cloud-native, open-source vector database. It powers embedding similarity search and AI applications and strives to make vector databases accessible to every organization. Milvus can store, index, and manage a billion+ embedding vectors generated by deep neural networks and other machine learning (ML) models.
Zilliz contributed Milvus to the LF AI & Data Foundation as an incubation-stage project and graduated in June 2021. Now, open-source Milvus is the industry’s leading vector database solution.
Zilliz Cloud is a fully managed vector search service built on the open-source Milvus. It enables 10x faster vector retrieval, which is unparalleled by any other vector database management system. Recently, we launched our latest update of Zilliz Cloud, introducing an array of new features, offerings, and drastic price reductions.
Q4. What makes the latest Zilliz Cloud so exciting? And why is it accessible to all developers?
The latest Zilliz Cloud is a game-changing release for developers interested in implementing generative AI applications. With more pricing options and valuable features, Zilliz Cloud is now accessible to all developers.
The keyword here is “accessible,” meaning Zilliz Cloud is more affordable, user-friendly, and easier to use and maintain. Accessibility also means significant cost reductions across all user development lifecycle aspects.
Users’ costs consist of development, hardware, and maintenance costs. So how does the latest Zilliz Cloud minimize users’ costs?
Reducing the development costs
Lower development costs mean streamlined development processes, enabling developers to focus on building their applications and avoid unnecessary time expenditure on complex deployments, difficult-to-navigate APIs, and adaptation efforts.
The latest update of Zilliz Cloud introduces many new features that can minimize development costs and relieve the burden on developers. For example, Zilliz Cloud now supports the following:
- Dynamic schema allows users to insert entities with dynamically varied fields into a collection instead of being limited to a predefined static schema.
- The JSON data type allows for more flexible data storage.
- A RESTful interface makes API usage more straightforward and more streamlined.
- Multi-tenant partition keys ensure both efficient queries and data separation for multi-tenant applications.
- Intelligent Index 2.0 eliminates the need to understand complex index types and configurations.
- Access via either API keys or passwords, better catering to developers’ habits.
Reducing the costs of hardware resources
Memory and computation are among the most expensive resources in vector databases because they are computationally and memory intensive. Therefore, minimizing memory and computational costs is crucial to making vector databases more accessible.
The latest update to Zilliz Cloud includes many features to minimize hardware costs, not just in lab testing environments but also in massive production environments.
- The new Cost-Optimized CU has the same storage capacity as the existing Capacity-Optimized CU but is about 30% cheaper. The Cost-Optimized CU is best for users on a limited budget who don’t require demanding latency or query throughput but still want top-tier solutions.
- More pricing options cater to various requirements: Starter, Standard, Enterprise, and Self-hosted plans. Each plan meticulously balances cost, performance, service quality, and compliance, ensuring every user can find a tailored solution that meets their needs.
- Scalar filtering is now faster with vectorization, reducing the time by 75%. Multiple execution plans based on cost evaluation have been available to improve graph connectivity in extensive data filtering, increasing performance by more than 50x in specific cases.
Reducing the maintenance costs
Maintenance costs are a crucial but often overlooked expense. Zilliz Cloud alleviates users’ maintenance concerns, enabling users to concentrate on their core business operations.
- The free serverless tier offers up to 2 collections, each handling up to 500,000 vectors of 768 dimensions or more on a smaller scale. This new offering provides significant data-handling capabilities without requiring extensive infrastructure investments.
- The new Organizations and Roles feature simplifies team access and permission management with fine-grained control over resource accessibility. This feature allows for secure and flexible collaborative workflows, making it especially useful for large organizations with multiple projects and team members needing access to Zilliz Cloud’s vector database services.
- The rolling upgrade feature ensures that users’ systems remain available and responsive to requests, providing a seamless and uninterrupted experience.
For more detailed information about Zilliz Cloud’s new features, see our release notes.
Q5. What can we expect from Zilliz Cloud in the future?
In future releases, we will introduce more features, including:
- Unstructured data processing pipelines
- Support for more complex aggregation functions
- Next-generation scalar query engine and vector retrieval engine
- Automatic scaling instance types
- Global expansion of our services
And more! Stay tuned!
Q6. How to get started with Zilliz Cloud?
There are multiple ways to get started with Zilliz Cloud:
- start for free with the Zilliz Cloud Starter Plan.
- 30-day free trial of the Standard Plan. This plan provides $100 worth of credits upon registration and the opportunity to earn up to $200 in credits in total.
To dive deeper into Zilliz Cloud, consult its documentation or contact one of our engineers for help.
________
Resources
………………………………………………..
About James Luan

James Luan is the Partner and Director of Engineering at Zilliz. With a master’s degree in computer engineering from Cornell University, he has extensive experience as a Database Engineer at Oracle, Hedvig, and Alibaba Cloud. James played a crucial role in developing HBase, Alibaba Cloud’s open-source database, and Lindorm, a self-developed NoSQL database. He is also a respected member of the Technical Advisory Committee of LF AI & Data Foundation, contributing his expertise to shaping the future of AI and data technologies.
Sponsored by Zilliz