

A Grand Tour of Big Data. Interview with Alan Morrison
“Leading enterprises have a firm grasp of the technology edge that’s relevant to them. Better data analysis and disambiguation through semantics is central to how they gain competitive advantage today.”–Alan Morrison.
I have interviewed Alan Morrison, senior research fellow at PwC, Center for Technology and Innovation.
Main topic of the interview is how the Big Data market is evolving.
RVZ
Q1. How do you see the Big Data market evolving?
Alan Morrison: We should note first of all how true Big Data and analytics methods emerged and what has been disruptive. Over the course of a decade, web companies have donated IP and millions of lines of code that serves as the foundation for what’s being built on top. In the process, they’ve built an open source culture that is currently driving most big data-related innovation. As you mentioned to me last year, Roberto, a lot of database innovation was the result of people outside the world of databases changing what they thought needed to be fixed, people who really weren’t versed in the database technologies to begin with.
Enterprises and the database and analytics systems vendors who serve them have to constantly adjust to the innovation that’s being pushed into the open source big data analytics pipeline. Open source machine learning is becoming the icing on top of that layer cake.
Q2. In your opinion what are the challenges of using Big Data technologies in the enterprise?
Alan Morrison: Traditional enterprise developers were thrown for a loop back in the late 2000s when it comes to open source software, and they’re still adjusting. The severity of the problem differs depending on the age of the enterprise. In our 2012 issue of the Forecast on DevOps, we made clear distinctions between three age classes of companies: legacy mainstream enterprises, pre-cloud enterprises and cloud natives. Legacy enterprises could have systems that are 50 years old or more still in place and have simply added to those. Pre-cloud enterprises are fighting with legacy that’s up to 20 years old. Cloud natives don’t have to fight legacy and can start from scratch with current tech.
DevOps (dev + ops) is an evolution of agile development that focuses on closer collaboration between developers and operations personnel. It’s a successor to agile development, a methodology that enables multiple daily updates to operational codebases and feedback-response loop tuning by making small code changes and see how those change user experience and behaviour. The linked article makes a distinction between legacy, pre-cloud and cloud native enterprises in terms of their inherent level of agility:
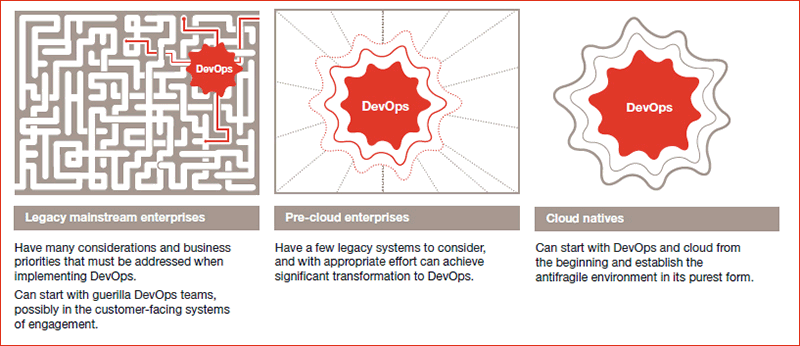
Most enterprises are in the legacy mainstream group, and the technology adoption challenges they face are the same regardless of the technology. To build feedback-response loops for a data-driven enterprise in a legacy environment is more complicated in older enterprises. But you can create guerilla teams to kickstart the innovation process.
Q3. Is the Hadoop ecosystem now ready for enterprise deployment at large scale?
Alan Morrison: Hadoop is ten years old at this point, and Yahoo, a very large mature enterprise, has been running Hadoop on 10,000 nodes for years now. Back in 2010, we profiled a legacy mainstream media company who was doing logfile analysis from all of its numerous web properties on a Hadoop cluster quite effectively. Hadoop is to the point where people in their dens and garages are putting it on Raspberry Pi systems. Lots of companies are storing data in or staging it from HDFS. HDFS is a given. MapReduce, on the other hand, has given way to Spark.
HDFS preserves files in their original format immutably, and that’s important. That innovation was crucial to data-driven application development a decade ago. But Hadoop isn’t the end state for distributed storage, and NoSQL databases aren’t either. It’s best to keep in mind that alternatives to Hadoop and its ecosystem are emerging.
I find it fascinating what folks like LinkedIn and Metamarkets are doing data architecture wise with the Kappa architecture–essentially a stream processing architecture that also works for batch analytics, a system where operational and analytical data are one and the same. That’s appropriate for fully online, all-digital businesses. You can use HDFS, S3, GlusterFS or some other file system along with a database such as Druid. On the transactional side of things, the nascent IPFS (the Interplanetary File System) anticipates both peer-to-peer and the use of blockchains in environments that are more and more distributed. Here’s a diagram we published last year that describes this evolution to date:
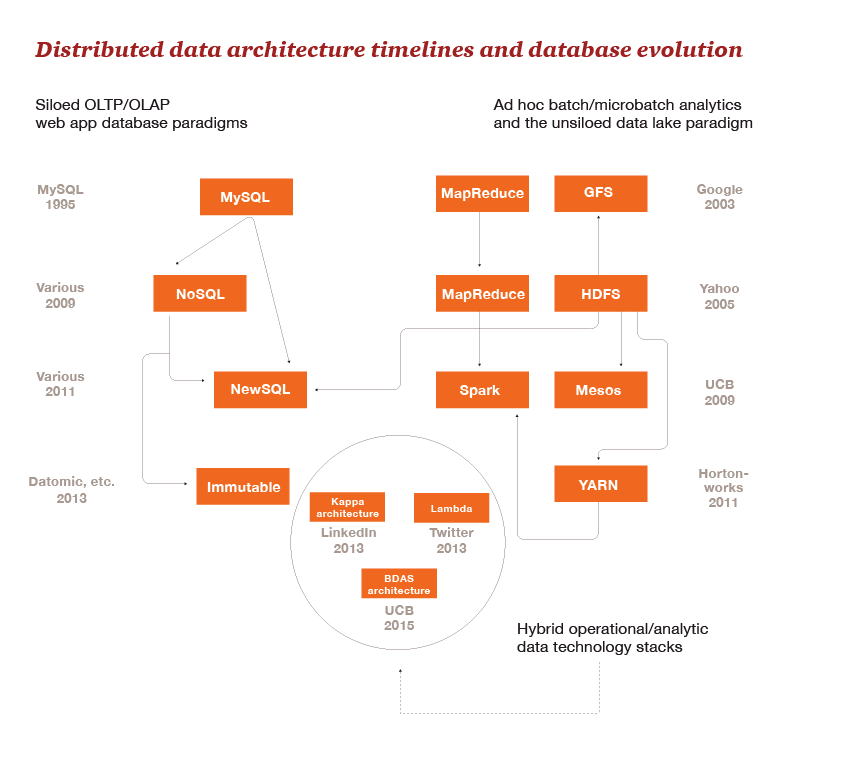
From PWC Technology Forecast 2015
People shouldn’t be focused on Hadoop, but what Hadoop has cleared a path for that comes next.
Q4. What are in your opinion the most innovative Big Data technologies?
Alan Morrison: The rise of immutable data stores (HDFS, Datomic, Couchbase and other comparable databases, as well as blockchains) was significant because it was an acknowledgement that data history and permanence matters, the technology is mature enough and the cost is low enough to eliminate the need to overwrite. These data stores also established that eliminating overwrites also eliminates a cause of contention. We’re moving toward native cloud and eventually the P2P fog (localized, more truly distributed computing) that will extend the footprint of the cloud for the Internet of things.
Unsupervised machine learning has made significant strides in the past year or two, and it has become possible to extract facts from unstructured data, building on the success of entity and relationship extraction. What this advance implies is the ability to put humans in feedback loops with machines, where they let machines discover the data models and facts and then tune or verify those data models and facts.
In other words, large enterprises now have the capability to build their own industry- and organization-specific knowledge graphs and begin to develop cognitive or intelligent apps on top those knowledge graphs, along the lines of what Cirrus Shakeri of Inventurist envisions.
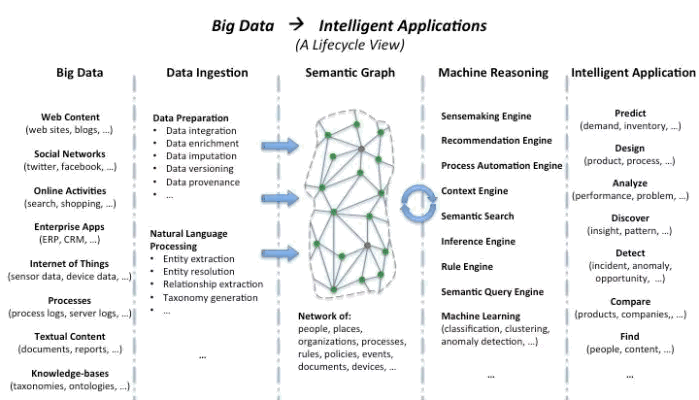
From Cirrus Shakeri, “From Big Data to Intelligent Applications,” post, January 2015
At the core of computable semantic graphs (Shakeri’s term for knowledge graphs or computable knowledge bases) is logically consistent semantic metadata. A machine-assisted process can help with entity and relationship extraction and then also ontology generation.
Computability = machine readability. Semantic metadata–the kind of metadata cognitive computing apps use–can be generated with the help of a well-designed and updated ontology. More and more, these ontologies are uncovered in text rather than hand built, but again, there’s no substitute for humans in the loop. Think of the process of cognitive app development as a continual feedback-response loop process. The use of agents can facilitate the construction of these feedback loops.
Q5. In a recent note Carl Olofson, Research Vice President, Data Management Software Research, IDC, predicted the RIP of “Big Data” as a concept. What is your view on this?
Alan Morrison: I agree the term is nebulous and can be misleading, and we’ve had our fill of it. But that doesn’t mean it won’t continue to be used. Here’s how we defined it back in 2009:
Big Data is not a precise term; rather, it is a characterization of the never-ending accumulation of all kinds of data, most of it unstructured. It describes data sets that are growing exponentially and that are too large, too raw, or too unstructured for analysis using relational database techniques. Whether terabytes or petabytes, the precise amount is less the issue than where the data ends up and how it is used. (See https://www.pwc.com/us/en/technology-forecast/assets/pwc-tech-forecast-issue3-2010.pdf, pg. 6.)
For that issue of the Forecast, we focused on how Hadoop was being piloted in enterprises and the ecosystem that was developing around it. Hadoop was the primary disruptive technology, as well as NoSQL databases. It helps to consider the data challenge of the 2000s and how relational databases and enterprise data warehousing techniques were falling short at that point. Hadoop has reduced the cost of analyzing data by an order of magnitude and allows processing of very large unstructured datasets. NoSQL has made it possible to move away from rigid data models and standard ETL.
“Big Data” can continue to be shorthand for petabytes of unruly, less structured data. But why not talk about the system instead of just the data? I like the term that George Gilbert of Wikibon latched on to last year. I don’t know if he originated it, but he refers to the System of Intelligence. That term gets us beyond the legacy, pre-web “business intelligence” term, more into actionable knowledge outputs that go beyond traditional reporting and into the realm of big data, machine learning and more distributed systems. The Hadoop ecosystem, other distributed file systems, NoSQL databases and the new analytics capabilities that rely on them are really at the heart of a System of Intelligence.
Q6. How many enterprise IT systems do you think we will need to interoperate in the future?
Alan Morrison: I like Geoffrey Moore‘s observations about a System of Engagement that emerged after the System of Record, and just last year George Gilbert was adding to that taxonomy with a System of Intelligence. But you could add further to that with a System of Collection that we still need to build. Just to be consistent, the System of Collection articulates how the Internet of Things at scale would function on the input side. The System of Engagement would allow distribution of the outputs. For the outputs of the System of Collection to be useful, that system will need to interoperate in various ways with the other systems.
To summarize, there will actually be four enterprise IT systems that will need to interoperate, ultimately. Three of these exist, and one still needs to be created.
- System of Collection: The Internet of Things ( (The Fog–yet to be created)–see Maher Abdelshkour, IoT, from Cloud to Fog Computing
- System of Intelligence: big data, analytics, machine learning (The Cloud) –see George Gilbert on Systems of Intelligence: The Next Generation of Enterprise Applications built on Big Data
- System of Engagement: social, mobile (The Cloud) See Geoffrey Moore,Systems of Engagement and the Future of Enterprise IT: A Sea Change in Enterprise IT
- System of Record: ERP, CRM, SCM…. (The Core) Also described in Moore’s article above
The fuller picture will only emerge when this interoperation becomes possible.
Q7. What are the requirements, heritage and legacy of such systems?
Alan Morrison: The System of Record (RDBMSes) still relies on databases and tech with their roots in the pre-web era. I’m not saying these systems haven’t been substantially evolved and refined, but they do still reflect a centralized, pre-web mentality. Bitcoin and Blockchain make it clear that the future of Systems of Record won’t always be centralized. In fact, microtransaction flows in the Internet of Things at scale will depend on the decentralized approaches, algorithmic transaction validation, and immutable audit trail creation which blockchain inspires.
The Web is only an interim step in the distributed system evolution. P2P systems will eventually complemnt the web, but they’ll take a long time to kick in fully–well into the next decade. There’s always the S-curve of adoption that starts flat for years. P2P has ten years of an installed base of cloud tech, twenty years of web tech and fifty years plus of centralized computing to fight with. The bitcoin blockchain seems to have kicked P2P in gear finally, but progress will be slow through 2020.
The System of Engagement (requiring Web DBs) primarily relies on Web technnology (MySQL and NoSQL) in conjunction with traditional CRM and other customer-related structured databases.
The System of Intelligence (requiring Web file systems and less structured DBs) primarily relies on NoSQL, Hadoop, the Hadoop ecosystem and its successors, but is built around a core DW/DM RDBMS analytics environment with ETLed structured data from the System of Record and System of Engagement. The System of Intelligence will have to scale and evolve to accommodate input from the System of Collection.
The System of Collection (requiring distributed file systems and DBs) will rely on distributed file system successors to Hadoop and HTTP such as IPFS and the more distributed successors to MySQL+ NoSQL. Over the very long term, a peer-to-peer architecture will emerge that will become necessary to extend the footprint of the internet of things and allow it to scale.
Q8. Do you already have the piece parts to begin to build out a 2020+ intersystem vision now?
Alan Morrison: Contextual, ubiquitous computing is the vision of the 2020s, but to get to that, we need an intersystem approach. Without interoperation of the four systems I’ve alluded to, enterprises won’t be able to deliver the context required for competitive advantage. Without sufficient entity and relationship disambiguation via machine learning in machine/human feedback loops, enterprises won’t be able to deliver the relevance for competitive advantage.
We do have the piece parts to begin to build out an intersystem vision now. For example, interoperation is a primary stumbling block that can be overcome now. Middleware has been overly complex and inadequate to the current-day task, but middleware platforms such as EnterpriseWeb are emerging that can reach out as an integration fabric for all systems, up and down the stack. Here’s how the integration fabric becomes an essential enabler for the intersystem approach:
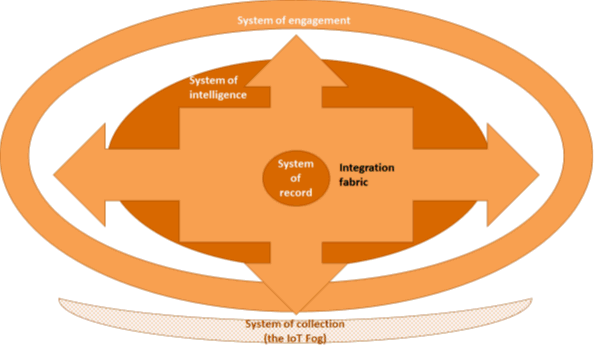
PwC, 2015
A lot of what EnterpriseWeb (full disclosure: a JBR partner of PwC) does hinges on the creation and use of agents and semantic metadata that enable the data/logic virtualization. That’s what makes the desiloing possible. One of the things about the EnterpriseWeb platform is that it’s a full stack virtual integration and application platform, using methods that have data layer granularity, but process layer impact. Enterprise architects can tune their models and update operational processes at the same time. The result: every change is model-driven and near real-time. Stacks can all be simplified down to uniform, virtualized composable entities using enabling technologies that work at the data layer. Here’s how they work:
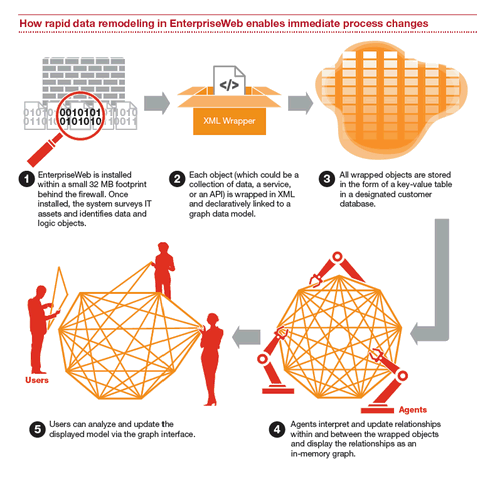
PwC, 2015
So basically you can do process refinement across these systems, and intersystem analytics views thus also become possible.
Qx anything else you wish to add?
Alan Morrison: We always quote science fiction writer William Gibson, who said,
“The future is already here — it’s just not very evenly distributed.”
Enterprises would do best to remind themselves what’s possible now and start working with it. You’ve got to grab onto that technology edge and let it pull you forward. If you don’t understand what’s possible, most relevant to your future business success and how to use it, you’ll never make progress and you’ll always be reacting to crises. Leading enterprises have a firm grasp of the technology edge that’s relevant to them. Better data analysis and disambiguation through semantics is central to how they gain competitive advantage today.
We do a ton of research to get to the big picture and find the real edge, where tech could actually have a major business impact. And we try to think about what the business impact will be, rather than just thinking about the tech. Most folks who are down in the trenches are dismissive of the big picture, but the fact is they aren’t seeing enough of the horizon to make an informed judgement. They are trying to use tools they’re familiar with to address problems the tools weren’t designed for. Alongside them should be some informed contrarians and innovators to provide balance and get to a happy medium.
That’s how you counter groupthink in an enterprise. Executives need to clear a path for innovation and foster a healthy, forward-looking, positive and tolerant mentality. If the workforce is cynical, that’s an indication that they lack a sense of purpose or are facing systemic or organizational problems they can’t overcome on their own.
—————–
Alan Morrison (@AlanMorrison) is a senior research fellow at PwC, a longtime technology trends analyst and an issue editor of the firm’s Technology Forecast
Resources
Data-driven payments. How financial institutions can win in a networked economy, BY, Mark Flamme, Partner; Kevin Grieve, Partner; Mike Horvath, Principal Strategy&. FEBRUARY 4, 2016, ODBMS.org
The rise of immutable data stores, By Alan Morrison, Senior Manager, PwC Center for technology and innovation (CTI), OCTOBER 9, 2015, ODBMS.org
The enterprise data lake: Better integration and deeper analytics, By Brian Stein and Alan Morrison, PwC, AUGUST 20, 2014 ODBMS.org
Related Posts
On the Industrial Internet of Things. Interview with Leon Guzenda , ODBMS Industry Watch, January 28, 2016
On Big Data and Society. Interview with Viktor Mayer-Schönberger , ODBMS Industry Watch, January 8, 2016
On Big Data Analytics. Interview with Shilpa Lawande , ODBMS Industry Watch, December 10, 2015
On Dark Data. Interview with Gideon Goldin , ODBMS Industry Watch, November 16, 2015
Follow us on Twitter: @odbmsorg
##