Big data is dead, long live big data
Big data is dead, long live big data
By Rafael Garcia-Navarro, Head of Analytics Experian UK&I
The origin of the term big data is controversial at best, with fervent supporters and equally passionate detractors.
It is common for industries in the midst of a revolution to devise a catchy tagline to rationalise the uncertainty of the change ahead – big data was just one of those examples, but by no means the only one. Another typical example in the digital advertising space was the acronym DMP, or Data Management Platform, that was in effect an attempt to try to articulate to non-technical marketing folks the need for a lambda data architecture to effectively deal with both batch and stream data processing for digital channels to achieve the holy grail – making intelligent data driven decisions.
Whilst personal preferences might drive the use of certain terminology, the reality is that many of the challenges highlighted by the above terms have long been in existence, and their complexity will continue to increase as digitalisation takes a stronger hold in consumer behaviours.
The key change in the industry has not been around the size of data, which has undoubtedly exponentially increased, though financial services and telcos have long dealt with big data before the term was widely accepted. The biggest development has been the democratisation of technology through open source technologies and cloud based environments which have unleashed data processing power previously only available to large multinationals through the use of costly data appliances and mainframes.
This democratisation process has eradicated technological and financial barriers, and has made it possible to capitalise on the opportunities that the processing of data at scale offer for a digital and knowledge based economy.
However, maximising these opportunities critically depend on the ability of organisations to place data at the centre of their culture, and on the implementation of scalable data architectures to manage the complexity and diversity this discipline inherently carries.
So how do we begin the journey?
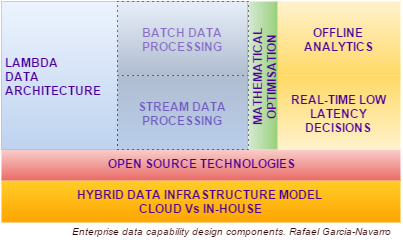
A practical approach is to breakdown the design process into 5 distinct phases:
- Implementing a hybrid data infrastructure model where careful consideration is given to the components of the architecture that can be implemented in the cloud, versus those that need to be deployed in-house – e.g. PII (Personally Identifiable Information) Vs Non-PII data, low latency Vs. batch data processing, etc.
- Underpinned by open source technologies as the foundation of the enterprise data architecture
- To deliver a lambda architecture that operates across the full range of data velocity – i.e. batch and stream data processing
- Supported by a mathematical optimisation capability to deal with one of the most complex statistical challenges – highly multidimensional optimisation problems
- To deliver both offline analytics and real-time low latency decisions
The longevity of the term big data might be open to discussion, although the complexities it has managed to highlight across the industry will persist, and indeed continue to increase, well beyond big data as a marketing tagline is formally declared dead.