SQL over Hadoop: Performance isn’t everything…
SQL over Hadoop: Performance isn’t everything…
By Simon Harris, performance and quality assurance architect, IBM
Using SQL to access and analyze data stored on Hadoop clusters is becoming increasingly popular in today’s IT environments. The most common scenario for SQL over Hadoop solutions is Data Warehouse augmentation; where an organization offloads some of their data and workload from their relational data warehouse onto Hadoop. Often, the workload being offloaded consists of older data that is infrequently accessed. Keeping this type of data in an organizations enterprise data warehouse is an expensive proposition and Hadoop provides a highly scalable, but cost effective platform to manage this data. As this blog will show, porting data from a relational warehouse to Hadoop is a relatively simple proposition, but porting the queries can be fraught with danger if the SQL dialect supported on the Hadoop distribution does not support a rich SQL syntax.
Once the queries are ported, it is then important to be able to execute the workload at scale and to provide answers within a timely manner.
The workload we chose to port was modelled on the industry standard relational benchmark TPC-DS, and we chose to name it Hadoop-DS . This blog details the team’s experiences in porting Hadoop-DS to three different SQL over Hadoop vendors—IBM® Big SQL 3.0, Cloudera Impala 1.4.1 and HortonWorks Hive 0.13. TPC-DS typifies the kind of work associated with offloading data from a relational data warehouse to a Hadoop-based platform. While adapting the TPC-DS workload for the nature of a Hadoop system we worked to ensure the essential attributes of both typical customer requirements and the benchmark were maintained.
The first step was to generate 10 TB of data and load this onto each Hadoop cluster using the most optimal storage format for each vendor (Parquet for Big SQL and Impala and ORC for Hive). As with the data movement from a warehouse to Hadoop, this was a relatively simple and uneventful process handled equally well by all three products.
The next step was to port the TPC-DS queries to each SQL over Hadoop distribution using a 1 GB qualification database for result set validation. This process proved much more of a challenge for two of the three SQL over Hadoop distributions. There are 99 queries in the official TPC-DS benchmark and the team attempted to port all 99 queries to all three distributions. Close to a third of the queries ported to Impala needed extensive rewrites, while for Hive close to a quarter of the queries required extensive rewrites. These extensive rewrites were necessary to avoid restrictions in the SQL support for these vendors. Some were considered rewrites that are commonly employed by SQL programmers, but others were much more involved. All in all, we spent approximately four weeks each porting the queries to Hive and Impala.
Since Big SQL supports a rich SQL syntax, it took the team less than an hour to port the 99 queries to Big SQL.
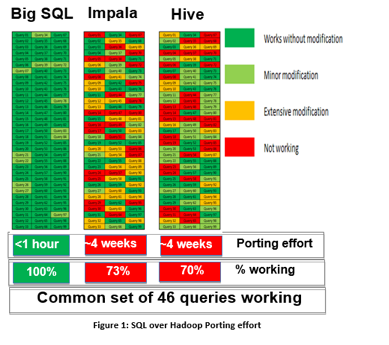
We also found that for Hive and Impala, several queries that worked on the 1 GB qualification database suffered from run-time failures when executed against the larger 10 TB data set. The most common error received on both Hive and Impala was out of memory, followed by queries timing out. Most of the run-time issues with Hive and Impala occurred on the more complex queries which reference several of the TPC-DS fact tables. Several more days were spent tuning Hive and Impala in order to increase the number of queries successfully completing at 10 TB. At the end of an extensive porting effort, we were able to successfully execute 72 of 99 TPC-DS queries on Impala and 69 queries on Hive. Big SQL was able to complete all 99 queries at 10 TB without any additional tuning. Figure 1 summarizes the query porting effort by vendor.
To make the performance comparison as fair as possible, the team took the common set of 46 queries which all vendors were able to successfully execute at 10 TB and used these queries to execute the performance runs.
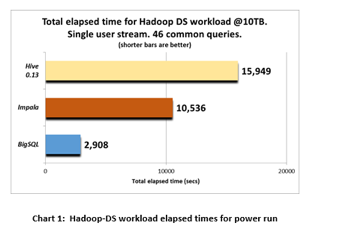
The power query run sequentially executed all 46 queries in the same order across each product. Chart 1 summarizes the elapsed times of the three products executing the 46 common queries.
The results at 10TB show that Big SQL is 3.6x faster than Impala and 5.4x faster than Hive 0.13. This is an impressive result for Big SQL, especially given the fact that many of the long running queries (where Big SQL is strongest) were removed from the workload because Impala or Hive could not complete them.

For the multi-stream throughput run we chose to use four concurrent query streams. We had hoped to use more streams, but our testing showed that the larger the number of streams, the smaller the common query set got. We thought four streams with 46 queries was a reasonable compromise.
The results mirror those from the single stream run and are highlighted in chart 2. Big SQL achieves the highest throughput and has 2.1x greater throughput than Impala and 8.5x more throughput than Hive.
Since Big SQL supports a richer SQL syntax and was able to execute all 99 compliant queries in the workload, the team also executed a single stream and 6 user multi-stream run using the full set of 99 queries from the Hadoop-DS workload at 10TB. Obviously, a comparison with Hive and Impala was not possible using the complete workload, but we did find that Big SQL takes just 2.7x longer to complete the 6 times volume of queries compared to the single query stream run – as illustrated in chart 3.
Finally we scaled the Big SQL data set to 30 TB and ran a power and throughput run (this time with four query streams). Of particular note is the fact that 4 concurrent query streams (and therefore four times more queries) only takes 1.8x longer than a single query stream at 30 TB. Once again highlighting Big SQL’s impressive multi-user scalability – this time at 30TB.

So what did we learn during this exercise? There’s no doubt that both Hive and Impala have come a long way in a short time and both have their strengths. Hive demonstrates very good scalability, and Impala is very good with the smaller, simpler queries. However, it takes many, many years and many millions of dollars to build an enterprise grade database engine. IBM has been able to take advantage of its decades of research and development into RDBMs and reuse much of this in the SQL over Hadoop world to create Big SQL—a truly industrial strength SQL over Hadoop engine. Though benchmarks only represent a portion of real life, we believe the experience of the team in porting a workload from a relational warehouse to three SQL over Hadoop engines provides a reasonable indicator of each products strengths and weaknesses.
Since this was originally a benchmarking exercise, and we are all performance engineers, the team expected performance to be the key differentiator. So it was a big surprise to discover that although performance is important in the SQL over Hadoop world, support for rich SQL syntax is much more significant. As it doesn’t matter how fast you are if you cannot execute all the queries in a workload.
In an effort to be as open as possible we have published a more detailed whitepaper on our experiences with the three products, Blistering Fast SQL Access to Hadoop using IBM BigInsights 3.0 with Big SQL 3.0, and a more formal benchmark report for the Big SQL runs at 30 TB, Hadoop-DS Benchmark Report for IBM Big SQL 3.0. All the necessary information to reproduce the environments and re-execute the benchmarks are provided in these papers.