On Automating InfluxDB Deployments at the Edge with balena: Q&A with Marc Pous and Jay Clifford
Q1. What is the business of balena.io?
Marc: At balena we help our customers deploy and manage Internet of Things (IoT) devices across the globe. The mission of balena is to unlock the promise of physical computing by reducing friction for fleet managers.
If you ever heard about the over-the-air updates that happen on phones or embedded devices, this is one of the key things that we do at balena. balena.io allows IoT companies to monitor the health and performance of their devices, deploy new software and hostOS updates to them, and connect a variety of hardware devices.
Currently at balena.io we are working with hundreds of companies worldwide, helping them to manage their fleets of IoT devices.
Q2. What are the main challenges in managing IoT devices?
Marc: Nowadays (in 2023), companies still face several challenges in managing IoT devices. For instance, they need to select the right datastore and hardware based on the constraints of their product(s). They must also select the right connectivity for their devices and simplify development workflows to manage the fleet of devices at scale.
Jay: When you think about it, sources of data in IoT are everywhere. They could be sensors on a wind turbine, solar panels on a roof, temperature gauges in a smart agriculture field, or sensors and gauges in a connected car. Now multiply all that data by time intervals (e.g., seconds, minutes, etc.) and that’s a lot of data! You are now facing pure volume challenges. This massive amount of data creates workloads that are a challenge to store and most incumbent DBs can’t handle them.
Marc: One of the objectives of balena is to allow developers to reprogram IoT-embedded devices in the same way they can fix a bug on a website. This is why balena wants to take advantage of modern tools, such as containers, continuous integration, and other DevOps and web developer tools, and bring them to the embedded IoT world.
Q3. How does balena use Linux containers and other cloud technologies to build IoT connected devices?
Marc: We use Docker and the core functionality of containers to manage software updates to embedded and industrial devices. Actually, balena.io (resin before) first ported Docker to ARMv6 and Raspberry Pi in 2013.
We think that containers are essential to bring modern development and deployment capabilities to IoT-connected devices. Linux containers, particularly Docker, offer — for the first time — a practical path to using virtualization on embedded devices without heavy overhead or hardware abstraction layers that get in the way.
Jay: I think this is why InfluxDB OSS and balena work so well together. We always optimize our releases for container deployment. We expose configuration parameters via environment variables and configuration files to provide dynamic deployment capabilities.
Q4. Can you please explain how developers are able to use containers and pull IoT sensor data from a variety of different single board computers into balenaCloud?
Marc: As mentioned before, our goal is to bring the core devops paradigm into the embedded world. To achieve this, we have a suite of products that allow developers to use different types of single board computers on their fleets running under the same source code, such as x86 devices, NVIDIA Jetsons, Raspberry Pis, and many more.
balenaCloud is the fleet management tool that allows fleet managers and developers to monitor their devices’ status and activity remotely and in real-time. Furthermore, balenaCloud allows developers to remotely deploy new applications on a subset of devices, and to configure and troubleshoot individual devices.
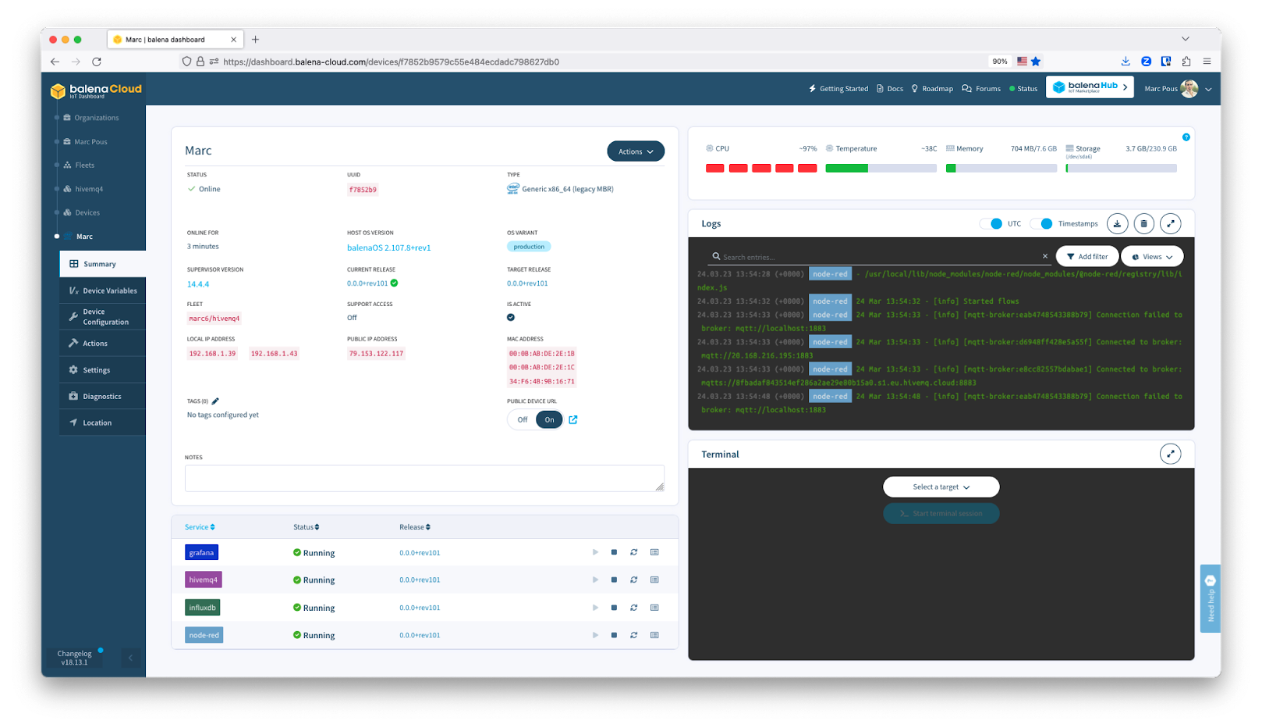
Q5. What does it mean to use balena.io to automate InfluxDB deployments at the edge?
Jay: What we have seen over the years, and with the expansion of IoT, is that developers use InfluxDB to manage high-volume data workloads near their source at the edge. As a single-node, it is easy to deploy InfluxDB at the edge and to utilize its full capabilities right at the source. This provides engineers and developers with the insights they need in real-time. However, once you are scaling to hundreds or thousands of devices, using a tool like balena makes the deployment scalable and maintainable.
Marc: Once you push a project into balenaCloud through the `Deploy with balena` buttons or using the balenaCLI with `balena push <fleet name>`, your code is built in an environment that matches the devices in your fleet. That means that any device belonging to that fleet will deploy the latest version of the software released (if devices are not pinned to a specific release).
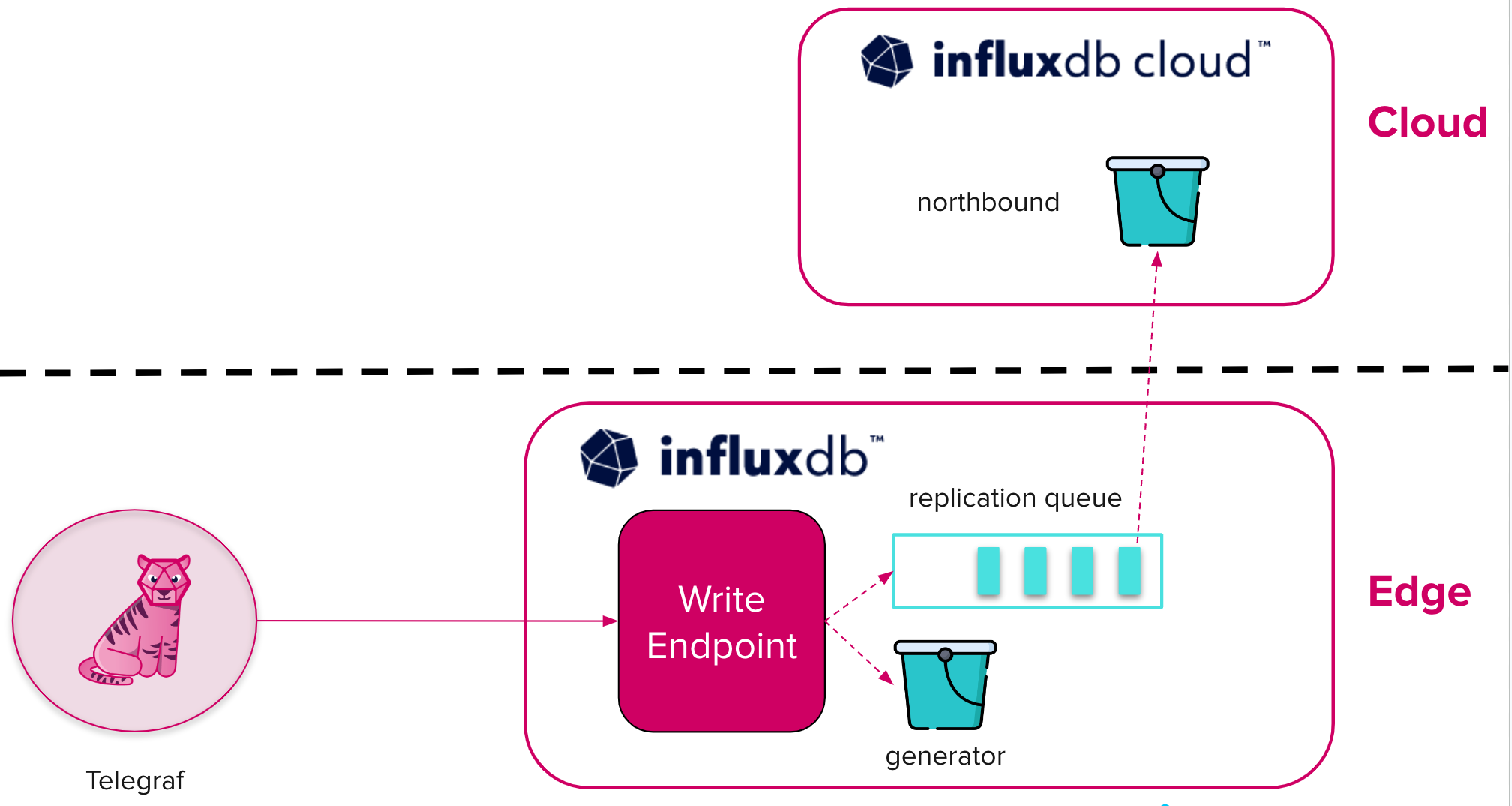
This process allows you to deploy software to hundreds, thousands, or millions of devices in a really simple way. To give you an example, on the balenAir project we automatically deployed InfluxDB (latest version) and Telegraf to multiple devices. We also used Device Variables (or fleet variables) – without accessing any specific devices – to automate the Edge Data Replication feature for InfluxDB instances running at the edge. This feature creates a durable queue for sending data from edge devices to instances of InfluxDB Cloud.
As mentioned above, balena’s goal is to simplify how to manage large fleets of IoT devices deployed all around the world.
Q6. How did balena use Telegraf to create its own application that customers can use?
Marc: At balena we liked Telegraf. However, we wanted to reduce friction for developers when they needed to add or modify configurations. This is why we created the concept of balena Blocks.
The balena Blocks are pre-built container images that developers can add to their multi-container applications to provide useful functionality. The main goal of the block is to reduce the friction of creating IoT apps and to enable rapid prototyping and development.
Answering the question, the balenaLabs team created the `connector block`. The connector block wraps Telegraf in code that discovers and connects data sources and sinks. For example, the connector block will find an MQTT broker running on the device and subscribe to the `sensor` topic. An application developer can simply send JSON-formatted data to this topic and the connector will ingest it. Similarly, the block will find an instance of InfluxDB running on the device and send any ingested data to it. All of this occurs without changing any configuration files and instead uses environment variables to bring other data sources or sinks both on the device or externally hosted.
Check more possibilities of the connector block here and feel free to contribute.
Jay: I think it’s great to see others building on Telegraf like this. Telegraf has always been an open source tool to fill the need for collecting event and metric data. It has grown to over 300 plugins by an extremely active developer community. Dynamically creating Telegraf configs to configure Telegraf has been a popular topic since the inception of the project. balena’s collector app lays the groundwork for what this type of automation could look like.
Q7. Can you share some practical tips and tricks on how to use balenaCloud to automate InfluxDB deployments and Telegraf configurations?
Marc: The first example that comes to my mind is the MING stack (MQTT, InfluxDB, Node-RED and Grafana). The MING stack is an educational project inspired by the LAMP stack (Linux, Apache, MySQL and PHP) from the 2000s. When the World Wide Web was exploding into developers’ consciousness, LAMP came to answer a set of challenges that the web development community were facing. Today, the embedded and IoT world are facing parallel challenges. This is why we think that the MING stack can enable the next generation of IoT application developers.
Sadly, the MING stack is using InfluxDB v1.7.11 to make it compatible with devices running ARMv32 and ARM aarch64 processors.
To deploy IoT projects using balena.io just click the button `Deploy with balena` or run `balena push <your fleet’s name>` with balena CLI to push the code to your fleet. Then click `Add Device`, download the balenaOS image, and flash a SD card with that OS image downloaded from balenaCloud. Once you power up your device with that SD card, enjoy the magic 🌟Over-The-Air🌟 as balena deploys the latest release on your device. There is no trick.
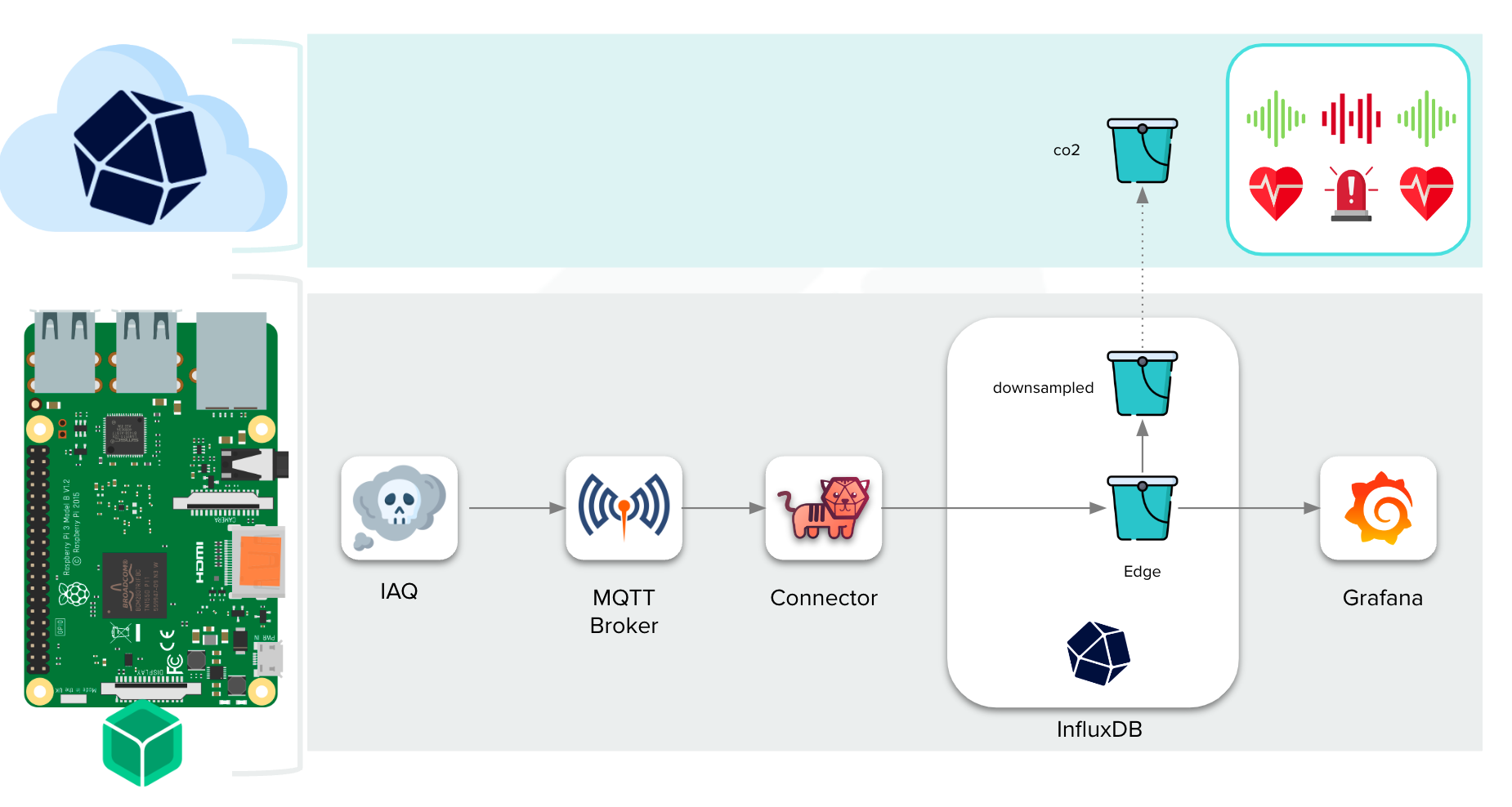
On the other hand, if you would like to deploy the latest InfluxDB release and try the new Edge Data Replication feature then head to the balenAir project that I mentioned earlier. balenAir is a project that builds an indoor air quality sensor using a Raspberry Pi and some Adafruit sensors (PM2.5 and CO2). Adding the `REPLICATION` device variable on balenaCloud enables the replication feature from the edge InfluxDB instance to InfluxDB Cloud, so you will need to define the `INFLUXDB_CLOUD_BUCKET_ID`, `INFLUXDB_CLOUD_HOST`, or the token, among others, as device variables (or fleet variables).
Feel free to follow the instructions from here https://github.com/InfluxCommunity/balenair/blob/master/docs/03-software-setup.md
Jay: Edge Data Replication offers an excellent method for consolidating data from various edge sources into a single central location, such as another OSS node or InfluxDB Cloud. As your next step, I highly recommend exploring InfluxDB Cloud in conjunction with the Arrow Task Engine repository. This combination lays the groundwork for a time series analytics engine, allowing you to perform tasks like anomaly detection and forecasting on your consolidated edge data.
Q8. How do you collect sensor data and push it to InfluxDB Cloud for analysis?
Marc: Getting deeper into the balenAir project, if we check the `docker-compose` from the project we will see the different containers running.

The container `iaq` is in charge of getting the sensor data from the i2c qwiic connectors and the sensors using Python. Once the sensor data is collected, it sends the data through MQTT to the topic `sensors`.
As you can see there is a service called `connector`. This is the balena Block based on Telegraf that we explained before. It is automatically configured to get data from MQTT through the `sensor` topic and store it on InfluxDB. In this case on the `InfluxDB2` service.
Finally, all of the data is visualized on the `dashboard` service which is another balena Block based on the Grafana service.
Another way that I have used to push sensor data to the InfluxDB database is using the Node-RED service with the InfluxDB nodes (out and batch).
…………………………………………

Marc Pous
Developer Advocate, balena
Marc is currently the balena.io Developer Advocate. He has more than 15 years of experience connecting things to the Internet. Marc is also a co-founder of the IoT Coffee Talk podcast. He is also responsible for managing the IoT communities in Barcelona, organizing meetups and inviting up-and-coming IoT companies to present their products. Furthermore, he is responsible for co-organizing the international event IoT Stars during the MWC at Barcelona. His advocacy efforts for the Internet of Things and his stature (6,9 feet) has earned him the nickname IoT Giant.
………………………………………………

Jay Clifford
Developer Advocate, InfluxData
Jay Clifford is a Developer Advocate for InfluxData. Before joining InfluxData he previously specialised in solving industrial pain points using Vision AI and OT connectivity. Jay now uses his experience within the IoT and automation sector to enable developers and industrial customers alike to realise the potential of Time Series data and analytics.
Sponsored by InfluxData