Understanding How Your Data is Stored, Compressed, and Accessed Can Accelerate Data Query Performance
By Gavin Halliday, HPCC Systems
Businesses are using big data platforms to glean valuable business intelligence from the enormous amounts of data they generate. The size of that business data grows exponentially, making it harder for companies to quickly analyze and apply it. Accordingly, many businesses are turning to AI algorithms and data lakes to analyze and store their data.
Data lake developers focus on ways to reduce the time required to access stored data. The primary source of query delays in a data lake is often the need to access data stored on disk, so developers should consider what kind of storage media they’re using and how it affects query times.
Let’s assume data is stored on disks distributed over many compressed blocks or nodes, and the nodes need to be decompressed before data can be read into memory and searched. The process would look something like this:
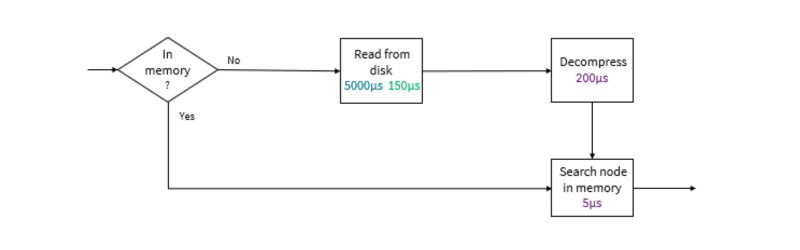
Next, let’s add some typical timings for hard disk and SSD data storage to find the expected time needed to return a match from a node when all nodes are stored in memory and different percentages of the nodes require retrieval from a disk.
| Percentage of nodes in memory | ||||
| 100% | 90% | 50% | 0% | |
| HDD | 5 µs | 525 µs | 2605 µs | 5205 µs |
| SSD | 5 µs | 40 µs | 180 µs | 355 µs |
The search is obviously going to be much faster if all nodes are loaded into memory. Note retrieval time rises sharply whenever access to nodes outside of memory is needed, even with 90 percent of the nodes already in memory.
Because of the enormous difference in time between searching items in memory versus on disk, data lakes often use an internal LRU cache of nodes to read from and index to reduce the search times. This table would seem to show that getting the best performance possible involves making that internal LRU cache as large as possible. But when a query requests data from a file, the operating system doesn’t necessarily read it from the disk. Most data lakes run on Linux systems, and Linux has a page cache that holds all recent data read from a disk. Linux takes advantage of any unused memory for usage in the page cache and evicts items from that page cache if the memory is needed elsewhere. So, the memory used for the Linux page cache competes with the memory for the node cache.
This complicates time/data calculations because while the page cache holds compressed nodes, a data lake’s internal cache can hold decompressed nodes. More compressed nodes fit in the page cache than uncompressed nodes can fit in internal cache. Assuming a file has a typical compression ratio of 1:5, the system has enough memory to store all the compressed data in the page cache, and the page cache has been fully populated, how does that effect retrieval times?
If there is no internal cache and all memory is devoted to the page cache, each search will take 10+200+5 µs = 215 µs (as seen in chart below).
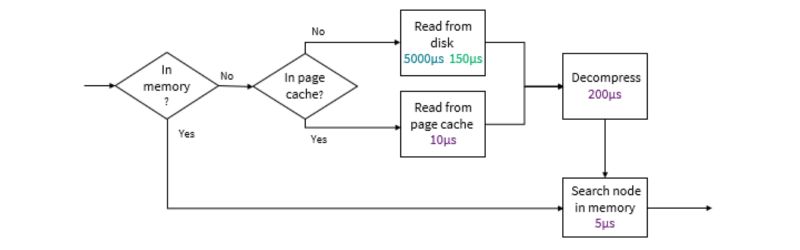
On the other hand, if all the memory is allocated to the internal cache it will only be able to store 20 percent of the data, so 80 percent will need to be read from the disk. The chart below illustrates this.
| Memory | % | Page | % | Disk | % | Total ms | |
| Cached | 5 | 0% | 215 | 100% | n/a | 0% | 215 |
| HDD | 5 | 20% | 215 | 0% | 5205 | 80% | 4165 |
| SSD | 5 | 20% | 215 | 0% | 285 | 80% | 285 |
Interesting to note that query performance is faster when using the Linux page cache for storing data instead of internal cache.
How about 40 percent internal, 60 percent Linux page cache? Because the nodes are expanded by a factor of five, only eight percent will be in the internal cache and 32 percent will need to be read from the disk.
| Memory | % | Page | % | Disk | % | Total µs | |
| HHD 40% | 5 | 8% | 215 | 60% | 5205 | 32% | 1792 |
| SSD 40% | 5 | 8% | 215 | 60% | 355 | 32% | 240 |
What if the node only expanded by a factor of two in memory so more pages could be held in the internal cache?
| Memory | % | Page | % | Disk | % | Total µs | |
| HHD 1:2 | 5 | 20% | 215 | 60% | 5205 | 20% | 1168 |
| SSD 1:2 | 5 | 20% | 215 | 60% | 355 | 20% | 198 |
This comparison reveals a use case where using the internal cache is worthwhile – when the data is not highly compressed. But it only provides a benefit if data is stored on SSDs, not slower performing HDDs. This doesn’t mean that the lower the compression the better performance will be. Rather, poor compression means an index will be even bigger, so a smaller part of it will fit in the Linux page cache. What it does shows is that if you can avoid decompressing data, using an internal cache is faster.
In real-world use cases, data is not accessed uniformly. Some data will be accessed more often. What happens if half of the searches only access one-fifth of the data and all the memory is used for the internal cache?
| Memory | % | Page | % | Disk | % | Total µs | |
| HHD | 5 | 50% | 215 | 0% | 5205 | 50% | 2605 |
| SSD | 5 | 50% | 215 | 0% | 355 | 50% | 178 |
This reveals another case where the internal cache is now providing a benefit.
Finally, as a last thought experiment, what effect would reducing the compression time to 10 µs have?
| Memory | % | Page | % | Disk | % | Total µs | |
| Cached | 5 | 0% | 25 | 100% | n/a | 0% | 25 |
| HHD 100% | 5 | 20% | 25 | 0% | 5015 | 80% | 4013 |
| SSD 100% | 5 | 20% | 25 | 0% | 165 | 80% | 133 |
The chart shows that when reading from SSD, search times are roughly halved, but when reading from the page cache the search time is reduced by a factor of 10. That kind of change would significantly speed up the searches but note the effect on the internal cache performance. The average search time when all memory is allocated to the page cache is now less than a fifth of the time when it is all used for the internal cache, previously it was three quarters.
These comparisons show how optimal internal cache sizes depend on the access patterns within the index, the compression ratio, how fast the storage disk is, and the time needed to decompress a node.
By considering the types of storage media they use, which data sets are most often accessed in queries, and using Linux page cache, developers can significantly reduce query times and to get faster access to business intelligence from their data.
…………………………………………

Gavin Halliday
Gavin’s primary focus is on the code generator, which converts ECL into the queries which run on the platform. Gavin enjoys working on problems together with the development team and the varied nature of the work keeps him engaged. Gavin shares how the platform compares with competitive platforms, including scalability and coding simplicity. He enjoys working on the platform and the elegant solutions the development team is able to implement. Gavin encourages people to give it a try!
Sponsored by HPCC Systems