On Exasol’s distributed MPP architecture vs. DuckDB. Q&A with Mathias Golombek.
Q1. In your benchmark, one of the most intriguing results was that Exasol’s distributed MPP architecture outperformed DuckDB even on a single server — essentially DuckDB’s “home game.” This challenges the conventional wisdom that embedded databases should dominate single-node scenarios. What’s the underlying reason for those results?
This result may have surprised some readers, but it was less unexpected for us. Exasol’s shared-nothing MPP architecture was designed from the ground up to be efficient in both scale-out and scale-up environments. Even on a single node, we execute queries in a fully parallelized fashion, leveraging all available cores and pipelines. Our execution engine is optimized to take full advantage of modern CPU architectures with minimal per-operator overhead.
In contrast, DuckDB currently runs single-threaded in many scenarios, which limits its ability to utilize all cores on a machine like the c7a.24xlarge. While DuckDB excels as a lightweight embedded database for single-user workloads, the moment you need parallelism or multi-user concurrency, Exasol’s architecture shows its strength — even without a distributed cluster.
Q2. Both Exasol and DuckDB use vectorized execution, yet your performance gap was substantial across all 22 TPC-H queries. What specific implementation differences in your architecture contributed to this performance delta? Are there particular query patterns or operations where your architecture shows the most dramatic advantages?
While both systems use vectorized execution, the performance difference in our benchmark isn’t just about vectorization — it’s about how that execution is integrated into the broader engine architecture. Exasol combines vectorized operators with aggressive pipelining and multi-threaded parallelism, all running on an in-memory engine.
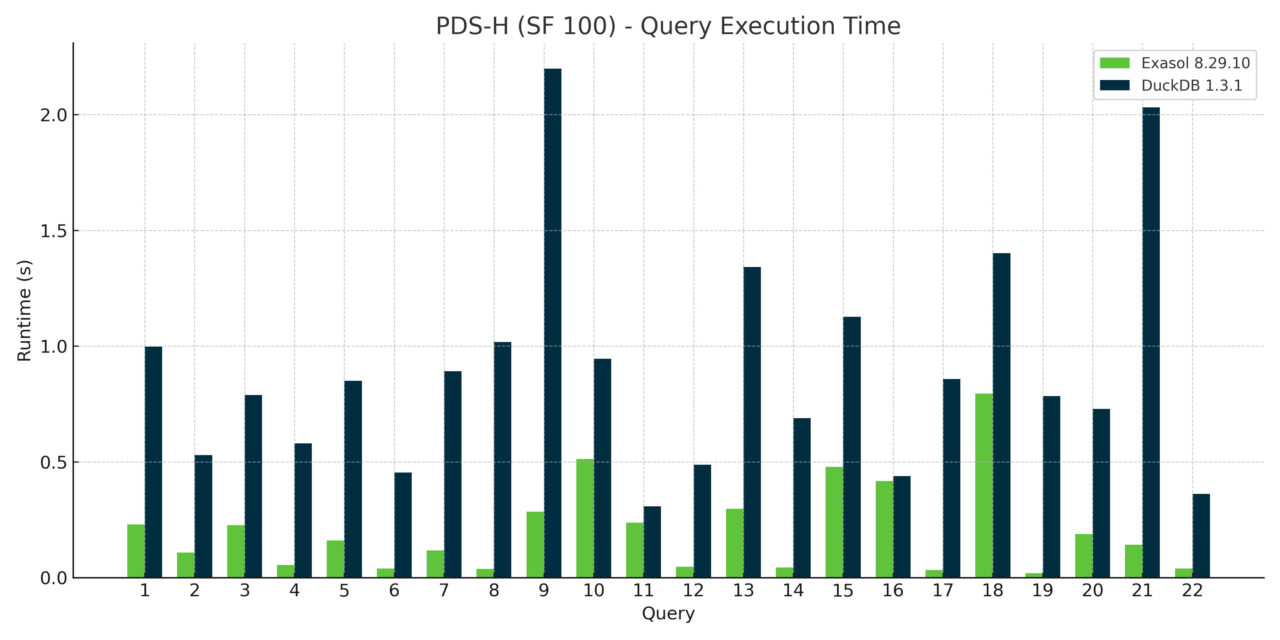
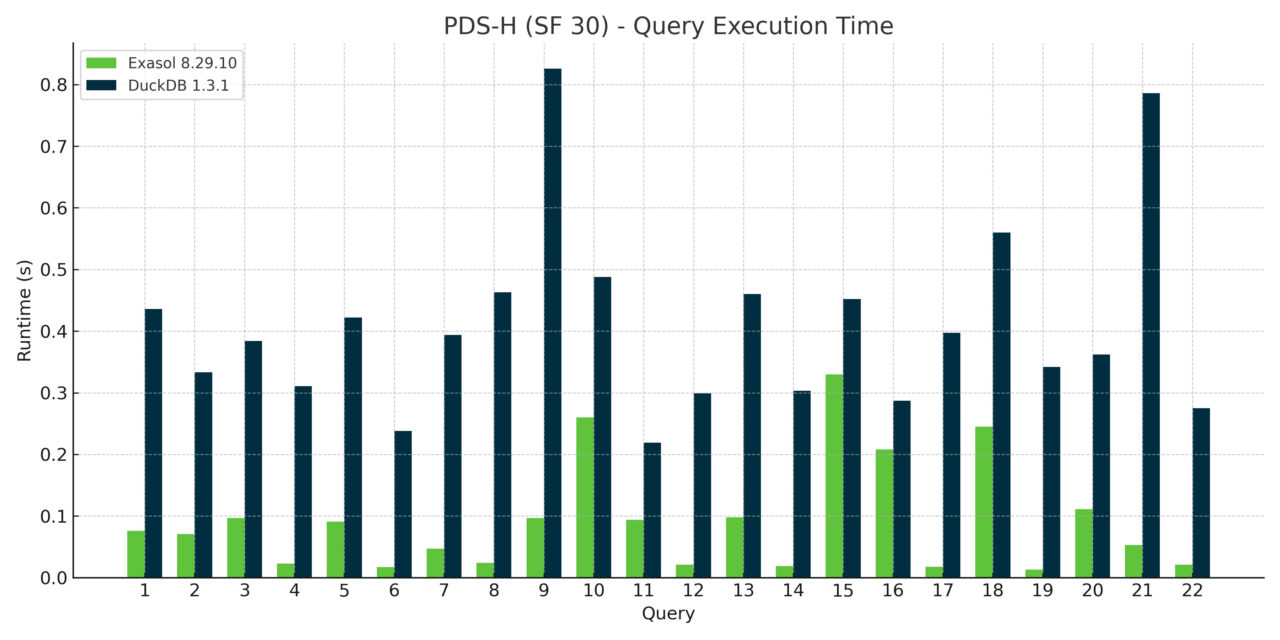
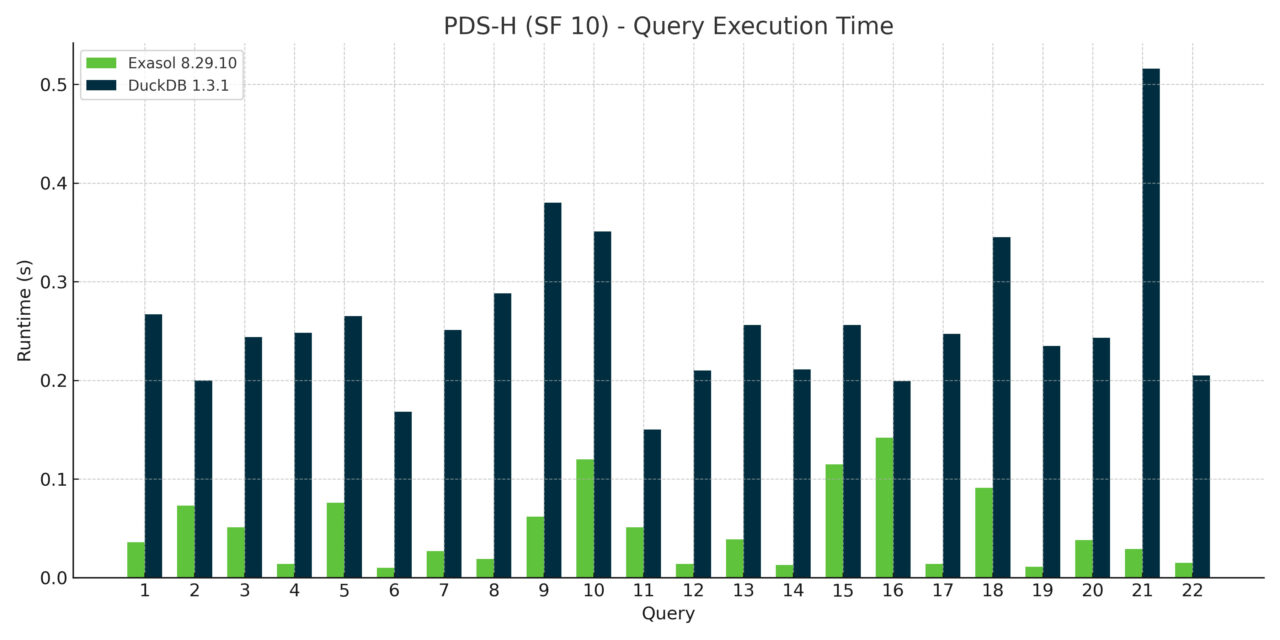
This design allows Exasol to fully leverage random-access algorithms and modern hardware capabilities, even on a single large instance. As a result, Exasol outperformed DuckDB across all 22 analytical TPC-H queries. For more complex data models, we’d expect the gap to widen even further.
Q3. In your benchmark, you mention Exasol’s “mature cost-based optimizer that’s been tuned on analytical workloads for years.” Can you elaborate on the specific optimizer techniques that gave Exasol its edge over DuckDB’s query planner?
In this case, the main driver of performance isn’t necessarily query plan complexity but the underlying software architecture. The TPC-H schema is relatively straightforward, with two large fact tables and a few dimension tables. The queries themselves don’t grow more complex with scale — only the data volume increases. Our performance advantage primarily stems from Exasol’s in-memory architecture and highly parallel execution engine. Because everything fits comfortably in RAM, fully pipelined and multi-threaded query execution gives us a clear edge.
When comparing Exasol’s and DuckDB’s query planners, we’re cautious — we don’t claim to be DuckDB experts. However, we can say that Exasol’s performance advantages tend to grow with the complexity of the data model and analytical workload. Even queries involving dozens of joins within a Snowflake schema are handled efficiently thanks to the optimizer’s robustness in areas such as join order selection, cardinality estimation, predicate pushdown, automated indexing, and the avoidance of unnecessary materialization of intermediate results.
Q4. The test ran on a server with 192 GiB of RAM and datasets up to 100 GB. How does physical RAM affect Exasol’s in-memory execution?
In this benchmark setup, memory wasn’t a limiting factor — the entire 100 GB dataset fit comfortably in RAM, so there was no need to optimize for caching or spillover. What mattered most was how efficiently each engine executed queries entirely in-memory.
Exasol’s architecture is built around in-memory processing, but it’s not a pure in-memory database. More RAM certainly improves performance, but the data doesn’t need to fit entirely in memory. In real-world scenarios, due to columnar storage, compression, and access patterns, even a 1:20 ratio between RAM and raw data size is typically sufficient to unlock Exasol’s full speed.
With modern hardware offering increasingly large memory capacities, in-memory acceleration is rarely a limiting factor anymore. Many customers now handle hundreds of terabytes of analytical data efficiently within Exasol.
Q5. You emphasized that Exasol’s concurrency and workload management capabilities are where enterprise databases truly differentiate. Can you explain the technical architecture behind Exasol’s multi-user concurrency model?
While the benchmark focused on single-user query performance, real-world enterprise environments usually involve multiple users running queries simultaneously. This is where Exasol’s architecture truly stands out.
Exasol is natively built to handle high-concurrency, multi-tenant workloads. It supports parallel query execution across users while maintaining full ACID compliance. Advanced workload management ensures fair and efficient resource allocation, enabling consistent performance even under heavy multi-user load.
In contrast, DuckDB is optimized for single-threaded, single-user scenarios. To achieve concurrency, it must be run in separate processes — an approach that introduces overhead and lacks coordination in memory and I/O management. This model doesn’t scale as efficiently as Exasol’s shared-nothing MPP architecture, which scales both horizontally across nodes and vertically within nodes.
In short, while DuckDB performs well for local, single-user analytics, Exasol’s built-in concurrency model makes it far better suited for enterprise-grade, multi-user environments where predictable performance and isolation are critical.
Q6. Anything else you’d like to add?
One of the biggest takeaways from our benchmark is that single-instance performance is only one dimension of a database’s capability. Concurrency, scale-out, workload management, resilience, and operational robustness are equally critical. Exasol is designed to deliver consistently high performance regardless of user load or cluster size.
We encourage the community to reproduce these tests using the PDS harness (which we integrated with Exasol) and compare results in their own environments. Transparency benefits everyone — it helps improve the entire analytics ecosystem.
But ultimately, the best way for organizations to evaluate databases is to test them on their own data and real workloads.
………………………………………………

Mathias Golombek
Mathias Golombek is the Chief Technology Officer (CTO) of Exasol. He joined the company as a software developer in 2004 after studying computer science with a heavy focus on databases, distributed systems, software development processes, and genetic algorithms. By 2005, he was responsible for the Database Optimizer team and in 2007 he became Head of Research & Development. In 2014, Mathias was appointed CTO. In this role, he is responsible for product development, product management, operations, support, and technical consulting.
Sponsored by Exasol.