

On Cloud Database Management Systems. Interview with Rahul Pathak.
IT teams no longer want to be consumed by undifferentiated heavy lifting so that they can focus on strategic business goals and innovation. This is very liberating, and we believe that this is a major growth driver.
Q1: In your opinion what is the status of the database market today and in the next years to come?
Rahul: The broader database market trend is more of a question for analysts. Our unwavering focus is to continue innovating on behalf of customers to make advanced database features more approachable while reducing the costs and complexities of maintaining databases. IT teams no longer want to be consumed by undifferentiated heavy lifting so that they can focus on strategic business goals and innovation. This is very liberating, and we believe that this is a major growth driver.
Q2: You just wrapped up re:Invent 2022. Is re:Invent the high point of the year in terms of your database announcements?
Rahul: re:Invent is always an exciting and energizing event. That said, we actually release new innovations throughout the year, when they are ready. For example, we released some big innovations earlier in 2022, like Amazon Aurora Serverless v2, Amazon RDS Multi-AZ with two readable standbys, and a whole lot more. We also have announcements at re:Invent in addition to providing attendees a hands-on learning experience of our services.
Q3: Can you share some details on these more notable launches prior to re:Invent?
Rahul: Absolutely. We launched Amazon Aurora Serverless v2 (ASv2), which provides customers the ability to instantly scale up and down in fine grained increments based on their application’s needs. ASv2 is particularly useful for spiky, intermittent, or unpredictable workloads. Manually managing database capacity can take up valuable time and can lead to inefficient use of database resources. With ASv2, customers only pay on a per-second basis for the database capacity that you use when the database is active. ASv2 has become the fastest adopted feature in the history of Aurora. Customers, like Liberty Mutual, S&P Global, and AltPlus, have used ASv2 to reduce their costs while achieving improved database performance.
Another feature launch that has proven compelling to customers is the release of Amazon RDS Multi-AZ with two readable standbys in different AZs, improving both performance and availability. As you may know, we launched Multi-AZ deployment back in 2020 in which we automatically create a primary database (DB) instance and synchronously replicate the data to an instance in a different AZ. When it detects a failure, Amazon RDS automatically fails over to a standby instance without manual intervention. Now, the launch of Multi-AZ two standbys adds another layer of protection and significant performance benefits. With this feature, failovers typically occur in under 35 seconds with zero data loss and no manual intervention. Customers can gain read scalability by distributing traffic across two readable standby instances and up to 2x improved write latency compared to Multi-AZ with one standby.
Q4: During re:Invent, it was mentioned that AWS also recently launched serverless and global database for your graph database, Amazon Neptune. Can you share some details on this?
Rahul: Yes, Amazon Neptune is now our sixth database to be serverless and our fifth database with ability to scale reads globally across regions. Both of these capabilities are important for modern day applications with global performance requirements at scale. I should also mention that for our first ever serverless database, Amazon DynamoDB, we recently announced the capability to import data from S3. This further underscores our focus on increasing interoperability and integration across our services to minimize effort by customers in moving their data to where they need it.
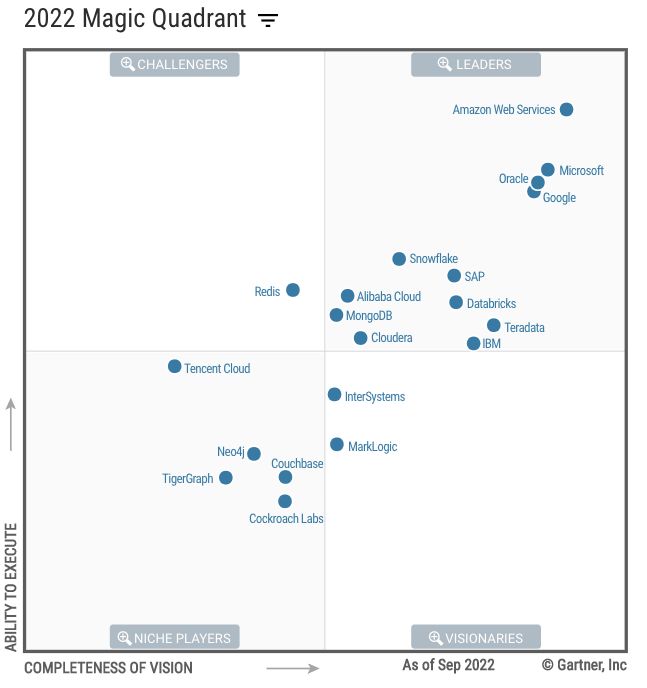
Q5: On the heels of re:Invent, AWS became the new Leader of Leaders in the Gartner MQ for Cloud Database Management Systems 2022. That’s a remarkable achievement. How is AWS thinking about this recognition? What are the main strengths that Gartner found in your offering? Are there any weaknesses?
Rahul: While AWS has been named as a leader for the eighth consecutive year, we were elated and humbled to be positioned highest in execution and placed furthest in vision among the top 20 data and analytics companies in the world. We think listening to our customers and solving their most challenging problems is key. We engage closely with customers on product roadmaps and work diligently to deliver on our commitments as promised. Our own experience in operating our e-commerce business has and continues to also be a wellspring of learnings for what it takes to build massive modern internet scale applications serving customers on a global scale.
In their 2022 report, Gartner called out the breadth of our services as a major strength. Our best-fit philosophy, targeted to specific use cases as needed by various applications and microservices, is really paying off. No vendor ever gets a perfect score and Gartner also noted that there is still upside from better integration between our sevices. Gartner gave us credit for a progress towards an integration roadmap, and this continues to be a major roadmap theme for us. At re:Invent, we announced Amazon Aurora zero-ETL integration with Amazon Redshift, and we’re eager to continue delivering on our integration roadmap. You can read the report here.
Q6. What were the overarching themes around your announcements at re:Invent 2022?
Rahul: Our database business tracks several themes that we deliver against. Of these themes, there were three that were at the center of our announcements. These themes were interoperability across services, advancing performance and scale, and operational excellence by making security and advanced operational techniques more approachable.
Q7: Why are these themes important?
Rahul: Interoperability across our services is important because it improves productivity across development and operations teams. Integration between services is needed as part of building modern applications. It’s a question of where the integration occurs. Application developers often have to include this integration as part of their application code or solution architects must take extra measures to include additional integration components which increases complexity. If the integration is built in under the covers, then that’s one big area developers and architects don’t need to worry about.
Performance and scale are important because of the deluge of data and types of data organizations are experiencing and will continue to experience. For almost every organization this deluge of data is a clear and present day-to-day reality. Customers need reassurance that they can scale-up and scale-out with real-time performance.
Finally, the approachability of security and advanced operational techniques removes big hurdles that get in the way of organizations that don’t want to make massive investments in IT operations and specialized skills. It levels the playing field for the undifferentiated heavy lifting – things that are not core to the business but necessary for advancing the mission of the business. The definition of undifferentiated heavy lifting is expanding. Years ago, we started by removing the resources associated with hardware provisioning, database setup, patching, backups, and more. This is expanding to scaling up/down and scaling in/out based on an application’s needs, and removing the highly specialized skill sets and extensive resources otherwise required.
Q8: What did AWS announce in support of interoperability across services?
Rahul: We announced the preview of interoperability between Amazon Aurora and Amazon Redshift. Each of these services leads in their categories – Amazon Aurora as an operational database and Amazon Redshift as an analytical database.
The traditional approach to integration between operational and analytical databases is to use generalized ETL or ELT. This is beset with problems in so many ways. It’s complex and heavy, often requiring manual coding of SQL to optimize query performance. It’s harder to setup, maintain and use. Maintenance and the lifecycle management of this type of data integration is worsened by the inherent fragility of this approach – the integration breaks when there is a change to the source or target schema. This requires extensive testing after every change. What you get after taking on all these burdens is usually a low performance, non-elastic solution that doesn’t adapt well to changing workloads.
We announced the preview of a purpose-built, point-to-point, fully managed integration that doesn’t suffer from these issues. Our Amazon Aurora zero-ETL integration with Amazon Redshift can consolidate data from multiple Aurora databases to a single Redshift database, giving you the benefit of near-real-time analytics on unified data. This opens up an entire category of use cases for time sensitive analytics on fresh data.
The integration is easy to setup – creating a Redshift integration target, whether it’s a new or existing endpoint, is easy. Furthermore, we designed this zero-ETL integration for easy maintenance adapting to Aurora side schema changes. Database or table additions and deletions are handled transparently. If a transient error is encountered, the integration automatically re-synchs after the recovery from the error.
Data is replicated in parallel, within seconds. So large data volumes are not a problem. On the Amazon Redshift side, you can transform data with materialized views for improving query performance.
Q9: Now shifting to performance and scale, what are the highlights?
Rahul: We announced three key new features starting with Amazon DocumentDB Elastic Clusters which will horizontally scale writes with automated operations. As you may know, we can already horizontally scale reads across all our popular databases using read replicas. For Amazon DocumentDB, our customers needed the ability to horizontally scale writes beyond limits of a single node. Amazon DocumentDB Elastic Clusters uses sharding, a form of partitioning data across multiple nodes in a cluster, so that each node can support both reads and writes in a multi-active approach. When data is written to a node it is immediately replicated to the other nodes. This has the added benefit of supporting massive volumes of data. What’s exciting is Amazon DocumentDB can scale to handle millions writes (and reads) per second with petabytes of storage capacity.
In addition to horizontal scaling, we also invested in optimizing the performance of a single database instance. Our announcement of Amazon RDS Optimized Writes and Amazon RDS Optimized Reads for MySQL are examples of this. Both of these enhancements improve our internal implementation to improve performance.
Prior to RDS Optimized Writes, atomicity of writes was handled by writing pages twice. Smaller chunks of a page were first written to a “doublewrite buffer” and then written to storage. This protects against data loss in case of failure, but two writes take longer and consume more I/O bandwidth reducing database throughput and performance. For use cases with a high volume of concurrent transactions, to solve for durability customers also need to provision additional IOPS to meet their performance requirements. Optimized writes work by atomically writing more data to the database for each I/O operation. So, this means that the pages are written to table storage durably as a single atomic operation in one step. With Optimized Writes, customers can now gain up to 2x improvement in write transaction throughput at no additional cost and with zero data loss.
With RDS Optimized Reads, read performance is improved by leveraging data proximity. A MySQL server creates internal temporary tables while processing complex or unoptimized queries like analytical queries that require grouping, sorting etc. When these temporary tables cannot fit into memory, the server defaults to disk storage. With Optimized Reads, RDS places these temporary tables on the instance’s local storage instead of an Elastic Block Storage volume, which is shared network storage. It’s the local availability of temporary data that makes queries up to 50% faster.
Q10: How about security and operational excellence, what did AWS announce for this theme?
Rahul: Security is of utmost importance and an area of sustained investment for us. We announced the preview of Amazon GuardDuty RDS Protection, which protects Amazon Aurora databases from suspicious login attempts that can lead to data exfiltration and ransomware attacks. It does this by identifying anomalies, sending intrusion alerts, managing stolen credentials, and more. Our goal with GuardDuty was to create a tool that’s easy to enable and produces timely, actionable results. We use machine learning to accurately detect highly suspicious activities like access attacks using evasion techniques. Security findings are enriched with contextual data so you can quickly answer questions such as what database was accessed, what was anomalous about the activity, has the user previously accessed the database, and more. Aurora is the starting point. We’ll also extend this capability to other RDS engines.
We also announced Trusted Extensions for PostgreSQL, an open-source development kit and project, available for Amazon Aurora and Amazon RDS. This project is focused on increasing the security posture for extensions starting with PostgreSQL.
Developers love PostgreSQL for many reasons including the thousands of available extensions, but adding extensions can be risky. This makes certification of extensions very important. Our customers asked us for an easier way to use their extensions of choice and also build their own extensions. It’s impractical for AWS to certify the long tail of extensions, so we worked with the open-source community to come up with a more scalable model.
Trusted Language Extensions for PostgreSQL is a framework that empowers developers and operators to more safely test and certify extensions. Now, as soon as a developer determines an existing extension meets their needs or is ready to implement a custom extension, they can safely test and deploy it in production. Developers no longer need to wait for AWS to certify an extension to begin implementation because Trusted Language Extensions are considered to be part of your application. It provides a safe approach because the impact of any defects in an extension’s code is limited to a single database connection. Trusted Language Extensions supports popular programming languages that developers love including JavaScript, Perl, and PL/pgSQL. We do plan to support other programming languages so stay tuned for announcements in 2023.
Q11: What else did AWS launch for making advanced operational techniques more approachable?
Rahul: I am also excited about Amazon RDS Blue/Green Deployments, which automates an advanced DevOps technique – and this is available for MySQL in both Amazon RDS and Amazon Aurora. In the current atmosphere of 24/7 operations, downtime for updates (security patches, major version upgrades, schema changes, and more) or disruptions or data loss due to failed attempts at updates are not acceptable.
In this DevOps technique, the production environment is the ‘blue’ environment and the staging environment is the ‘green’ environment. For organizations with advanced DevOps skills, they will test new versions of software in a ‘green’ environment under a production load, before actually putting it in production. But this requires advanced operational knowledge, careful planning and time. With RDS Blue/Green Deployments, we provide a fully managed staging environment. When an upgrade is deemed to be ready, the database can be updated in less than a minute with zero data loss – a much simpler, safer and faster approach to database updates.
Another launch is AWS Database Migration Service (DMS) Schema Conversion making heterogeneous migrations operationally easier. Previously, a separate schema conversion tool was needed for mapping the data at the source database to the target database. Now the schema conversion is integrated with DMS, making schema assessments and conversions much simpler. Heterogenous schema conversion can now be initiated with a few simple steps, reducing set up time from hours to minutes.
Q12: Would you like to add anything else?
Rahul: A good way to come up to speed with the latest from AWS and the art of the possible is to watch recordings from re:Invent. We showcased product announcements and a breadth of sessions that cover our product roadmap and best practices. You can also learn more from our database category page, and database blog. We’re energized and focused on innovating for our customers! Feedback is always welcome and I encourage all customers to reach out so we can help no matter where they may be on their journey to the cloud – simply complete our Contact Us form.
………………………………..

Rahul Pathak is Vice President, Relational Database Engines at AWS, where he leads Amazon Aurora, Amazon Redshift, and Amazon QLDB, AWS’ core relational database engine technologies. Prior to his current role, he was VP, Analytics at AWS where he led Amazon EMR, Amazon Redshift, AWS Lake Formation, AWS Glue, Amazon Athena, and Amazon OpenSearch Service. During his 11+ years at AWS, Rahul has focused on managed database and analytics services with previous roles leading Emerging Databases, Blockchain, RDS Commercial Databases, and more. Rahul has over twenty-five years of experience in technology and has co-founded two companies, one focused on digital media analytics and the other on IP-geolocation. He holds a degree in Computer Science from MIT and an Executive MBA from University of Washington.
Resources
AWS positioned highest in execution and furthest in vision
Gartner has recognized Amazon Web Services (AWS) as a Leader and positioned it highest in execution and furthest in vision in the 2022 Magic Quadrant for Cloud Database Management Systems among 20 vendors evaluated. This Magic Quadrant report provides cloud data and analytics buyers with vendor insights based on Gartner research criteria. AWS has been a Leader in the report for eight consecutive years.
Magic Quadrant for Cloud Database Management Systems
Published 13 December 2022 – ID G00763557 – 71 min read
Figure 1: Magic Quadrant for Cloud Database Management Systems (source Gartner (December 2022)
Related Posts
EXPERT ARTICLES DECEMBER 16, 2022
Deep Dive Amazon DocumentDB Elastic Clusters. Q&A with Vin Yu
Follow us on Twitter: @odbmsorg