A Cheat Sheet: What Executives Want to Know about Big Data
A Cheat Sheet: What Executives Want to Know about Big Data
by Tamara Dull, Director of Emerging Technologies for SAS Best Practices
This spring, I presented An Executive’s Cheat Sheet on Hadoop, the Enterprise Data Warehouse and the Data Lake at the SAS Global Forum Executive Conference in Dallas. Given the (still) strong interest in this presentation—before, during, and after—I wanted to highlight some of the questions I addressed during this session:
- What can Hadoop do that my data warehouse can’t?
- We’re not doing “big” data, so why do we need Hadoop?
- Is Hadoop enterprise-ready?
- Isn’t a data lake just the data warehouse revisited?
Following is a recap of my comments, along with a few screenshots. See what you think.
1) What can Hadoop do that my data warehouse can’t?
The short answer is: (1) Store any and all kinds of data more cheaply and (2) process all this data more quickly (and cheaply).
The longer answer is: I made reference to my opening “soapbox” statement – “Big data is not new.” They say that 20% of the data we deal with today is structured data (see examples in orange boxes below). I also call this traditional, relational data. The other 80% is semi-structured or unstructured data (examples in blue boxes), and this is what I call “big” data.

Are any of these example blue-box data types new? Of course not. We’ve been collecting, processing, storing, and analyzing all this data for decades. What we haven’t been able to do very well, however, if at all, is mix the orange- and blue-box data together.
So here’s what’s new: We now have the technologies to collect, process, store, and analyze all this data together. In other words, we can now mix-&-match the orange- and blue-box data together – at a fraction of the cost and time of our traditional, relational systems.
2) We’re not doing “big” data, so why do we need Hadoop?
I proposed six common Hadoop use cases—three of which don’t require “big” data at all to take full advantage of Hadoop. These use cases come from my white paper called The Non-Geek’s Big Data Playbook: Hadoop and the Enterprise Data Warehouse.
Here’s a brief summary of each use case:
- Stage structured data. Use Hadoop as a data staging platform for your data warehouse.
- Process structured data. Use Hadoop to update data in your data warehouse and/or operational systems.
- Archive all data. Use Hadoop to archive all your data on-premises or in the cloud.
- Process any data. Use Hadoop to take advantage of non-integrated and unstructured data that’s currently unavailable in your data warehouse.
- Access any data (via data warehouse). Use Hadoop to extend your data warehouse and keep it at the center of your organization’s data universe.
- Access any data (via Hadoop). Use Hadoop as the landing platform for all data and exploit the strengths of both the data warehouse and Hadoop.
If you’d like to see these use cases further explained and demonstrated with some easy-to-understand visuals, I invite you to download the white paper.
3) Is Hadoop enterprise-ready?
I have two answers to this question:
- For your organization: Maybe.
- For all organizations: No.
It all depends on what and how you want to use Hadoop in your organization. If you simply want to use it as an additional (or alternative) storage repository and/or as a short-term data processor, then by all means, Apache Hadoop is ready for you.
However, if you want to go beyond data storage and processing and are looking for some of the same data management and analysis capabilities you currently have with your existing relational systems, you will first need to explore the vast ecosystem of Hadoop-related open source and proprietary projects and products. This will not be a small undertaking.
Because many of these newer Hadoop-related technologies are still maturing—quite rapidly, I might add—that’s why I say Hadoop—as in the Hadoop ecosystem—isn’t 100% ready for the enterprise.
4) Isn’t a data lake just the data warehouse revisited?
Many of us have been learning more about the data lake, especially in the last 6 months. Some suggest that the data lake is just a reincarnation of the data warehouse—in the spirit of “been there, done that.” Others focus on how much better this “shiny, new” data lake is, while others are standing on the shoreline screaming, “Don’t go in! It’s not a lake—it’s a swamp!”
All kidding aside, the commonality I see is that they are both data storage repositories. Beyond that, the table below highlights some key differences. This is, by no means, an exhaustive list, but it does get us past this “been there, done that” mentality. A data lake is not a data warehouse.
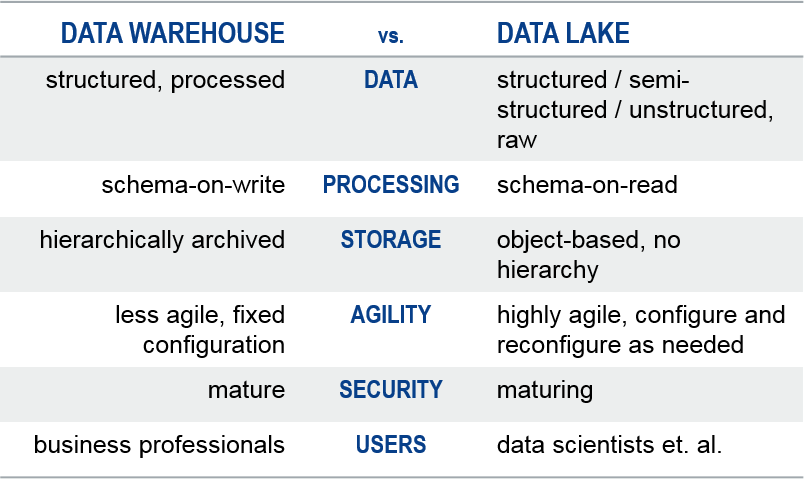
If you’re interested in learning more about the data lake, I invite you to check out my previous ODBMS.org article: The Data Lake: A Brief SWOT Analysis.