How the Separation of Compute and Storage Impacts your Big Data Analytics Way of Life
By Deepak Majeti, Software Engineer, Vertica R&D
Software and Hardware Trends
The end of Dennard scaling brought significant changes to the hardware and thereby to the software ecosystem. In order to sustain the power envelope, hardware manufacturers have begun to pack multiple low-power homogenous and heterogenous processor cores together. Over this period, I/O devices have also made robust performance improvements.
However, the levels of parallelism/concurrency available in today’s software applications are insufficient to maximize utilization of this modern hardware. To overcome this problem, significant improvements have been made to virtualization and container technologies in order to maximize hardware resource utilization across multiple software applications. This lead to the birth of cloud services that enable sharing of hardware resources among various applications and users. This is also popularly known as Infrastructure as a Service.
Private Cloud vs. Public Cloud
A cloud service can be private (on-premise) or public (AWS, Azure, etc.). The choice of private vs. public mainly boils down to elasticity requirements, utilization, data security policies, and financial resources of an organization. For example, startups in their early stages will prefer a public cloud. Many organization today are increasingly adopting hybrid-cloud frameworks, where part of the data lives on a private cloud and the rest on a public cloud service. It makes sense to keep the less frequently accessed data (cold data) on cheap external public cloud service and the more frequently accessed data (hot data) on premise.
Separate Compute and Storage
Data analytic platforms involve two main components namely Compute and Storage. The Compute handles the analysis logic of an application. The Storage is mainly responsible for keeping the data always available when requested by the Compute. In traditional data analytics platforms, these two systems are deeply coupled. Specifically, the Compute has complete control over the location, partitioning, and ordering of data in the Storage. In other words, the Compute optimizes the data layout according to its performance needs.
Modern data analytic application needs have significantly evolved in the last decade. Systems today are expected to handle orders of magnitude more data. The methods used to analyze this data are diverse and are expected to interplay with each other to obtain the final result. For example, a simple and common analytic application is to stream log data through Kafka that is then pipelined to Vertica for further analysis. In this scenario, a single compute engine cannot have total control over the data layout and the file-system. Therefore, these modern analytic applications require the Compute to be decoupled from the Storage.
Challenges due to Separation
In the decoupled world, the Storage is essentially a third-party application for the Compute. This introduces some performance challenges to the computing platform some of which include, data locality, external storage API, and behavior, increased serialization/deserialization, implementing security, and sharing of hardware resources. Concurrency / Parallelism and performance are constrained due to these challenges.
Vertica Innovations for Separating Compute and Storage
Vertica R&D identified solutions for the aforementioned challenges posed by separating the Compute and Storage. Vertica’s strengths lie in being one of the early adopters of column-store technology and it’s related compute optimizations. Column-store data formats have now become the de-facto standard for data analytical platforms. The insights gained over more than a decade helped optimize Vertica to handle modern shared storage platforms such as HDFS, MapR-FS, S3, etc. Vertica can now play the role of a coupled system as well as that of a computing platform capable of handling various storage platforms.
Being able to efficiently read data from a file system is key to maximize performance. In order to achieve this goal, Vertica implemented optimizations for separate Compute and Storage some of which are described below:
Optimized File Formats and Storage Connectors
One of the important components required to efficiently read data are the file-formats and the connectors used to communicate with the file systems. In collaboration with the Apache Software Foundation, Vertica engineers developed the Apache ORC and Apache Parquet C++ libraries. Orc and Parquet are column-store file-formats that are supported by most data analytical applications today. Vertica engineers further developed the Libhdfs++ library to asynchronously communicate with HDFS. Libhdfs++ is a lightweight C++ library that is capable of supporting asynchronous and concurrent access to HDFS. The asynchronous capability is required to support another important optimization namely overlapping communication with computation, which is described below. Libhdfs++ will soon be available as part of the Apache Hadoop release.
Avoid Communication or Overlap Communication with Computation
Data analytics applications can avoid communication by reading only data that is required. The operations include column selection, predicate pushdown, and partition pruning. Communication avoidance is achieved by pushing the columns required, and predicates if any to the layers that involve scanning of data from the Storage. The Compute can further avoid reading data by taking advantage of the cardinality, sparsity, and sort order of the values.
After the data is pruned, the resultant communication must be overlapped with the computation in order to hide the latency. Vertica achieves this with the help of parallel and concurrent compute operators and asynchronous communication libraries such as Libhdfs++.
Minimize Communication Latency
Another important component of efficient data access is to reduce the communication latency. Depending upon the behavior exposed by the Storage, the computing platform can reduce communication latency by exploiting locality and/or caching. Certain file-systems like HDFS expose API to list the locations of data blocks that are requested by the compute engine. This information is used to push the compute tasks closer to these storage locations. The Vertica planner uses efficient heuristics to balance locality and load balance across all the computation nodes. On file-systems such as S3 where exploiting locality is not possible, frequently accessed data like file metadata is cached to reduce the latency. Object stores like S3 are particularly hard to optimize since load balancing objects can get complicated.
Performance Impact
Now let us understand the performance implications of separating Compute and Storage. We compare the performance of the Vertica coupled mode (aka Enterprise mode) vs. Vertica as a compute platform over HDFS and S3 filesystems. We ran 99 TPC-DS queries over 3TB data on each of these versions. The Vertica enterprise system used Vertica’s proprietary ROS file-format. The file format used on HDFS and S3 is Parquet. The hardware used is 5 node cluster consisting of HPE ProLiant DL380 Gen9 servers. Similar hardware is used to evaluate S3 on Amazon AWS.
The chart below shows the slowdown factor on the x-axis and the query count over the y-axis. The queries have been classified based on the slowdown factor. The first pair of empty bars shows that none of the queries that ran over S3 and HDFS are faster compared to the coupled system. The second pair of bars shows that 37 queries on HDFS and 22 queries on S3 perform 1x to 20x slower. The third pair of bars shows that 49 queries on HDFS and 19 queries on S3 perform 20x to 40x slower. The fourth pair of bars shows that 13 queries on HDFS and 31 queries on S3 perform 40x to 60x slower. The final bar shows that 27 queries on S3 perform slower in the range of 60x to 80x.
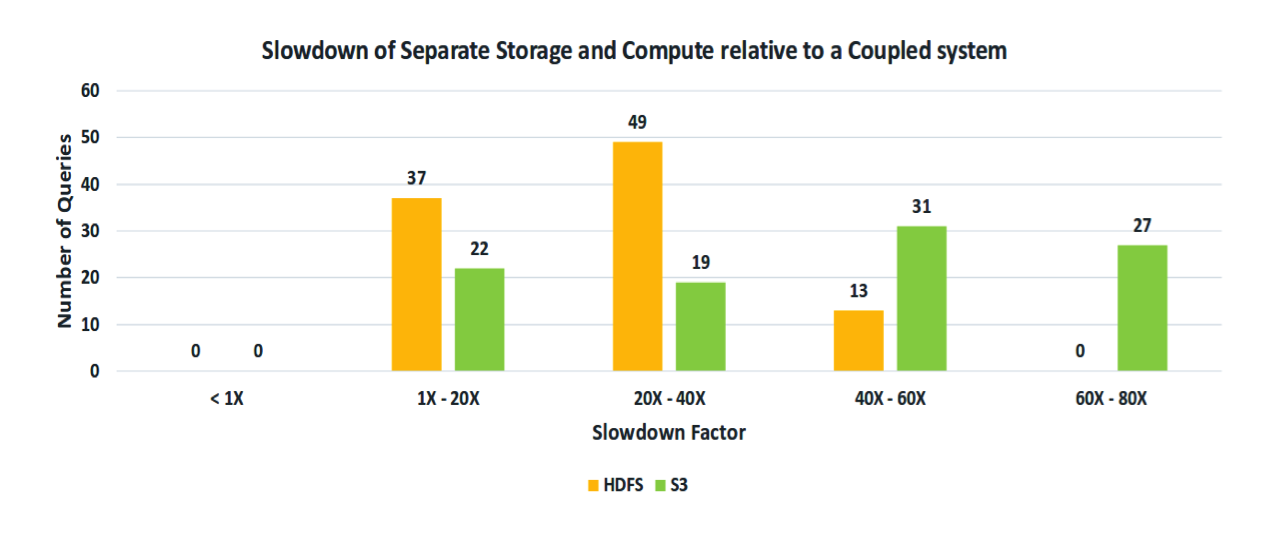
A coupled system such as Vertica Enterprise will always be at an advantage because it has total control over the Storage, which will enable it to exploit locality, data layout, and efficiently load balance, all of which are crucial for performance.
Conclusion
With the end of Dennard scaling and near of Moore’s law, hybrid cloud frameworks are here to stay. Large volumes of data being generated from diverse sources and the types of analysis used today are causing the analytical applications to shift from coupled systems towards separate Compute and Storage. However, this separation introduces significant performance challenges. Vertica R&D made several contributions that simplify these challenges. Evaluation of these contributions on industry standard TPC-DS benchmarks shows a performance slowdown of not more than 80X between a coupled system vs. separated Compute and Storage.
This article has been previously presented at the Strata Data Conference, New York, 2017.
Url: https://conferences.oreilly.com/strata/strata-ny/public/schedule/detail/63400
Sponsored by Vertica