Smooth Sailing for Data Lakes: Hadoop/Hive + Data Curation
Smooth Sailing for Data Lakes: Hadoop/Hive + Data Curation
Although we’ve debated the risks and benefits of data lakes in past posts, we understand the tremendous appeal for enterprises trying to harness the Big Data Variety opportunity. Today, business users expect fast access to all the data available to them – internal and external data sources – for analytics, and in a free-form, opportunistic way.

The infrastructure technologies for data lakes are readily available: Hadoop (for widely distributed data storage and access), Hive (for querying very large data sets), Spark (for fast in-memory processing) and so on. What’s late to the party are scalable metadata management technologies to keep “free-form” from turning into “a free-for-all.”
Data curation can help most data lakes deliver on their promise by providing downstream analytics tools with the clearest, cleanest and widest view of the data available. It can speed up time-to-analytics while mitigating data chaos.
Remember: data lakes aren’t a new idea. They’re conceptually similar to enterprise data warehouses but more cost-effective, more scalable and less hazardous to IT careers. But far too many enterprise data warehouse (EDW) projects never made it off the drawing board because of the complexity of data integration: basically hand-cataloging, -connecting, and -curating multiple data sets — and repeating this process every time data sets changed or were added. Clearly, trying to apply such techniques to data lakes would be like dumping icebergs in the lake (boats, swimmers and water-skiers take notice).
Unlike traditional data warehousing, the Hadoop architecture promotes late-binding curation, because you are able to store records in their native formats rather than forcing all-or-nothing integration up front. Preserving the native format helps maintain data provenance and fidelity. Business users don’t have to wait for EDW teams to model data and perform heavyweight ETL.
Tamr brings this kind of late-binding curation to data lakes. Here’s how it works:
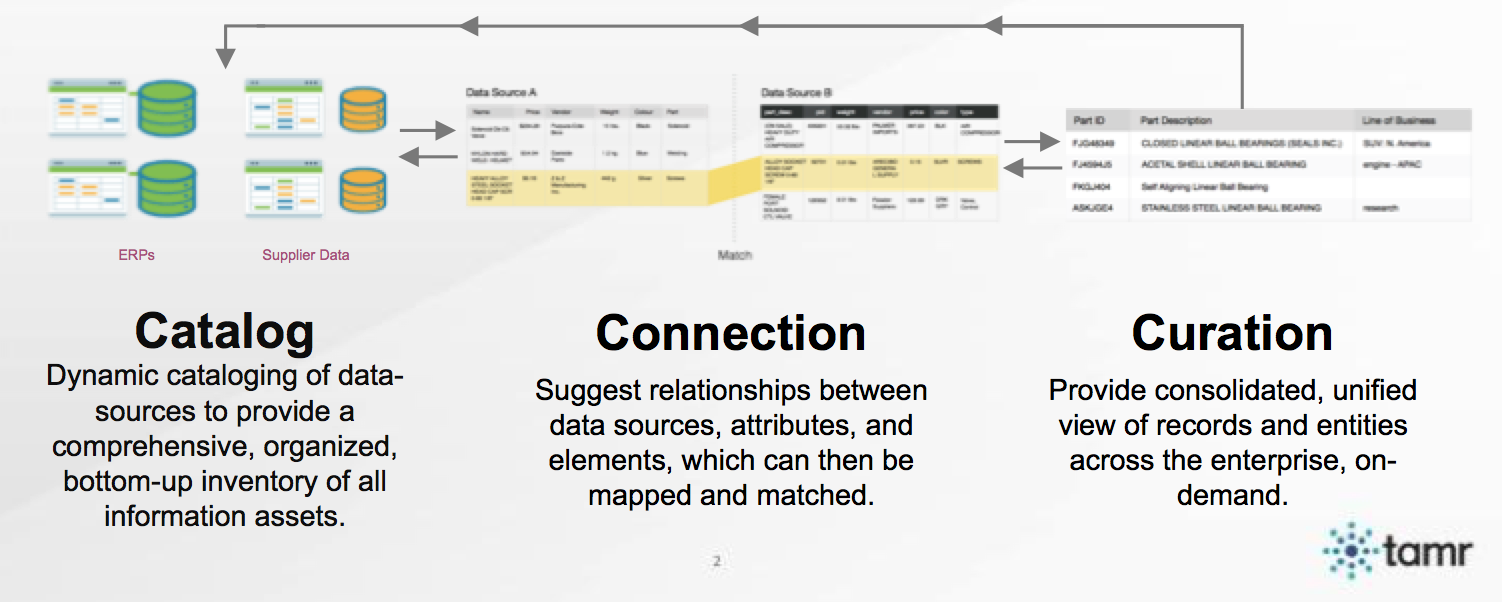
Cataloging: First, Tamr takes a bottom-up, probabilistic approach to automatically catalog all of an organization’s data assets (e.g. discovering attributes vs defining them). Tamr’s data catalog manages a reference map for HDFS/Hive sources alongside all of enterprise data sources (for example, CRM and RDBMS) embracing data variety within Hadoop and beyond.
Connecting: The reference map is developed via machine learning algorithms that suggest relationships between data sources, attributes and elements (look, Ma, no hands).These connections propel curation.
Curation: Curation is the collaborative process (machine and man, but the latter only when necessary) of detecting errors / duplicates and providing consolidated and unified views for core enterprise entities on demand. Tamr’s unified views and linkage data help power ETL, improve source integrity and/or enable more enriched analytics as sources are versioned and published back in the data lake.
Tamr interfaces with structured data in Hadoop through standard JDBC/ODBC interfaces and tools such as Sqoop. With these connectors, Tamr can read from the data lake in order to traverse Hadoop’s data catalog for available data sets for curation. For every dataset Tamr registers, it can give that dataset referential information for more context (unified view).
Tamr can work with transactional/event data, reference/dimensional data and other data formats in the data lake.
For more technical details on how Tamr enables data lakes, download our white paper. Or talk with one of our field specialists.
Sponsored by Tamr.