Highlights of Big Data Platform Landscape by 2017
Highlights of Big Data Platform Landscape by 2017
BY Donghui Zhang, Architect of Paradigm4
1 Introduction
I recently wrote a blogpost reviewing the landscape of big data platforms. The blogpost can be found here.
This article provides highlights from the blogpost, with the goal to enable the readers to quickly get a big picture of the big picture. While the lessons and opinions from the blogpost are preserved here, many details including URLs are omitted to trade for brevity. Interested readers are referred to the original blogpost for more details.
2 Big Data Overview
Data volume is large and grows very fast. Today the world has 10 billion TB of data. Furthermore, 90% of the data was produced in the past two years. The percentage of job postings that contain “big data” grew by 10X in the past 5 years. There are 20 or so big data roles. People often ask the question “I want to find a big data job; how shall I start?” Knowing the various roles may provide some idea.
Lesson 1: Be familiar with big data roles and responsibilities.
The term “big data” has been used to mean three things. One meaning is “big datasets” or a lot of data. The second meaning is “big data analytics”. The third meaning is the whole “big data stack”.
Big data has five V’s.
- Big Volume means the amount of data is big.
- Big Variety means the range of data types, formats, and sources is big. RDBMS have a small variety as they essentially support a single model.
- Big Velocity means the speed of data in and out is fast. This is particularly useful for streaming applications such as real-time finance. Related to data movement is why past federated databases were not successful: plumbing data movement between systems is hard.
- Value means business value. Building a company is much more than doing technology. When making technical decisions, always have in mind the purpose to increase business value.
- Veracity means correctness. Use a data lake for variety, but don’t let it decay into a data swamp.
Lesson 2: An important feature missing in RDBMS is to support big variety.
Lesson 3: Move query to data, not data to query.
Lesson 4: Do big data for increasing business value; don’t do technology purely for technology purpose.
Lesson 5: Read a book on how to build a startup company.
Lesson 6: Use data lakes, not data swamps; read “Best Practices for Data lake Management”.
Lesson 7: Use reason, not emotion; choose big data only if you need.
Figure 1 shows the overall market caps of selected companies.

Figure 1: selected market caps. (http://finance.yahoo.com 2017-1-3)
- The top three cloud service providers are Amazon, Microsoft, and Google.
- Apple, Oracle, and Samsung recently entered the world of big data platform (Apple “Pie”; Oracle Cloud Machine; Samsung bought Joyant).
- Tencent and Alibaba held world records on Gray sort benchmark in 2016 and 2015, respectively.
- For Hadoop: Cloudera was estimated to worth $5B; HortonWorks has a $0.5B market cap; and Databricks was estimated to worth $0.3B.
Lesson 8: Be aware of the market.
Figure 2 shows the four layers of big data stack, using terminologies from cloud computing.
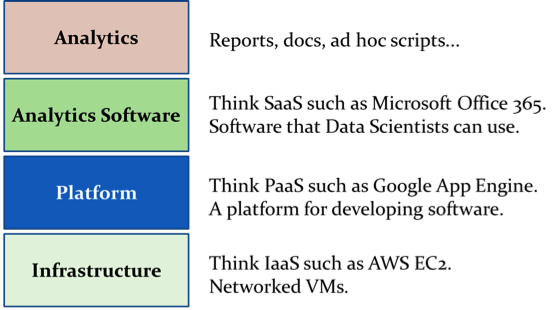
Figure 2: big data stack.
3 Big Data History
Mike Stonebraker said “what goes around comes around.” David DeWitt said “everything has prior art.” To avoid reinventing the wheels without needing to study everything in the literature, one could bookmark a small list of good “meta” resources that do the selection for you.
Below I highlight the big-data history by listing some high-impact milestones, most of which corresponding to articles cited in “Readings in database systems”. For each article, I pick only one author to mention for brevity.
- 1969: relational model (Edgar F. Codd). The relational model is very simple – rows and columns. The impact is, however, very high. Most database systems nowadays use this model. Edgar Codd won the 1981 Turing Award.
- 1976: System R (Jim Gray). It’s been four decades; RDBMS systems are still largely using the System R model. An important legacy is transaction management. Jim Gray won the 1998 Turing Award.
- 1986: Postgres (Mike Stonebraker). In his Turing Award 2014 speech, Mike Stonebraker talked about the similarities between building Postgres and riding a bicycle across America. One important legacy of Postgres is to support extensibility through abstract data types. Another legacy is a generation of highly trained DBMS implementers. Among others, Cloudera’s founder Mike Olston was a key developer on Postgres.
- 1990: Gamma (David DeWitt). Gamma popularized the shared-nothing architecture, which is used by essentially all data warehouse systems today. Like the Postgres project, the Gamma project also trained a generation of DBMS implementers.
- 2004: MapReduce (Jeff Dean). MapReduce disrupted the DBMS landscape. The key legacy from MapReduce is that it revealed the importance of flexibilities in schema, interface, and architecture.
- 2005: One size does not fit all (Mike Stonebraker). Motivated by that famous quote, entrepreneurs have founded a series of startup companies.
- 2006: Hadoop (Doug Cutting). Today the Hadoop ecosystem has evolved to be a >$10 billion market, and continues to grow fast.
- 2011: Spark (Matei Zaharia). Among technologies in the Hadoop ecosystem, Spark is one of the most widely adopted. Cloudera for instance is using Spark to replace MapReduce.
- 2016: AlphaGo (David Silver). An interesting consequence of the big data development is the re-birth of artificial intelligence, which was hot in the 1980s but stayed cool mid 1990s to 2010. One representative milestone was that in 2016 Google’s AlphaGo completely beat top human players for the Go board game. It looks to me that AI and deep learning will only get hotter.
Lesson 9: Don’t reinvent the wheels.
Lesson 10: Read “Readings in Database Systems”. Especially interesting are the editor’s introductions and “Architecture of a Database System”.
Lesson 11: Read selected posts on “HighAvailability”.
Lesson 12: Be familiar with deep learning.
Below is my observation of Mike Stonebraker’s activity loop:
while (true) {
- Talk with the users to find their pain;
- Brainstorm with professors;
- Recruit students to build a prototype;
- Draw a quadrant;
- Co-found a VC-backed startup;
- Play banjo; write papers; give talks; receive awards;
}
Lesson 13: Don’t invent problems; talk to the users.
4 Google Platform
Google is considered the “king of scalability”. It started with a single product with an extremely simple interface: a search box. But it did a search engine really well.
Figure 3 shows Google back in 1997. Figure 4 shows the inside of one of its data centers today.

Figure 3: Google cluster back in 1997. (http://www.slideshare.net/abhijeetdesai/google-cluster-architecture)

Figure 4: Google Belgium data center. (https://docs.google.com/presentation/d/1OvJStE8aohGeI3y5BcYX8bBHwoHYCPu99A3KTTZElr0)
Lesson 14: Do one thing REALLY WELL first.
The basic idea of Google search is simple.
- A web crawler starts with a URL pool, and iteratively downloads the HTML files, parses them, and adds additional URLs to the pool.
- The crawled web pages are ordered using some version of the famous PageRank algorithm.
- The inverted index is built to efficiently retrieve URLs containing keywords that are searched on.
- Hypertext matching is used to decide local orders. The global and local orders are combined.
As a side note for web developers: 60% of Google search traffic came from mobile, and Google demotes mobile-unfriendly web pages.
Lesson 15: Make your web applications mobile friendly.
Google had to build its own platform because no existing databases could handle data at its scale. Today Google has: (a) 130 trillion web pages; (b) 100 PB index; and (c) 3,500 searches per second.
While some other companies view platform as an expense, Google views platform as a competitive advantage, and thinks of itself as a systems engineering company.
Lesson 16: Treat platform seriously.
5 Scale up
Scalability is the capability of a system to handle a growing amount of work. This section discusses “scale up” which means to use more CPU cores in the same machine. It is also called vertical scaling or parallel computing. The next section discusses “scale out” which means to use more machines.
CPU clock speed flattened since 2003. After that, the number of CPU cores continued to increase. There are at least four options how you can use many CPU cores. I believe for server systems Option B2 is the most practical.
5.1 Option A: divide the machine and use a single-threaded system
This option is used by VoltDB and is called NewSQL by Mike Stonebraker.
The advantage is that implementation is simple and the system may be efficient because there is no lock or latch. The disadvantages are: high inter-process communication (especially if there are too many cores), and vulnerable to uneven loads.
5.2 Option B1: use ad hoc threads
This is the most familiar method to programmers who write parallel programs. Your program creates and manages multiple threads so as to make multiple cores busy. Synchronization primitives may be used if needed.
While simpler than B2 and B3, this option may have the following drawbacks: thread creation and management overhead; possibility to either under-utilize the cores (if you create too few threads), or over-utilize.
5.3 Option B2: thread pool + async programing
Microsoft SQL Server’s storage manager is completely async. In general, web servers, database servers, and operating systems all tend to be asynchronous.
This option is to pre-create a thread pool (when the system starts up) with a chosen number of long running threads, each of which iteratively picking the next job in a shared task queue to execute. Your program creates tasks (instead of threads), and pushes them into the thread pool’s task queue. Your tasks will be picked up by some thread asynchronously. The AddTask() service provided by the thread pool typically allows you to provide a callback function, which will be called after the task is completed.
To implement a good thread pool is challenging. But a non-trivial server-side system typically has implemented a thread pool already. Even if you needs to implement one yourself, it will be an “implement once, use many times” thing.
The advantages of this option are that it tends to have a “just-right” number of running threads, to keep all cores busy without overloading them; and it hides the thread creation and management overhead. The disadvantage is that the async programming model can be quite non-intuitive for many programmers.
5.4 Option B3: lock-free data structures
Microsoft SQL Server’s in-memory OLTP (since 2014) was built largely using this option.
There are three principles in implementing lock-free data structures.
- Use atomic CAS.
- Borrow bits to store states between atomic steps.
- Use cooperative threads.
When the number of threads is small, lock-free data structures tend to have comparable performance as their lock-based counterparts. The advantage of this option is that when the number of concurrent threads is very large, the lock-free version is much faster than the lock-based counterpart. The main disadvantage of lock-free data structures using CAS is that they tend to be extremely complicated to implement.
I believe if hardware vendors provide the double-CAS hardware instruction, it can give real hope to a much wider adoption of lock-free data structures in real systems. It will tremendously reduce the complexity of implementation, comparing with that of implementing using only CAS. The double-CAS option may also be better than the more general-purpose STM (software transactional memory) in that STM-based code tends to introduce much larger critical sections.
6 Scale out
“Scale out” is to use multiple machines, and is also called horizontal scaling or distributed computing. Within each machine in a scale-out cluster, scale-up technologies may also be applied.
Designing a scale-out system is challenging.
- Different machines need to talk to each other.
- Algorithm design. Distributed algorithms tend to be drastically different.
- Load balancing. The time to service a request may be determined by the slowest machine.
- Making any joint decision can be surprisingly hard in a distributed system.
- Fault tolerance. When your cluster is sufficiently large, failures are a norm.
- Rolling upgrades are one reason that causes different software/hardware.
- Add/replace machines without bringing the cluster down.
- Cluster monitoring and management. Know what’s going on, and be able to take control.
Scale-out systems can be divided into two broad categories.
- A tightly-coupled cluster is one that supports communications between any pair of machines. Examples include scientific computing, HPC, MPI, and SciDB.
- A loosely-coupled cluster is one that forbids such point to point communications. Examples include MapReduce and Hadoop.
7 My Opinions
7.1 Scale out: tight cluster or loose cluster?
- Tight and loose clusters will co-exist, although loose clusters will continue to dominate.
- Very large clusters (say more than 1000 machines) tend to be loose, and small to medium clusters (say less than 100 machines) tend to be tight.
- The two will embrace each other.
7.2 Analytics: R or Python?
- R and Python will co-exist, although Python will surpass and dominate.
7.3 Platform development: C/C++ or Java/Scala?
- C++ is the way to go.
7.4 Building a company: open source or closed source?
- In today’s market one must be familiar with the open source model and find ways to join it: embrace, leverage, and contribute.
8 Concluding Remarks
I’ll conclude with the biggest lessons I learned from five-year experience working in a big-data startup.
There are at least three APIs for a distributed system: client API, inter-component API, and extension API. All APIs must be carefully designed and maintained. Become an expert on the Pimpl idiom.
Lesson 17: Strive for minimal and clean APIs.
Any distributed system is by nature very complicated. Do yourselves a favor by not adding any additional, unnecessary complexities.
Lesson 18: When in doubt, choose the simpler option.
Especially at the early phase of a startup, it may be necessary to write prototype code. Upon productization it may seem wise and fast to shovel prototype code in and fix problems later on; but don’t do that, period.
Lesson 19: Throw away prototype code.
Wherever you are in the big data stack, there are open-source projects that you can leverage. Pay attention to the open-source world. On the other hand, try to componentize your own product so that it is easy for others to leverage on you.
Lessons 20: Leverage, and be leveraged.