The Cost Benefits of Serverless Graph Databases. Q&A with Brad Bebee.
” We see customer usage of graph databases growing rapidly. Companies are using the relationships in their data to transform their businesses.”
Q1. Since we last spoke about graph databases, what has changed?
A1. Over the past year, many new features and enhancements have been delivered to our Amazon Neptune customers with one of the most exciting being a new serverless deployment option. Neptune is the 7th AWS database service to offer serverless which yields dual benefits. The first benefit is cost optimization where customers only pay for the capacity used as the workload grows and shrinks. This is perfect for test, development and production workloads as customers can realize up to 90% cost savings as compared to peak capacity provisioning. Secondly, Neptune serverless instantly scales as a customer’s queries and workloads change, providing fine-grained incremental capacity. Serverless really helps customers with applications that are seasonal, spiky, or hard to predict. The net/net is that customers no longer have to manage database capacity and can run graph applications without the risk of higher costs from over-provisioning or not enough capacity from under-provisioning.
Implementing Neptune serverless is as easy as selecting “serverless” from the AWS console.
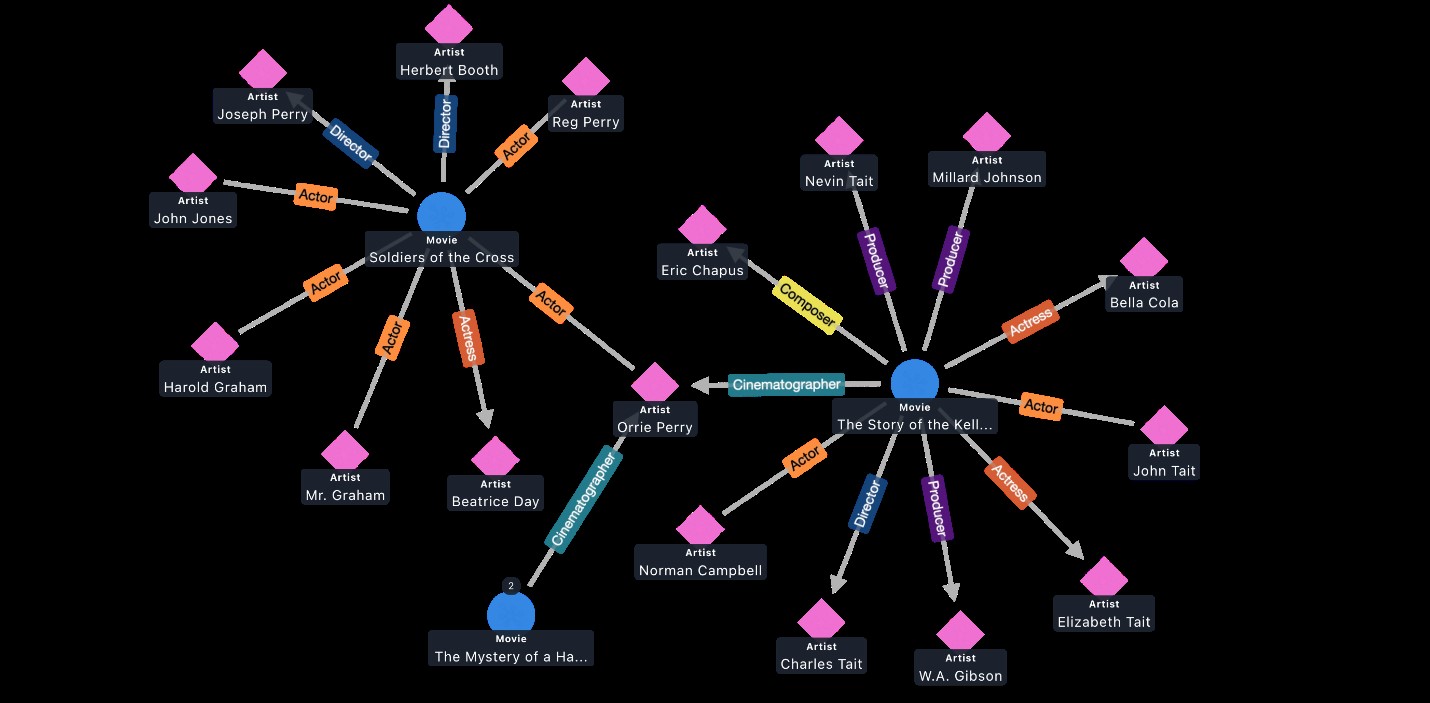
Additionally, in January of this year we introduced graph explorer to the open source community. Graph-explorer is a low-code visualization tool for graph data available under the Apache 2.0 license. This tool provides the ability to browse either labeled property graphs (LPG) or Resource Description Framework (RDF) data in a graph database without the need to write a graph query.
Sample Graph-explorer visualization
We also added Neptune Global Database for globally distributed applications, allowing a single Neptune database to span multiple AWS Regions. With Neptune Global Database, customers can now deploy a primary Neptune database cluster in one AWS Region, and replicate their data in up to five secondary read-only database clusters (with up to 16 read replicas each) in different AWS Regions.
Lastly, another significant and popular feature we added last spring was support for the openCypher query language making it the third open graph query language supported. The previously supported query languages are Apache TinkerPop Gremlin and the World Wide Web Consortiums (W3C) SPARQL 1.1.
Q2. Why serverless over managed? What’s the difference?
A2. AWS has been a pioneer in serverless with introduction of Amazon DynamoDB in 2012 as a high-performance, serverless NoSQL database service.
All of our database services are fully managed. For Neptune, fully managed means many things. First, the initial setup is performed via the AWS Management Console where Neptune database instances are pre-configured with the parameters and settings that support the database instance class the customer selects. This allows customers to connect their applications within minutes with no additional configuration. Second, there is no administrative management overhead associated with Neptune because everything from patching to hardware provisioning and support is managed by AWS behind the scenes. Operation is simplified since customers do not need to create custom indexes over their graph data and Neptune provides timeout and memory usage limitations to reduce the impact of queries that consume too many resources.
Database functions like cloning, bulk data loading, backup/snapshots and replication are simple to execute through the AWS Management Console. Neptune includes support for a broad set of compliances ranging from FedRAMP to SOC (1,2,3). Security includes integration with AWS Identity and Access Management (IAM), encryption and advanced auditing.
Serverless builds upon fully managed by providing capacity on-demand that automatically adjusts database capacity based on an application’s needs. Neptune Serverless can scale graph database workloads instantly to hundreds of thousands of queries. Neptune Serverless adjusts capacity to provide just the right amount of database resources that the application needs, while customers pay only for the consumed capacity.
Customers can use a combination of fully managed instances and serverless with the option of converting existing instances to serverless. I will note that serverless also works with the aforementioned global database, which in itself is an entire discussion.
Q3. Can you give a comparison of the billing methodology of serverless vs. managed?
A3. With Neptune Serverless, customers only pay for what they use. Database capacity is adjusted automatically providing the right amount of resources needed in terms of Neptune capacity units (NCUs). Each NCU is approximately 2 gibibytes (GiB) of memory with corresponding CPU and networking. The use of NCUs is billed per second in increments as small as 0.5.
Since serverless is a great option to optimize costs associated with test and development environments, we have provided a “test and development” template in addition to the “production” template. The template for test and development optimizes costs by not having a read replica while providing access to DB instances that deliver burstable capacity.
We continue to offer customers more traditional provisioned capacity through on-demand instance pricing where customers pay for their database by the hour. Additionally, both serverless and on-demand instance incur database storage billed in per GB-month increments and I/Os billed in per million request increments. For more information including additional chargeable Neptune features, go to the Neptune pricing page and/or the AWS pricing calculator.
The AWS pricing calculator allows customers to create pricing estimates.
Q4. You’ve added openCypher support, why?
A4. Our goal is to provide developers the most choice when it comes to building graph applications. Developers, Data Scientists, and others like openCyper’s syntax which is inspired by SQL, thus providing a familiar structure to compose queries for graph applications. Developers familiar with the declarative style of SQL now have a third option to build their graph applications. We went through an extensive preview release before GA where we “worked backwards” from customer feedback. During this time, billions of queries were run using openCypher on Neptune.
Learnings from our customers drove us to expand the number of supported openCypher clauses such as MERGE, OPTIONAL MATCH, and UNION/UNION ALL. We also focused on the performance and scalability of queries, in particular queries using variable length paths. Last but not least, we added support for parameterized queries using both the HTTPS and Bolt endpoints. This allows customers to use placeholders in queries supporting the use of the same query structure multiple times with different arguments.
I will finish by adding that the Neptune openCypher support works on both new and existing property graphs enabling customers to use both openCypher and Apache TinkerPop Gremlin simultaneously on the same cluster. For Neptune customers using Gremlin, they can use openCypher to query their existing graphs.
Q5. Where do you see the market for graph databases in the future?
A5. We see customer usage of graph databases growing rapidly. Companies are using the relationships in their data to transform their businesses. As an example, Wiz, a fast growing security startup, recently shared how using a graph helps them answer questions that are not possible with other approaches.
It’s still day one for graphs. Today, there are far more customers who can benefit from using a graph than those who are familiar with graph databases, query languages, or data models. When we talk to customers, we hear that customers often don’t care, and, in fact, are impeded by the decisions that they need to make regarding the details of graph implementation, such as graph data models, query languages, and APIs. With Serverless, we’ve taken a big step towards making it easier to deploy and use graphs. There’s a lot more innovation yet to come for all of the ways that customers want to use graphs.
Qx. Anything else you wish to add?
Ax. Serverless represents the future of cloud databases and Neptune serverless delivers an optimized cost model to customers with existing graph applications or those who are building new applications. I’d love to hear from your readers or anyone who wants to discuss serverless graph database by reaching out to me @b2ebs (Twitter). We have a free trial for anyone who wants to get started with Amazon Neptune to start building their graph applications.
………………………………………………

Brad Bebee, General Manager of Amazon Neptune
Brad is the General Manager of Amazon Neptune, AWS’s fully managed graph database service. He believes that graphs are awesome and they help customers use the relationships in their data to gain insights. Prior to joining AWS, he was the CEO of Blazegraph and was an active open-source contributor on the Blazegraph platform. He is a subject matter expert in graph and knowledge representation with experience ranging from the precursors of DARPA’s DAML program to large-scale data analytics. In his career, Brad has served as a CEO, CTO, CFO, managed operating divisions, and performed advanced technology development for commercial and public-sector customers.
Sponsored by AWS