Introduction to Machine Learning with Apache® Ignite™
Wednesday, June 6 2018 | by
In a previous article, we discussed the Apache® Ignite™ Machine Learning Grid. At that time, a beta release was available. Subsequently, in version 2.4, Machine Learning became Generally Available. Since the 2.4 release, more improvements and developments have been added, including support for Partitioned-Based Datasets and Genetic Algorithms. Many of the Machine Learning examples that are provided with Apache Ignite can work standalone, making it very easy to get started. However, later in this series of articles, we will perform some analysis on several freely available datasets using some of the algorithms that are supported by Ignite.
Introduction
In this first article, we will begin with an overview and introduction to the Machine Learning Grid, graphically shown in Figure 1.
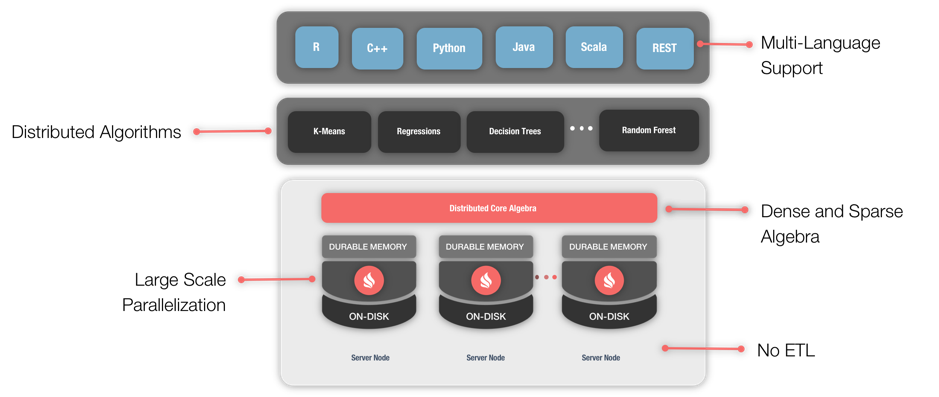
Figure 1. Machine Learning Grid.
The Machine Learning capability provided by Apache Ignite is designed to be very practical and enables the building of predictive models directly within Ignite. This allows users to achieve scale and performance without costly ETL or data transfer. Let’s discuss this in a little more detail.
First, previously with Ignite, Machine Learning models would need to be trained and deployed on different systems. For example, data would need to be moved out of Ignite, then training would be performed using other tools and, finally, models would be deployed into production systems. This previous approach has several drawbacks:
- There is a costly ETL process, particularly for very large datasets. Datasets may potentially be hundreds of Gigabytes or Terabytes in size.
- Using ETL, we are taking a snapshot of the data. After ETL, the data may have changed in the live system, so leaving the system with out-of-date training data.
Second, many systems today may need to work with very large quantities of data that usually exceed the capacity of a single server. Distributed computing offers a solution, but some platforms are not designed for storage and manipulation of data and may only be suited for training purposes. So, developers may need to consider complex solutions for deployment in production environments.
Today, the Machine Learning capabilities of Ignite solve all these problems, and more:
- Ignite can work on the data in-place, avoiding costly ETL between different systems.
- Ignite can provide distributed computing that includes both the storage and manipulation of data.
- The Machine Learning algorithms implemented in Ignite are optimized for distributed computing and can use Ignite’s collocated processing to great advantage.
- Ignite can act as a sink for streaming data, allowing Machine Learning to be applied in real-time.
- Machine Learning is often an iterative process, and data may change whilst an algorithm is running. Therefore, to avoid loss of work and delay, Ignite supports Partition-Based Datasets which makes it tolerant to node failures.
Partition-Based Datasets
Apache Ignite now supports Partition-Based Datasets. This is an abstraction layer that sits between a Machine Learning algorithm and the storage and computation. It uses a MapReduce-like operation for computation and cache backups for fault-tolerance.
In Ignite, a hash algorithm is applied to the Key part of a Key-Value (K-V) pair to determine where the Value part is stored in a cluster. The Value part is actually stored in a partition. Partitions are atomic. In Figure 2, we can see a two-node cluster, with two partitions (P1 and P2).
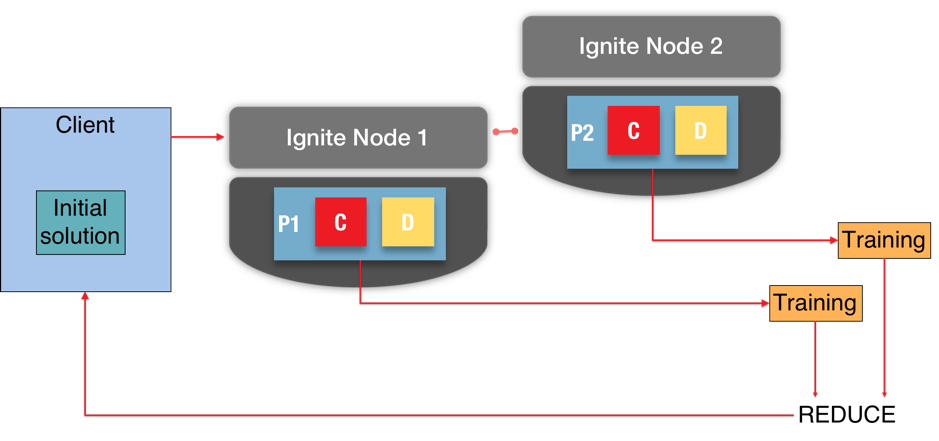
Figure 2. Partition-Based Dataset.
Machine Learning algorithms are often iterative and require context and data. In Figure 2, these are shown as C and D, respectively, in each partition.
In the event of a node failure, Ignite can recover the partition and context, as shown in Figure 3. For example, if we have a backup (shown in grey) of P1 on node 2, we can recover P1 from node 2 if node 1 fails. Data may be recovered from the cluster or through local ETL (marked D*).
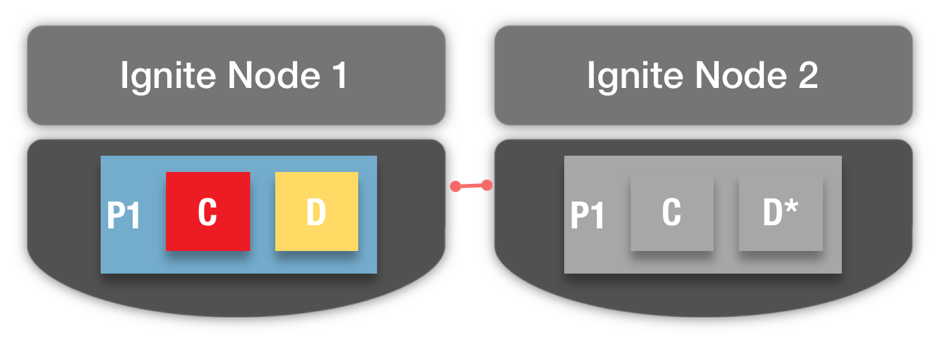
Figure 3. P1 Backup on node 2.
Algorithms and Applicability
Now, let’s look at the Machine Learning algorithms that Ignite supports. These are summarized in Table 1.
| Classification | Regression | Clustering | Preprocessing | |
| Description | Identify to which category a new observation belongs, on the basis of a training set of data | Modeling the relationship between a scalar dependent variable y and one or more explanatory variables x | Grouping a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups | Feature extraction and normalization |
| Applicability | spam detection, image recognition, credit scoring, disease identification | drug response, stock prices, supermarket revenue | customer segmentation, grouping experiment outcomes, grouping shopping items | transform input data, such as text, for use with machine learning algorithms |
| Algorithms | SVM, nearest neighbor, decision tree classification, neural network | linear regression, decision tree regression, nearest neighbor, neural network | k-means | Normalization preprocessor |
Table 1. Machine Learning Algorithms.
The Machine Learning library also ships with a set of Genetic Algorithms, which have been discussed in another blog post.
Summary
The latest release of Apache Ignite provides a number of important features and capabilities. A Partition-Based Dataset provides the ability to continue processing Machine Learning algorithms in the event of node failure, by preserving context. The Machine Learning algorithms support a wide-range of use-cases. The addition of Genetic Algorithms also provides new opportunities for working with complex data.
