

On IoT and InfluxDB. Interview with Paul Dix
“Time is a critical context for understanding how things function. It serves as the digital history for businesses. When you think about institutional knowledge, that’s not just bound up in people. Data is part of that knowledge base as well. So, when companies can capture, store and analyze that data in an effective way, it produces better results.” –Paul Dix.
Q1. InfluxData just announced accelerated IoT momentum with new customers and product features. Tell us what makes InfluxDB so well-suited to manage IoT data.
Paul Dix: We’re seeing time series data become vital for success in any industrial setting. The context of time is critical to understanding both historical and current performance. Being able to determine and anticipate trends over time helps companies drive improvements in mission-critical processes, making them more consistent, efficient and reliable. We built InfluxDB to facilitate every step of this process. We’ve been fortunate to work with several major players in the IIoT space already, so we’ve been able to really understand the workflows and processes that drive industrial operations and better develop solutions around them.
Q2. How do the new edge features for InfluxDB that you just announced help developers working with time series data for IoT and industrial settings?
Paul Dix: The new features give developers more flexibility and nimbleness in terms of architecture so that they can build more effective solutions on the edge that account for the resources they have available there. For example, we understand that some companies have very limited resources on the edge, so we’ve made it easier to intelligently deploy configurable packages there. By breaking down the stack into smaller components, developers can reduce the amount of software they need to install and run on the edge. At the same time, we want developers to have the option to do more at the edge if they can. That’s why we’ve made it easier to run analytics on persistent data at the edge and to replicate data from an edge instance of InfluxDB to a cloud instance.
We’re also working to make it easier for IoT/IIoT developers to manage the many devices that they need to deal with. One of our new updates allows developers to distribute processed data with custom payloads to thousands of devices all at once from a single script. On the other side of the equation, we have another new feature that helps contextualize IoT data generated from multiple sources, using Telegraf, our open source collection agent, and MQTT topic parsing.
Q3. What makes time series data so important for IoT and IIoT?
Paul Dix: Time is a critical context for understanding how things function. It serves as the digital history for businesses. When you think about institutional knowledge, that’s not just bound up in people. Data is part of that knowledge base as well. So, when companies can capture, store and analyze that data in an effective way, it produces better results. For example, manufacturers may want to know how long a valve has been in service, or how many parts their current configuration can produce per hour. Time is a constant measure that creates a baseline for comparative purposes, generates a current snapshot for systems and processes, and reveals a roadmap for identified patterns to persist and therefore become more predictable.
Time series data is well-suited to IoT and IIoT because it ties the readings from critical sensors and devices to the context of time. It’s also easy to use persistent time series data for multiple, different purposes. We can think about temperature in this case. In a consumer IoT context, such as a home thermostat, users primarily want to know what the current temperature is. In an IIoT context, manufacturers want to know the current temperature, but also what the temperature was in the last batch, or the batch from the previous week. Using InfluxDB to collect and manage time series data makes these kinds of tasks easy. At InfluxData, we’re fortunate that InfluxDB is one of a select group of successful projects and products where IoT, data, and analytics deliver significant value to organizations and the customers they serve.
Q4. Graphite Energy is featured in the announcement as a company that’s using InfluxDB to manage its time series data. Can you tell us more about the impact InfluxDB has had on its business?
Paul Dix: We’re really excited about our work with Graphite Energy – they’re an Australian company that makes thermal energy storage (TES) units. These devices get energy from renewable sources and store it until it’s required for industrial processes in the form of heat or steam. Its goal is to decarbonize industrial production.
All of Graphite Energy’s operations are grounded in data – they’re collecting time series data from their devices out in the field and use InfluxDB to store and analyze these millions of data points they’re collecting daily. Graphite Energy uses that data to optimize its products, to guide remote operation, engineering and reporting, and to inform product development and research vectors. InfluxDB has also been a key component in the development of their Digital Twin feature. For this, they use time series data to generate a real-time digital model of a TES unit, that is accurate to within five percent of actual device performance. This allows them to roll backward g and forward in time to track performance. The Digital Twin is a key component of the company’s predictive toolkit and ongoing product optimization efforts. The more efficient Graphite Energy’s TES units are, the better they’re able to facilitate decarbonization. That’s a win for everyone.
Q5. How are some of your other IoT customers using the InfluxDB platform?
Paul Dix: Our customers are doing great things in the IoT space. I’ll highlight just a few here quickly.
- Rolls-Royce Power Systems is using InfluxDB to improve operational efficiency at its industrial engine manufacturing facility. By collecting sensor data from the engines of ships, trains, planes, and other industrial equipment, Rolls-Royce is able to monitor performance in real time, identify trends, and predict when maintenance will be needed.
- Flexcity monitors and manages electrical devices for its customers. They also monitor supply-side energy output and use that information to dynamically shed or store excess electrical load in their monitored devices to help with grid balancing and demand response. They use InfluxDB as their managed time series platform. They use Flux to calculate complex, real-time metrics, and take advantage of tasks in InfluxDB for alerting and notifications.
- Loft Orbital: Using InfluxDB Cloud to collect and store IoT sensor data from its spacecrafts. The company flies and operates customer payloads with satellite buses, and uses InfluxDB to gain observability into its infrastructure and collect IoT sensor data, including millions of highly critical spacecraft metrics, with the business currently ingesting 10 million measurements every 10 minutes.
Q6. InfluxData has partnered with some of the leading manufacturing providers including PTC and Siemens. How have these partnerships benefitted shared customers?
Paul Dix: A lot goes into these partnerships on both ends, and we work really hard to make and keep them mutually beneficial. One thing that’s a real benefit to customers is when we’re able to integrate InfluxDB with our partner’s platform. Take PTC, for example. InfluxDB is the preferred time series platform for ThingWorx and there is a native integration within the PTC platform itself. That makes it a lot easier for customers to get up and running with InfluxDB, and because it’s already integrated with PTC, they know the two systems are going to play together nicely. Having a solution like that reduces a lot of time and stress that typically occurs in the development process, especially when building out new solutions or retrofitting old ones.
Beyond PTC, additional industry-leading IIoT platforms including Bosch ctrlX, Siemens WinCC OA, Akenza IoT and Cogent DataHub have also partnered with InfluxData to use InfluxDB as a supported persistence provider and data historian.
Q7. What’s on the horizon for InfluxData and InfluxDB this year? How do you plan to build on this momentum in IoT?
Paul Dix: IoT will continue to be a priority for our team this year. We’re also looking forward to bringing the benefits of InfluxDB IOx to InfluxDB users. InfluxDB IOx is a new time series storage engine that combines several cutting-edge open source technologies from the Apache Foundation. Written in Rust, IOx uses Parquet for on-disk storage, Arrow for in-memory storage and communication, and Data Fusion for querying. IOx focuses on boundless cardinality and high performance querying.
IoT and IIoT users will benefit from IOx since they will have the ability to use InfluxDB and its related suite of developer tooling for emerging operational use cases that rely on events, tracing, and other high cardinality data, along with metrics. We’re eager to integrate this project into our existing platform so our IoT users can monitor any number of assets without worrying about the volume or variety of their data.
The arrival of IOx to our cloud platform will enable IoT and IIoT users to store, query, and analyze higher precision data and raw events in addition to more traditional metric summaries. In addition to the real-time replication currently enabled from the edge with Telegraf and InfluxDB 2.0, IOx will enable bulk replication of Parquet files for settings where the edge may not have real-time connectivity. Users working with machine learning libraries in Python will find it easier to connect to and retrieve data at scale for training and predictions because of IOx’s support for Apache Arrow Flight.
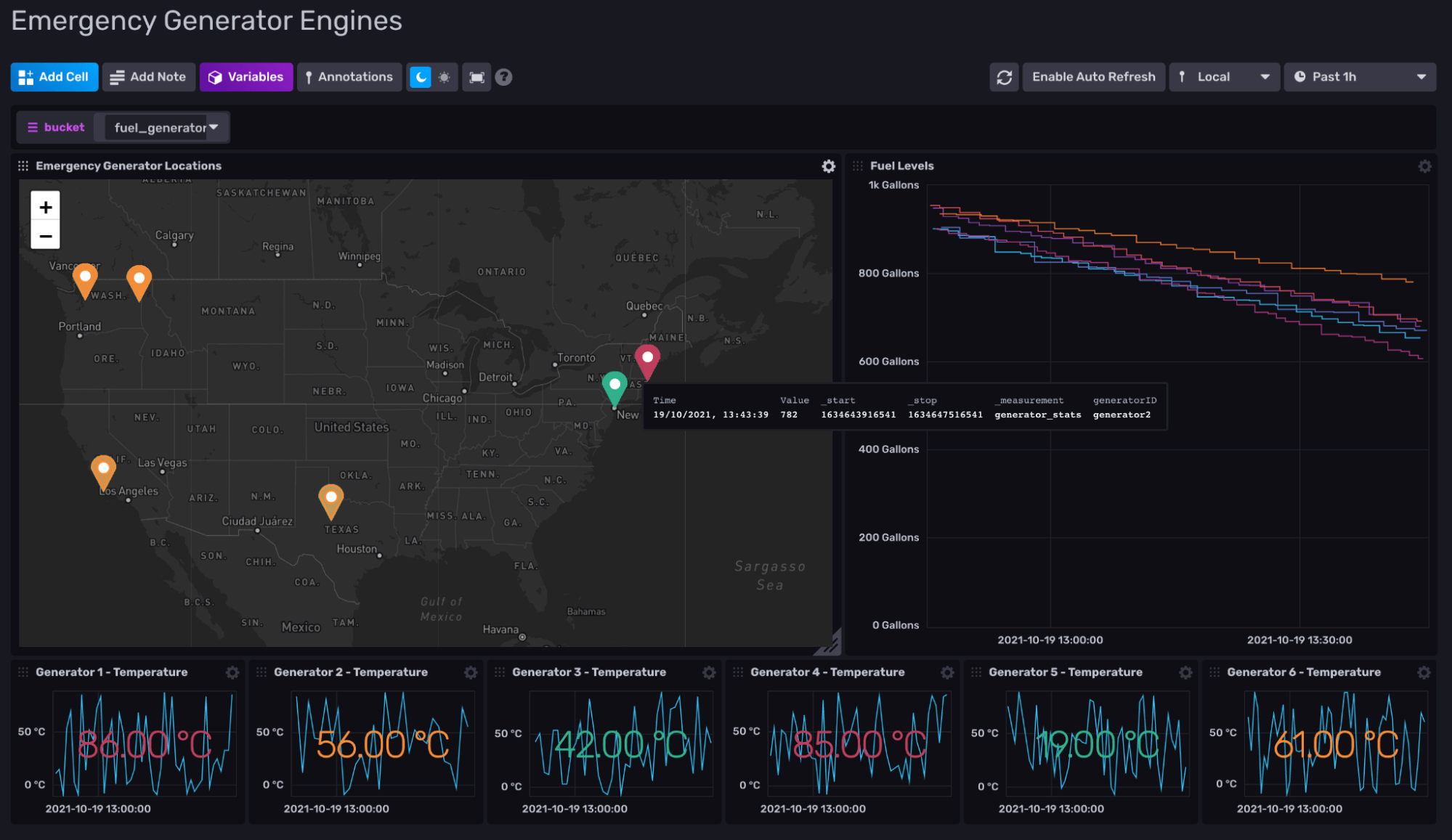
Qx. Anything else you wish to add?
Paul Dix: The big takeaway is we’re really excited about the many applications for time series in IoT. Regardless of industry, time series is transforming our ability to understand the activities and output of people, processes and technologies impacting businesses. Nowhere is this more apparent than in IoT or industrial settings.
…………………………………………………….

Paul Dix is the creator of InfluxDB. He has helped build software for startups, large companies and organizations like Microsoft, Google, McAfee, Thomson Reuters, and Air Force Space Command. He is the series editor for Addison Wesley’s Data & Analytics book and video series. In 2010 Paul wrote the book Service-Oriented Design with Ruby and Rails for Addison Wesley’s. In 2009 he started the NYC Machine Learning Meetup, which now has over 7,000 members. Paul holds a degree in computer science from Columbia University.
Resources
Related Posts
On IoT and Time Series Databases. Q&A with Brian Gilmore. ODBMS.org, October 18, 2021.
Follow us on Twitter: @odbmsorg
##