Optimize your Data Warehouse with Tamr
Optimize your Data Warehouse with Tamr.
By Ihab Ilyas, Professor,
Cheriton School of Computer Science, University of Waterloo
Context
With the growing popularity of Hadoop several organizations have been creating Data Lakes, where they store data derived from structured and unstructured data sources in its raw format. At the same time, they invest in building a Data Warehouse that contains the same data in a schema and format that can be analyzed by a Business Intelligence tool, and used by Data Scientists and Business Analysts. However they struggle with connecting and transforming the data to the right format without significant cost and time investment.
Data Lakes emerge; data curation still required
Hadoop has helped organizations significantly reduce the cost of data processing by spreading work over clusters built on commodity hardware, and the ability to host massive amount of heterogeneous and diverse data sets.
Interestingly, Hadoop systems have been playing a dual roles both as “archival” and “ingest” infrastructure options.
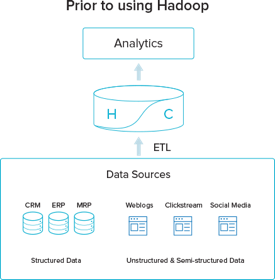
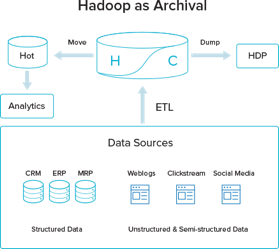
Hadoop as a Cheap Data Warehouse for “Cold” Data
Hadoop enables organizations to avoid putting all data into the DW; instead they can move cold data (data that has not been used for a while) into the data lake as a cheaper alternative to the expensive data warehouse stack. Only clean, curated and “hot” data remain in the DW to cater for the various analytics and applications. While the economy of the solution is well justified, it fails to address the ongoing operation of handling an increasing number of data sources everyday; new data can: (1) Augment and enrich the information of what the organization classifies as hot and operational; (2) Constitute a new data source that need to be fed into the current analytics pipeline; or (3) can be part of the enterprise “Cold” data with no immediate effect on the business Intelligence stack.
Here is the dilemma in using Hadoop as a cheap data warehouse: Data can only be classified as Hot or Cold based on usage patterns in the data warehouse. Classifying new data as “hot” or “cold” cannot possibly happen before this data is fully curated and integrated/linked with the existing data set. Curation is a precursor and a necessary condition for a meaningful analytics., hence curating new data sources before classifying it as important or not is inevitable.
Does that mean we maintain a DW for all data to carry out the integration in a normal ETL manner? Doesn’t that defeat the purpose of a DW only for hot and curated data?
Curation is also very expensive; in fact it almost certainly dominates storage and other optimizations issues.
Imagining that curation can happen on-the-fly while moving data around between the lake and the data warehouse is a huge oversimplification.
Ingesting Data into the Lake; the Case for Continuous Data Curation
Using Hadoop and the concept of data lakes side by side with business intelligence and DW stacks requires fundamental shift on how we see ETL. Hadoop will be the front line in ingesting all sorts of data sources, often in raw and heterogeneous formats. This schema-less or partial schema data often wait in this swamp till heavy-weight ETL processes make sense of it and try to fit in the various analytics schema in the BI stack. Business changes, schema evolution, and various technology upgrades render large chunks of the curation and integration work (The T in the ETL) simply unusable.
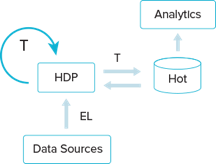
Do we need to fully understand the analytics and the reporting requirements before starting making sense in the growing data in the lake? Can we really afford to postpone integration and curation till we understand the business needs (that might come with timing constraints)?
The lake provides a huge opportunity for a bottom-up continuous curation and connecting exercise that links these bits and pieces all the time. Data curation in the lake can discover relationships and schemas the enterprise itself was not aware of.
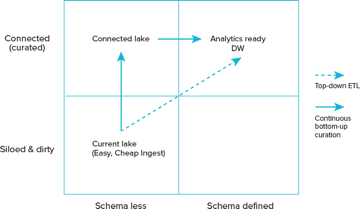
The result is a much smaller overhead and a much cheaper and quicker way to move cold (now curated) data into the hot DW. Data lakes don’t have to be swamps, they can be the opportunity to extract value from data by continuously connecting related pieces and discovering meaningful schemas.