All modern consumer applications must scale easily and cost-efficiently, and for this, linear database performance is key. With our shared-nothing architecture, we’ve proven again and again that a single Redis Enterprise cluster can scale infinitely in a linear manner by simply adding shards and nodes. But that doesn’t mean we’re resting on our laurels. At RedisConf18 we demonstrated that a single Redis Enterprise cluster could reach 50 million operations per second (ops/sec) with only 26 AWS instances while keeping latency under 1 millisecond, and today we’re pleased to share that Redis Enterprise has set yet another new industry performance record.
In our latest benchmark, Redis Enterprise delivered over 200 million ops/sec, with under 1 millisecond latency, on as little as 40 AWS instances. This represents a 2.6X performance improvement in less than 15 months. Before we get into the configuration, tools, workloads and results of our latest benchmark, let’s quickly review Redis Enterprise clusters.
Redis Enterprise Architecture Refresher
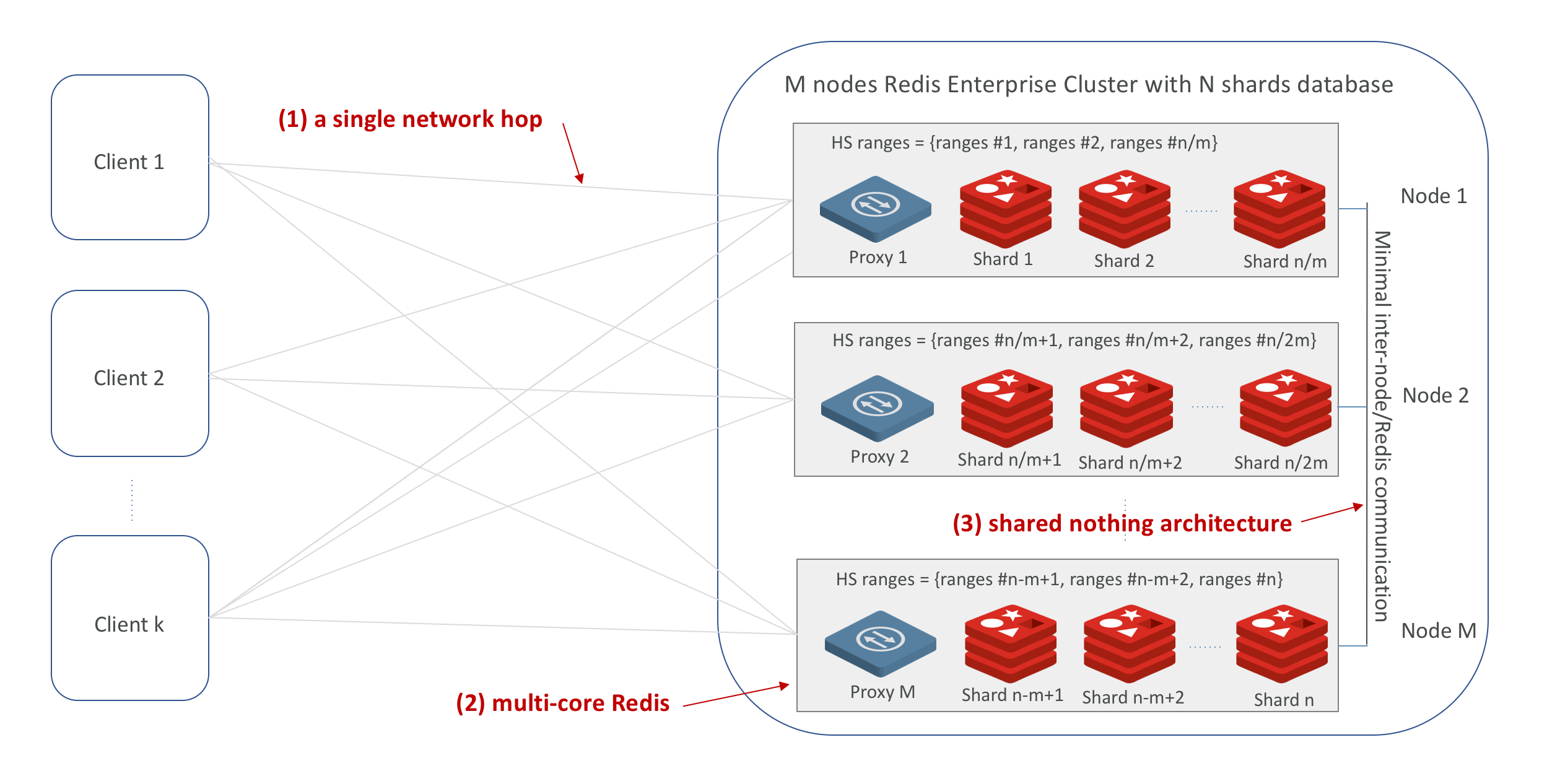
In Redis Enterprise terms, a cluster is a set of nodes composed from either cloud instances, virtual machines or containers/Kubernetes PODs, or bare-metal servers. A cluster allows you to create Redis databases in a memory pool shared across these nodes, while maintaining complete separation between the data path and the control and management path. Each cluster includes Redis shards, a zero-latency proxy, and a cluster manager. Since the open source cluster API allows Redis clients to directly access the shard that holds the key-value object with no additional network hop, a Redis Enterprise cluster can scale very efficiently. The control path (which deals with database provisioning/deprovisioning, auto-failover, shard migration, cluster balancing and much more) imposes very little overhead and doesn’t affect this linear scalability. Last but not least, Redis Enterprise efficiently utilizes all the cores on every cluster node before adding more nodes to the cluster for scaling purposes.
Here is a visual depiction of Redis Enterprise’s shared-nothing cluster architecture, configured with the open source cluster API and utilizing all the cores in a given cluster node:
Single node benchmark
As a baseline, we wanted to test how many ops/sec we could achieve when running on a single AWS instance, and keeping in mind the following requirements:
- Maintain a latency under 1 msec
- Keep our pipeline to 9 max
- Use a 100-byte value size
- Have a 1:1 Get:Set ratio
To accomplish this, we used the following system setup:
1) We installed Redis Enterprise.
https://docs.redislabs.com/latest/rs/installing-upgrading/downloading-installing/
2) We set up Route53.
https://docs.redislabs.com/latest/rs/installing-upgrading/configuring/cluster-name-dns-connection-management/configuring-aws-route53-dns-redis-enterprise/
3) We created our database.
Specify cluster_api_user, name, shards_count and port
As shown below, the API will create database name:<name > with shards:<shards_count> listening on port:<port>. Even though we used a single node cluster for this benchmark, we also set the proxy_policy, shards_placement and oss_cluster parameters. These are used for placing shards equally and creating endpoints on all the nodes, in order to stay consistent with the multi-node cluster configuration.
curl -v -k -u <cluster_api_user> https://localhost:9443/v1/bdbs -H "Content-type: application/json" -d \
'{
"name": <name>,
"memory_size": 10000000000,
"type" : "redis",
"sharding": true ,
"shards_count": <shards_count>,
"shard_key_regex": [{"regex": ".*\\{(?<tag>.*)\\}.*"},{"regex": "(?<tag>.*)" }],
"proxy_policy": "all-master-shards",
"shards_placement": "sparse",
"oss_cluster":true,
"port":<port>
}'
To make sure the test was fair, we first populated the database to avoid GET operations on non-existent keys (specify NUM_OF_KEYS):
memtier_benchmark -s <EndPoint> -p <Port> -t 48 --ratio=1:0 --pipeline=9 -c 1 -d 100 --key-minimum=1 --key-maximum=<NUM_OF_KEYS> -n allkeys --key-pattern=S:S
4) We chose the c5.18xlarge instance type on AWS EC2 for our node, with 72 vCPU 144GB and a 3.0 GHz (up to 3.5 GHz using Intel Turbo Boost Technology) Intel Xeon Skylake-SP processor.
5) We chose a c5.9xlarge instance type to run the load generation tool for our client machine.
6) Finally, for our load generation tool, we used memtier_benchmark with the following parameters:
memtier_benchmark -s <redis.endpoint.address> -p <port> -t $Threads —ratio=1:1 --pipeline=9 -c $Clients -d 100 --key-minimum=1 --key-maximum=<NUMBER_OF_KEYS> -n 1000000000 --cluster-mode
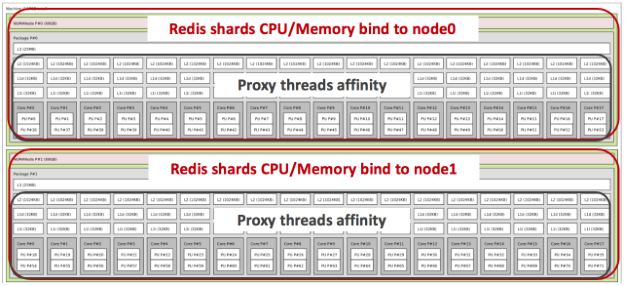
We then tried to find the best shards and proxy threads balance, and observed that our best results came with 8 shards per node, which gave us 4.2 million ops/sec. Throughput was unstable, because of proxy threads context switching and Redis process transitions between CPUs on different NUMA nodes. This cross-memory access increased processing latency, even though the system was loaded at only 50%.
As shown in the image below, we were able to get much better results with 8- and 10-shard configurations on the c5.18xlarge instance, using NUMA binding for the Redis shards and proxy threads affinity:
Note: The scripts below work on two-socket systems only.
- Setting proxy threads balancing between numa nodes:
NUMA_CNT=$(numactl --hardware | grep '^available' | awk '{print $2}')
if [ $NUMA_CNT -eq 2 ]; then
NODE_ID=$(cat /etc/opt/redislabs/node.id)
DMC_HALF_COUNT=$(expr $(/opt/redislabs/bin/ccs-cli hget dmc:$NODE_ID threads) / 2)
NUMA0_CPUS=$(numactl --hardware | grep 'node 0 cpus' | awk -F ': ' '{print $2}' | sed 's/ /,/g')
NUMA1_CPUS=$(numactl --hardware | grep 'node 1 cpus' | awk -F ': ' '{print $2}' | sed 's/ /,/g')
DMC_PID=$(sudo /opt/redislabs/bin/dmc-cli -ts root list | grep listener | awk '{printf "%i\n",$3}')
sudo taskset -apc $NUMA0_CPUS $DMC_PID
sudo /opt/redislabs/bin/dmc-cli -ts root list | grep worker | tail -$DMC_HALF_COUNT | \
awk '{printf "%i\n",$3}' | \
xargs -i sudo taskset -pc $NUMA1_CPUS {}
fi
- Balancing and binding CPU and memory for Redis processes:
NUMA_CNT=$(numactl --hardware | grep '^available' | awk '{print $2}')
REDIS_HALF_CNT=$(expr $(pgrep redis-server-5 | wc -l) / 2)
NUMA0_CPUS=$(numactl --hardware | grep 'node 0 cpus' | awk -F ': ' '{print $2}' | sed 's/ /,/g')
NUMA1_CPUS=$(numactl --hardware | grep 'node 1 cpus' | awk -F ': ' '{print $2}' | sed 's/ /,/g')
pgrep redis-server-5 | sort | head -$REDIS_HALF_CNT | xargs -i sudo taskset -apc $NUMA0_CPUS {} && \
pgrep redis-server-5 | sort | head -$REDIS_HALF_CNT | xargs -i sudo migratepages {} 1 0
pgrep redis-server-5 | sort | tail -$REDIS_HALF_CNT | xargs -i sudo taskset -apc $NUMA1_CPUS {} && \
pgrep redis-server-5 | sort | tail -$REDIS_HALF_CNT | xargs -i sudo migratepages {} 0 1
Single node results summary
The table below shows how we determined the optimal Redis shards and proxy threads configuration on the AWS c5.18xlarge instance in order to achieve the best possible throughput (in ops/sec) while keeping latency to sub-millisecond:
| Shards | 4 | 6 | 8 | 8 | 10 |
| Proxy threads | 16 | 24 | 28 | 28 | 32 |
| Comment | Default | Default | Default | NUMA tuned | NUMA tuned |
| Latency (msec) | 0.92 | 0.91 | 0.98 | 0.81 | 0.92 |
| Throughput (M ops/sec) |
2.9 | 3.89 | 4.2 | 4.8 | 5.3 |
| Throughput per shard (K ops/sec) | 725 | 648 | 525 | 600 | 530 |
Scaling the cluster
50M ops/sec with 10 AWS c5.18xlarge instances
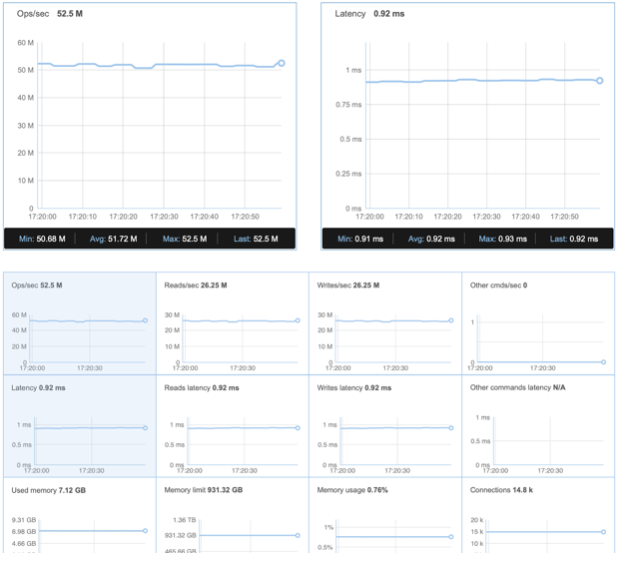
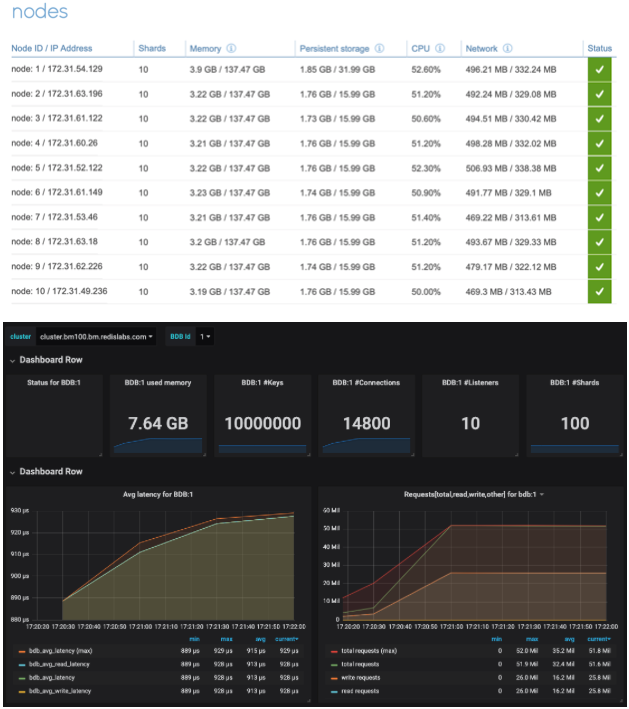
We first wanted to match the 50 million ops/sec benchmark we demonstrated at RedisConf18 with 26 m4.16xlarge instances. This time we were able to reach 51.72 million ops/sec with only 10 AWS 5.18xlarge instances:
| Nodes (C5.18xlarge) | 10 |
| Clients (C5.9xlarge) | 10 |
| Shards per Node | 10 |
| Proxy Threads | 32 |
| Prepopulated Keys | 10M |
| Connections | 14,800 |
| Avg ops/sec | 51.72M |
| Avg Latency | 0.92 |
| Avg ops/sec per Node | 5.17M |
We then scaled to 100M ops/sec with 20 AWS 5.18xlarge instances
| Nodes (C5.18xlarge) | 20 |
| Clients (C5.9xlarge) | 20 |
| Shards per Node | 10 |
| Proxy Threads | 32 |
| Prepopulated Keys | 10M |
| Connections | 30,400 |
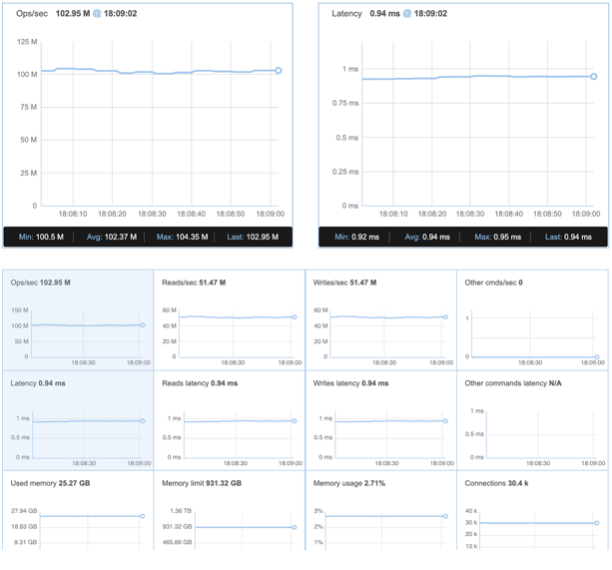
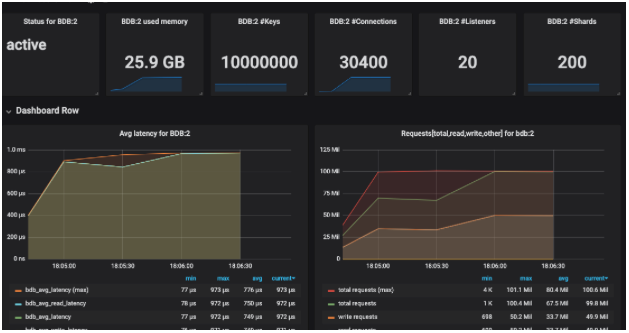
| Avg ops/sec | 102.37M |
| Avg Latency | 0.94 |
| Avg ops/sec per Node | 5.11M |

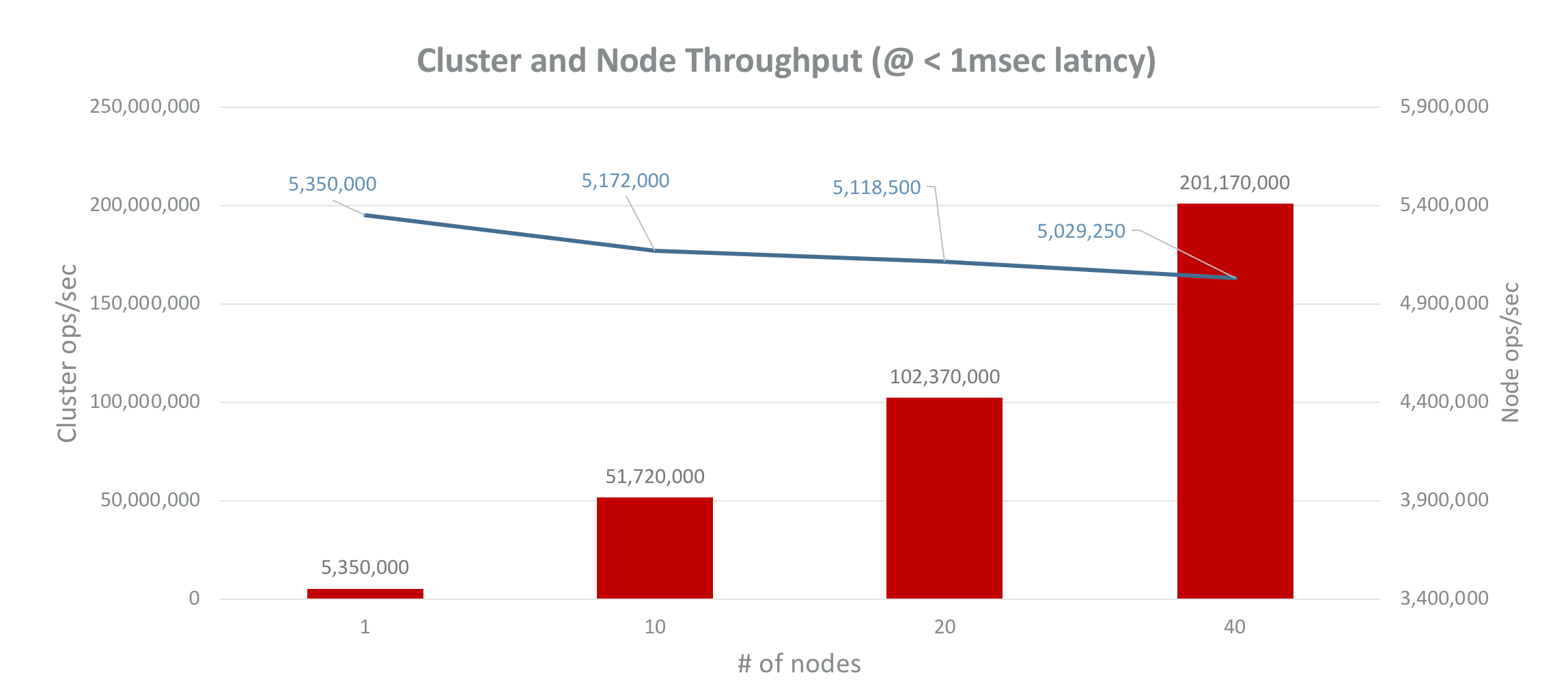
And finally, 200M ops/sec with 40 AWS c5.18xlarge instances
| Nodes (C5.18xlarge) | 40 |
| Clients (C5.9xlarge) | 30 |
| Shards per Node | 10 |
| Proxy Threads | 32 |
| Prepopulated Keys | 10M |
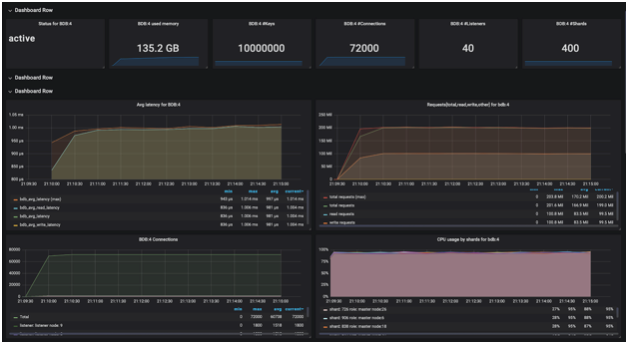
| Connections | 72,000 |
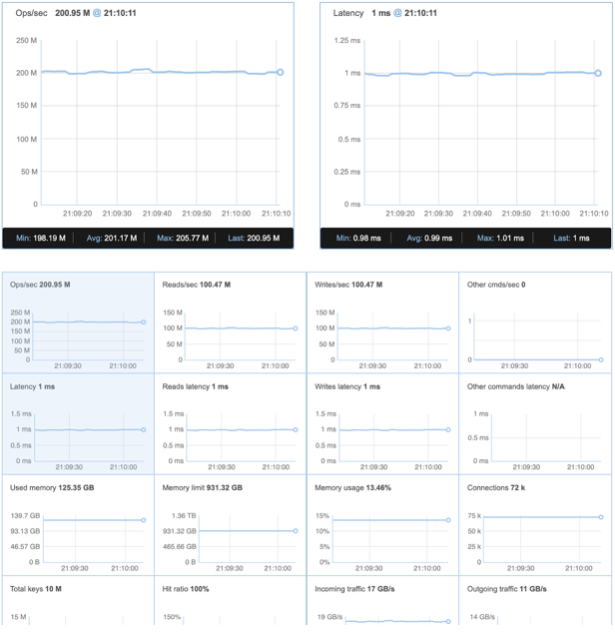
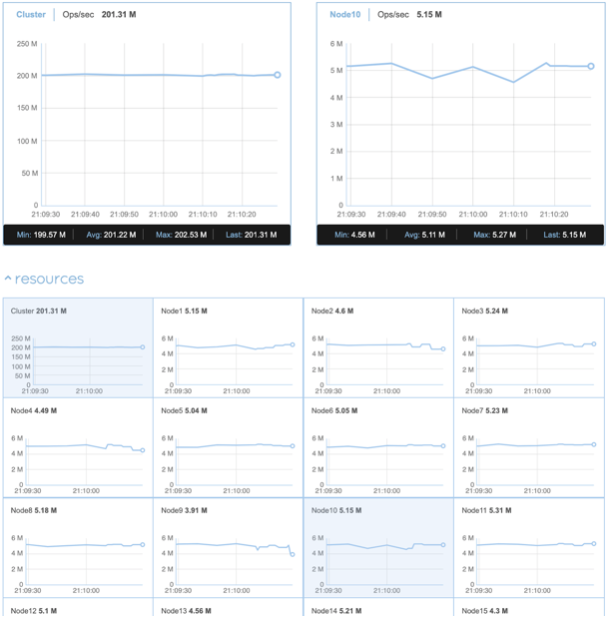
| Avg ops/sec | 201.17M |
| Avg Latency | 0.99 |
| Avg ops/sec per Node | 5.02M |
Results summary
Our multiple improvements to the Redis core in version 5.0 (especially around big pipeline performance), together with many enhancements to the Redis Enterprise proxy and to the way it communicates with the Redis shards, and combined with the new AWS C5 instance family and a proper NUMA configuration, all helped achieve over 200M ops/sec with only a 40-nodecluster while keeping latency under 1 millisecond.
Our shared-nothing architecture enables an additional 500K+ ops/sec for every Redis shard and 5M+ ops/sec for every node added to the cluster, in a close to optimal 94% linear scaling. In other words, per node throughput declined by only 6% between a single node and a 40-node cluster.
During these tests, we even managed to achieve 800K ops/sec per Redis shard (with consistent sub-millisecond latency), but due to network packet per second limits we were not able to scale our node throughput to achieve higher and stable performance over time.
We were amazed by the significant improvement we saw while breaking our own database performance record from 15 months ago:
| March 2018 | June 2019 | Improvement | |
| Cluster throughput | 50M ops/sec | 200M ops/sec | x4 |
| # of nodes | 26 | 40 | x2.6 |
| # of shards | 512 | 400 | x5 |
This experiment shows that with proper architecture, as implemented by Redis Enterprise, Redis can break any performance record in the database space while using significantly less hardware resources than other databases.
Sponsored by Redis Labs