Building LLM Apps with 100x Faster Responses and Drastic Cost Reduction Using GPTCache
Building LLM Apps with 100x Faster Responses and Drastic Cost Reduction Using GPTCache
By Fendy Feng.
When building LLM applications, you’ll face two key challenges: the high cost of API calls and slow response times. GPTCache is a perfect open-source solution that addresses these challenges and offers many benefits, including reduced network latency, improved availability, and better scalability.
The magical ChatGPT and other large language models (LLMs) have amazed almost everyone with their ability to understand natural language and answer complicated questions. As a result, more and more developers are leveraging LLMs to build intelligent applications. However, as your LLM application gains popularity and experiences a surge in traffic, the cost of LLM API calls will increase significantly. High response latency will also be frustrating, particularly during peak times for LLMs, directly affecting the user experience.
In this post, I’ll introduce a practical solution to challenges that hinder the efficiency and speed of LLM applications: GPTCache. This open-source semantic cache can help you achieve retrieval speeds at least 100 times faster and cut your costs of using LLM services to zero when the cache is hit.
Key challenges in building LLM-based applications
Before diving deep into GPTCache, let’s first discuss two key challenges when building an intelligent application based on LLMs.
Spiking costs with unnecessary API calls
Applications can leverage LLMs’ powerful inference capabilities by calling LLMs’ API. However, calling the API is not free. If your application is for production and has a large user base, frequent API calls can cost you a fortune. Moreover, you may end up paying for unnecessary API calls for semantically identical questions that the LLM has already answered, wasting your money and resources.
Poor performance and scalability with high response latency
Large language models usually handle jaw-dropping workloads. Take ChatGPT as an example. As of July 2023, it has over 100 million active users and received approximately one billion visits in June alone. Due to such high workloads, LLMs slow down their responses, especially during peak hours, causing applications that rely on them also to slow down.
Additionally, LLM services enforce rate limits, restricting the number of API calls your applications can make to the server within a given timeframe. Hitting a rate limit means that additional requests will be blocked until a certain period has elapsed, leading to a service outage. This bottleneck can directly affect the user experience and limit the number of requests your application can handle.
What is GPTCache?
GPTCache is an open-source semantic cache designed to improve the efficiency and speed of GPT-based applications by storing and retrieving the responses generated by language models. GPTCache allows users to customize the cache to their specific requirements, offering a range of choices for embedding, similarity assessment, storage location, and eviction policies. Furthermore, GPTCache supports both the OpenAI ChatGPT interface and the Langchain interface, with plans to support more interfaces in the coming months.
How does GPTCache work?
Simply put, GPTCache stores LLMs’ responses in the cache. Therefore, when users make similar queries that LLMs had previously responded to, GPTCache searches and returns the results to the users without the need to call the LLM again. Unlike traditional cache systems such as Redis, GPTCache employs semantic caching, which stores and retrieves data through embeddings. It utilizes embedding algorithms to transform the user queries and LLMs’ responses into embeddings and conducts similarity searches on these embeddings using a vector store such as Milvus.
GPTCache comprises six core modules: LLM Adapter, Pre-processor (Context Manager), Embedding Generator, Cache Manager, Similarity Evaluator, and Post-processor.
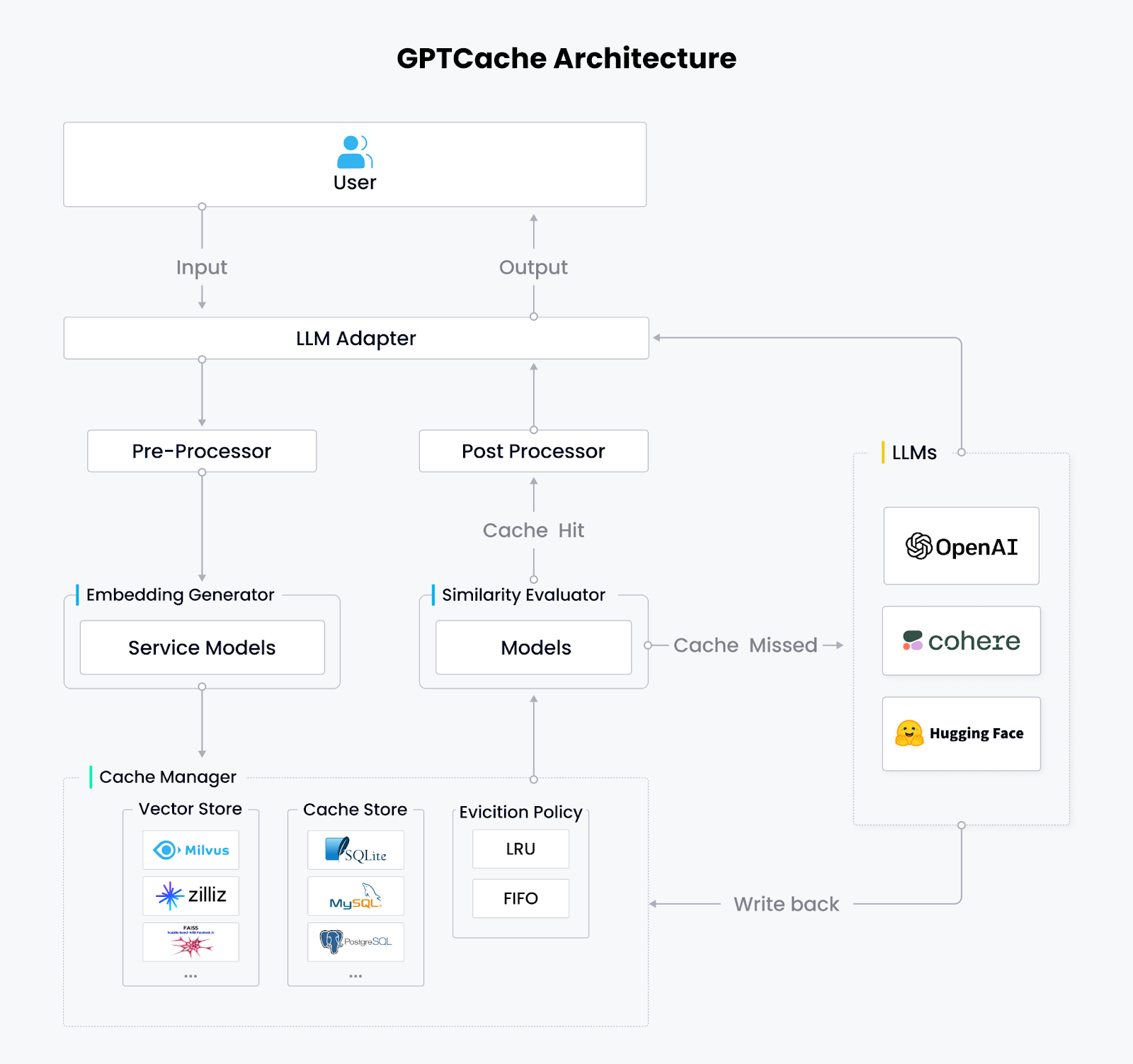
LLM Adapter
The LLM adapter serves as GPTCache’s interface for external interaction. It converts queries into cache protocols, controls the caching workflow, and transforms cache results into LLM responses. With the LLM adapter, experimenting and testing various language models becomes more straightforward, as you can switch between them without rewriting your code or learning a new API.
GPTCache already supports OpenAI ChatGPT API, LangChain API, MiniGPT4 API, and Llamacpp API. Our roadmap includes the addition of more APIs, such as Hugging Face Hub, Bard, and Anthropic.
Pre-processor
Pre-processor manages, analyzes, and formats the queries sent to LLMs, including removing redundant information from inputs, compressing input information, cutting long texts, and performing other related tasks.
Embedding Generator
Embedding Generator converts user queries into embedding vectors using your preferred embedding models. GPTCache supports local models from HuggingFace and GitHub and cloud embedding services for generating embeddings. These include the OpenAI embedding API, ONNX with the GPTCache/paraphrase-albert-onnx model, Hugging Face embedding API, Cohere embedding API, fastText embedding API, and the SentenceTransformers embedding API, and Timm models for image embeddings.
Cache Manager
Cache Manager is the core module of GPTCache. It stores users’ requests and LLMs’ responses and consists of three components:
- A vector store for embedding vector storage and similarity searches
- A cache store for storing user requests and corresponding LLM responses
- An eviction policy for controlling cache capacity according to the Least Recently Used (LRU) or First In, First Out (FIFO) eviction policy.
Currently, GPTCache supports SQLite, PostgreSQL, MySQL, MariaDB, SQL Server, and Oracle for cache storage, and Milvus, Zilliz Cloud, and Weaviate for vector storage and retrieval. Users can choose their preferred vector store, cache store, and eviction policy to meet their needs, balancing performance, scalability, and costs.
Similarity Evaluator
Similarity Evaluator determines whether the cached answer matches the input query. GPTCache offers a standardized interface that combines multiple similarity strategies, allowing users to customize cache matches according to their specific needs and use cases.
Post-Processor
Post-processor prepares the final response to return to the user when the cache is hit. If the answer is not in the cache, the LLM Adapter requests responses from LLM and writes them back to the Cache Manager.
GPTCache benefits
Drastic cost reduction in LLM API calls
LLMs charge for each API call. GPTCache helps developers cache LLM responses semantically for similar and repeatedly asked questions, reducing API costs to zero if the cache is hit. GPTCache reduces the overall number of API calls, drastically reducing costs. It is particularly beneficial for applications with super high traffic.
100x faster in responses
GPTCache can significantly reduce response time for LLM applications. During ChatGPT’s peak times, responses can take up to several seconds. However, with GPTCache, applications can retrieve previously requested answers in less than 100 milliseconds, which is at least 100 times faster. In addition, GPTCache stores
Improved scalability
Caching LLM responses reduces the load on the LLM service, improving your app scalability and preventing bottlenecks while handling growing requests.
Better availability
LLM services often set rate limits, restricting the times your app can access the server within a specific timeframe. GPTCache reduces the overall number of API calls and enables your app to scale quickly to handle an increasing volume of queries. This approach ensures consistent performance as your application’s user base grows.
For more details on how you can benefit from GPTCache, see the What is GPTCache page.
OSS Chat, an AI Chatbot utilizing GPTCache and the CVP stack
GPTCache is beneficial for retrieval augmented generations (RAG), where applications implement a CVP (ChatGPT/LLMs+vector database+prompt as code) stack for more accurate results. OSS Chat, an AI chatbot that can answer questions about GitHub projects, is the best example illustrating how GPTCache and the CVP stack work in the RAG scenario.

OSS Chat’s architecture
OSS Chat utilizes Towhee, a machine learning pipeline, to transform information and related documentation pages of GitHub projects into embeddings. It then stores the embeddings in Zilliz Cloud, a fully-managed vector database service. When a user asks a question through OSS Chat, Zilliz Cloud searches for the top k results most relevant to that query. These results are then combined with the original question to create a prompt with a broader context.
Before sending the prompt to ChatGPT, Zilliz Cloud first checks GPTCache for answers; if the cache is hit, GPTCache returns the answer directly to the user. If the cache is missed, GPTCache sends the original prompt to ChatGPT for responses and stores it back in the cache for future use. GPTCache allows OSS Chat to deliver an excellent user experience with lower costs, lower response latency, and fewer development efforts.
Summary
Building applications based on LLMs is a growing trend that benefits everyone in the ecosystem. However, app developers face two key challenges: the high cost of API calls and the high response latency. GPTCache is a perfect open-source solution that addresses these challenges and offers many more benefits, including reduced network latency, improved availability, and better scalability.
For a hands-on tutorial on getting started with GPTCache, please refer to the GPTCache documentation. You can ask questions or share your ideas during our Community Office Hours. You’re also welcome to contribute to GPTCache.
About the author

Fendy Feng is the Technical Marketing Writer at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
Sponsored by Zilliz.