On Redis. Q&A with Yiftach Shoolman,Founder and CTO of Redis Labs
Q1. Redis Labs recently introduced a new engine for the RedisGraph module based on GraphBlas. What is it? What is it useful for?
Traditionally, graph operations in Redis were based on data structures like the hexastore or adjacency list, which require developers to write less efficient code in order to execute graph traversal operations. For example, see this approach to “find the next BFS (Breadth-First-Search) level” below:
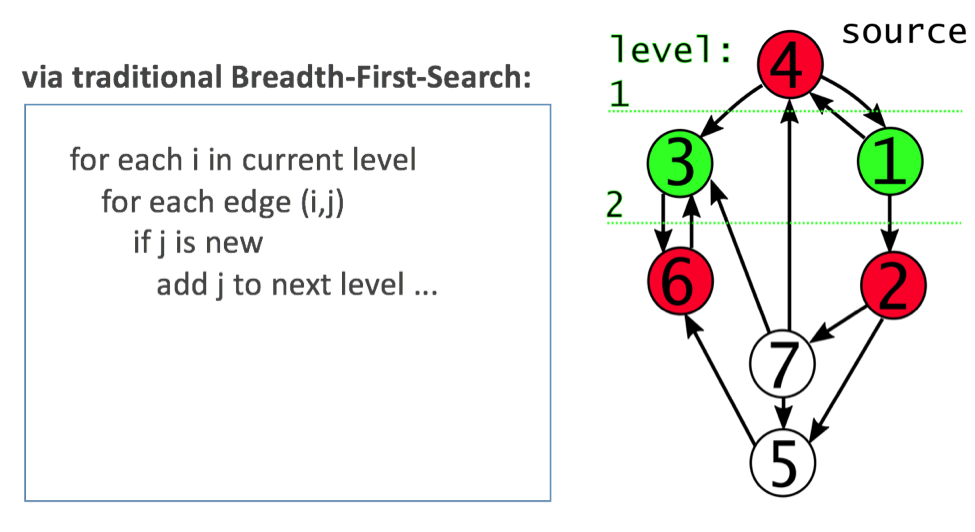
Instead, GraphBLAS (Basic Linear Algebra Subprograms) represents graphs with an intuitive adjacency matrix: a square table with all nodes along each axis, and a value of ‘1’ for each connected pair. Our new engine uses linear algebra of matrices to execute graph traversal operations, which makes query processing much more efficient. For example, the matrix below represents the connected graph from the example above, in which each column (1-7) represents a source node and each row (1-7) represents a destination node:

Naively implemented, the traditional approach scales terribly for graphs that model real-world problems, which tend to be very sparse. Space and time complexity for a matrix are governed by its dimensions (O(n²) for square matrices), making alternatives like adjacency lists more appealing for most practical applications with scaling requirements.
The GraphBLAS library gives developers the benefits of matrix representations, while optimizing for sparse data sets. GraphBLAS encodes matrices in compressed sparse column (CSC) form, which has a cost determined by the number of non-zero elements contained. In total, the space complexity of a matrix is:
(# of columns + 1) + (2 * # of non-zero elements)
This encoding is highly space-efficient, and also allows us to treat graph matrices as mathematical operands. As a result, database operations can be executed as algebraic expressions without needing to first translate data out of a form (like a series of adjacency lists). For example, finding the next BFS on the graph from above is as simple as joining the 1’s of column #1 with column #3, or in matrices algebra terms – multiplying the graph matrix with a filter vector for column #1 & #3:
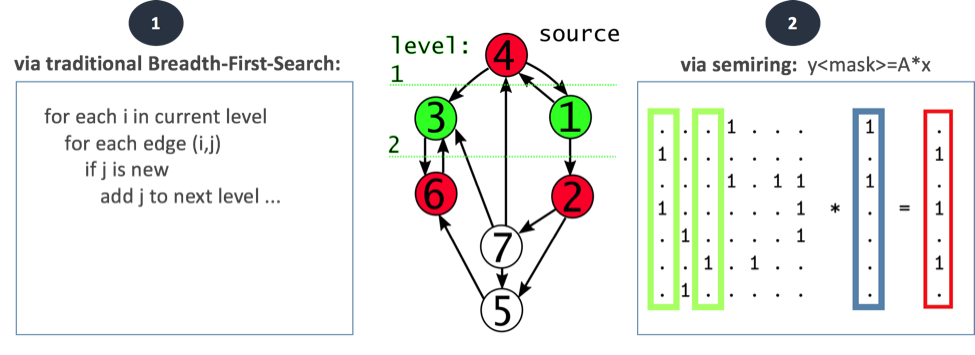
Q2. Why did you choose GraphBLAS?
As explained above, GraphBLAS provides two main benefits:
- Space efficiency – GraphBLAS provides a compressed representation of sparse matrices using compressed sparse column form.
- Speed – by using the suitesparse library, developed by Tim Davis, who has worked closely with us to integrate his work as effectively as possible. This includes GraphBLAS algorithms in the language of linear algebra for efficient graph operations.
Q3. How does the RedisGraph module compare to existing graph databases?
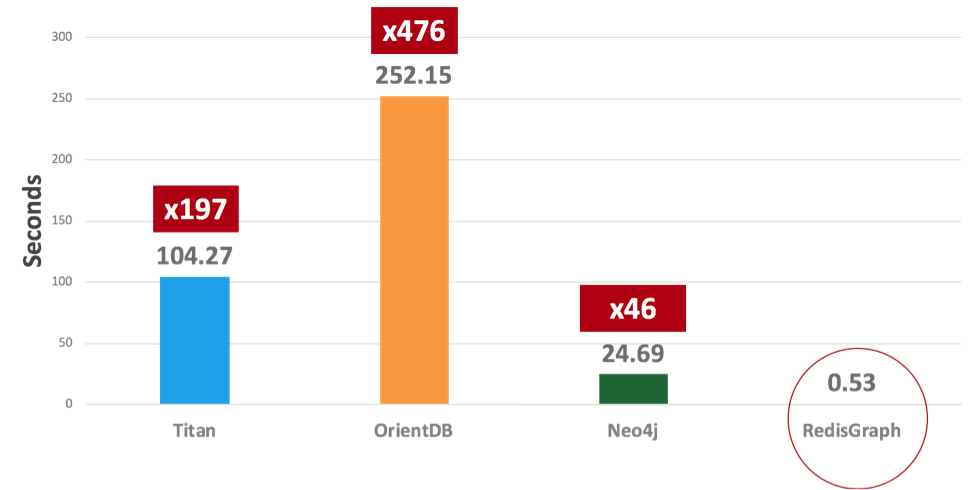
The RedisGraph module, based on GraphBLAS engine, shows significant performance advantages over existing graph databases, as can be seen from the results of an initial benchmark we ran.
We tested:
- Graphdb-benchmark – https://github.com/socialsensor/graphdb-benchmarks
- Data set with 1,134,890 nodes and 2,987,624 edges
- ‘Massive insertion’ operation
This is what we got:
We then tested a ‘find neighbors’ operation, and got the following results:
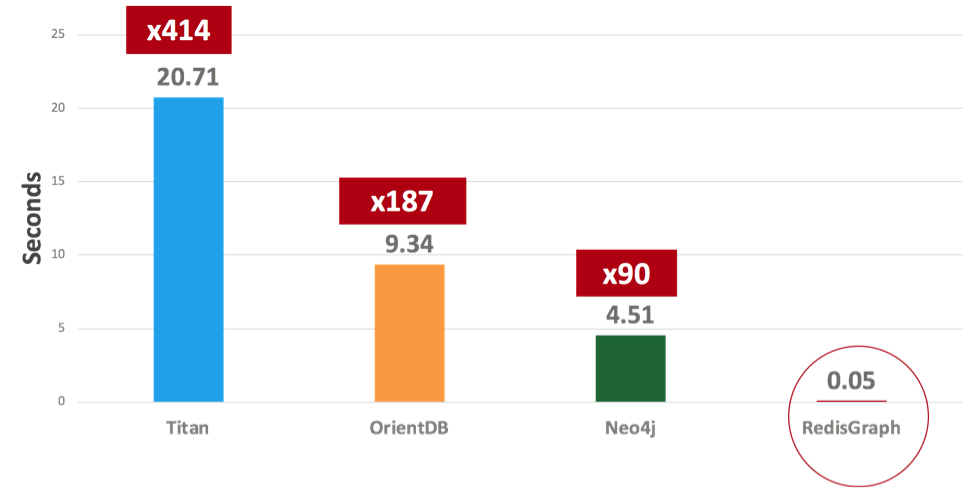
Eventually, we also tested memory usage and found that, on average, RedisGraph can reduce memory usage by 60-70%.
Q4. What are the problems that are solved by CRDTs in an Active-Active replicated database?
Redis CRDTs (Conflict-Free Replicated Data Types) solve two major problems in existing active-active solutions:
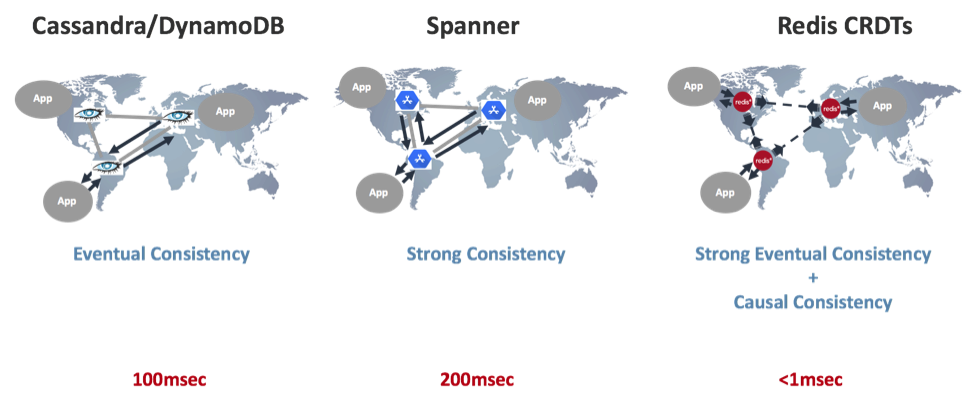
- Multi-region WAN (Wide Area Network) latency. Any active-active solution available in the marketplace today, whether based on eventual consistency (like Cassandra or DynamoDB) or on strong/external consistency (like Spanner), requires you to run a consensus protocol between peer replicas for ‘read’ and ‘write’ operations. Otherwise, your data set can easily reach an inconsistency state that practically means over 100msec average latency for each operation, as illustrated below:
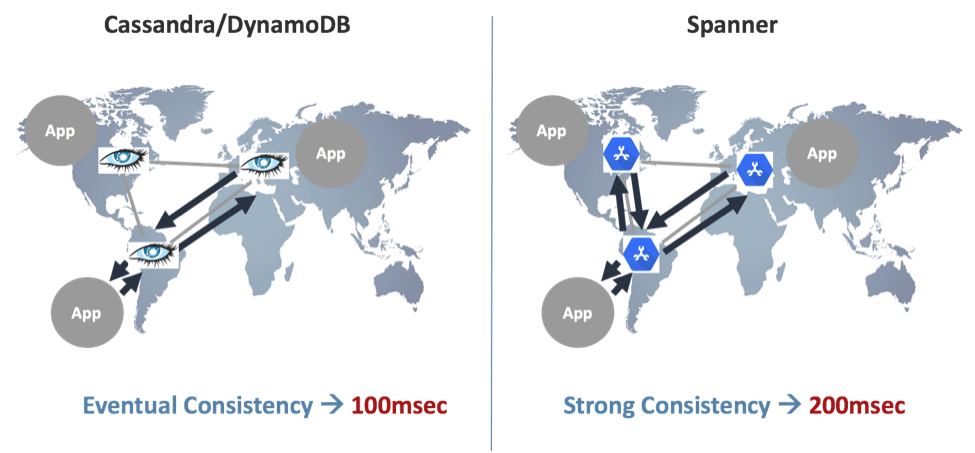
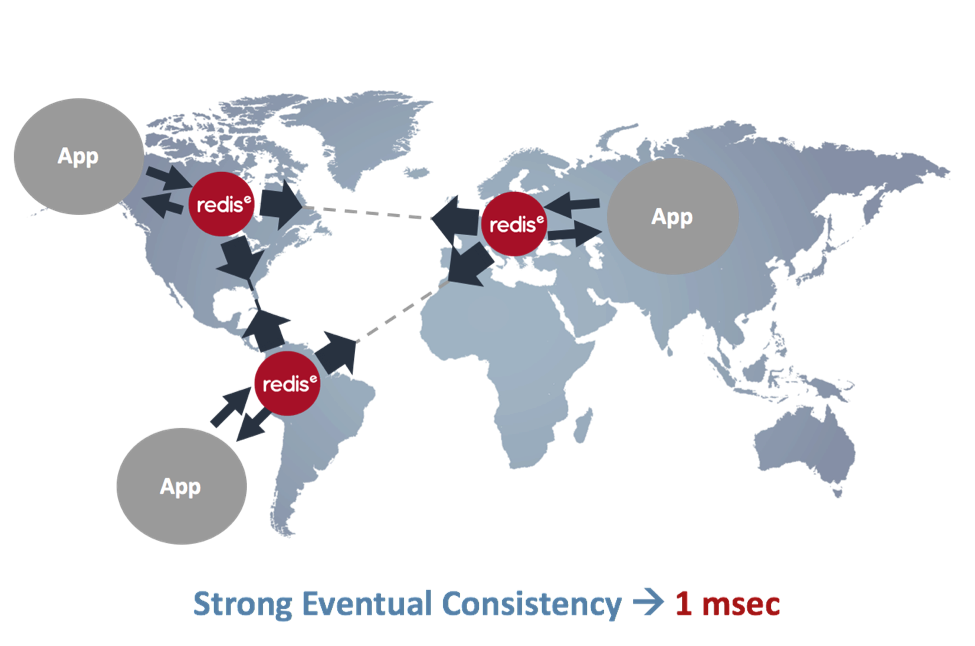
CRDTs (in general) and Redis CRDTs (in particular) don’t need a consensus protocol in order to reach a consensus. Instead, the user gets an immediate response for every ‘read’ or ‘write’ operation (as if it were a local Redis). Asynchronously, Redis CRDTs then update all the replicas using what’s called a merge operation. CRDTs guarantee that all replicas will be converged to the same value. This mechanism is also called Strong Eventual Consistency (SEC) and it’s further explained here.
Maintaining the sub-millisecond experience is crucial for most applications that use Redis — otherwise a fast in-memory database wouldn’t have been considered. The figure below illustrates how Redis CRDTs operate in a typical active-active deployment:
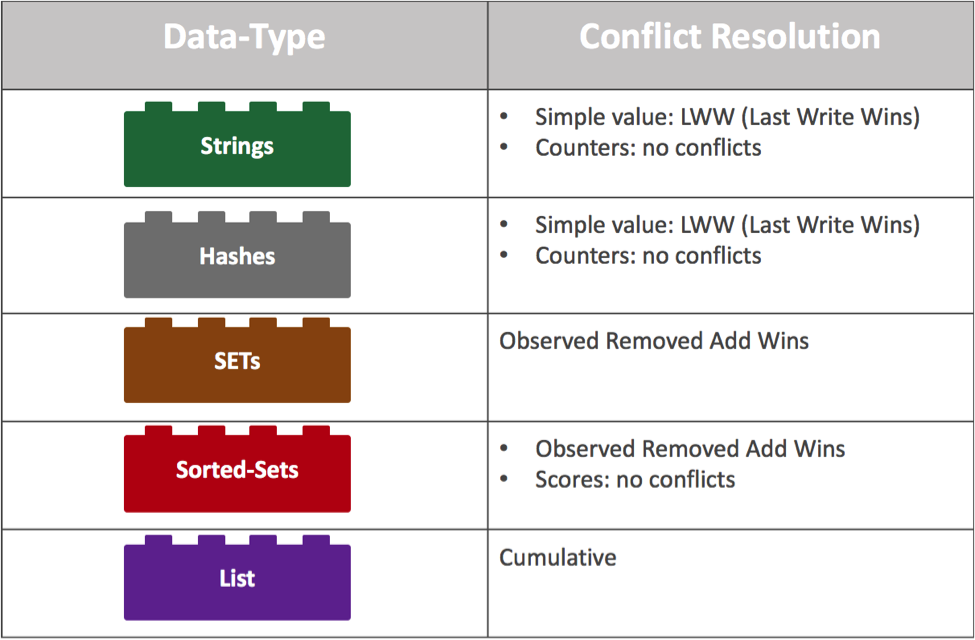
2. In addition, conflict resolution is a hard problem to solve. In most cases, you would prefer not to solve it at the application level, as (1) it’s complex and in many cases your data set may end up in an inconsistent state; (2) it’s slow as it requires application intervention in any database operation. Traditional database implementations have chosen the simple Last Write Win (LWW) mechanism in order to decide which operation wins. Although LWW is good for simple data types, it can lead to a complete data loss in more advanced data types, such as Redis SET, Sorted Set, List and others, which is totally unacceptable. In many cases, LWW also assumes that replicas’ clocks are in sync and use time stamps to decide which replica wins in case of a conflict. However, syncing clocks across regions requires special hardware like what is implemented by Google True Time.
CRDTs and hence Redis CRDTs have taken a different approach to conflict resolution, in which each data type has a dedicated mathematically proven mechanism for resolving conflicts. This is completely transparent to the application and guarantees that any two replicas that have received the same (unordered) set of updates will be in the same state. In addition, Redis CRDTs were developed by experienced Redis developers who created open source Redis. The code is implemented as a Redis module, written in C and running completely in memory — ensuring that every operation is implemented with minimal overhead and as close as possible to vanila Redis performance. The figure below highlights the conflict resolution used by Redis CRDTs for each of Redis’ major data types:
Q5. Redis Enterprise supports tunable causal consistency. How is it different from similar concepts of consistency offered by other NoSQL databases?
Redis Labs offers multiple levels of consistency based on deployment models:
- A single cluster deployment – strong consistency
- An active-passive deployment – strong consistency on the active cluster (i.e. the cluster that gets read and write operations) and eventual consistency on the passive clusters (i.e the clusters that get only read operations)
- An active-active deployment – strong eventual consistency with causal consistency on all clusters
When enabled, causal consistency in the context of Redis CRDTs guarantees that the order of operations will be maintained across all participant replicas of an active-active deployment.
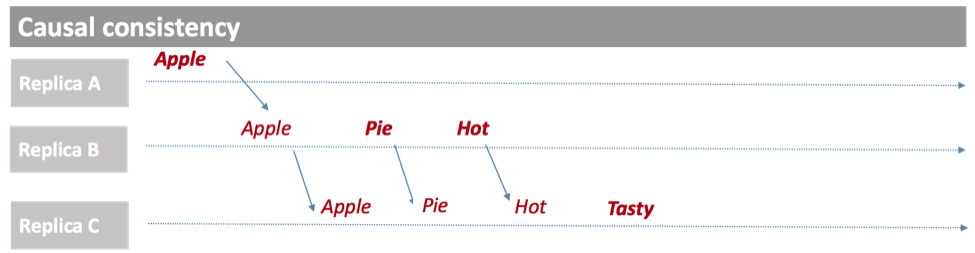
For example, in the Source FIFO Consistency illustrated below, Replica B and Replica C see a different order of events, which may lead to inconsistent application behavior.
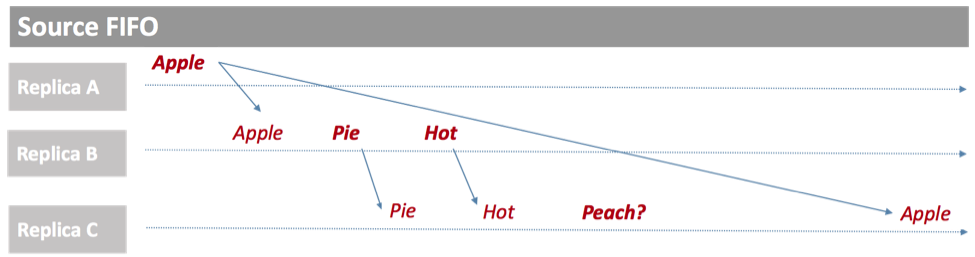
With causal consistency, the order of events is maintained, as below:
To sum it up, Redis CRDTs maintain the sub-millisecond latency of local Redis and provide similar characteristics to strong consistency with the combination of strong eventual consistency and causal consistency. The figure below summarizes the consistency methods being used by popular distributed databases with their performance implications:
Q6. Kubernetes is becoming an industry standard for managing containerised applications. Can you provide a robust Redis Enterprise deployment on Kubernetes? If yes, how?
We use four important principles to deploy Redis Enterprise on Kubernetes, which guarantee robust deployment:
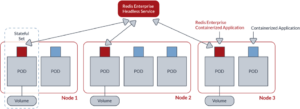
- Deployment based on operator, using Kubernetes statefulset with anti-affinity. Operator allows us to maintain a unified deployment across all Kubernetes environments, i.e. RedHat OpenShift, Pivotal Container Services (PKS), Google Kubernetes Engine (GKE), Azure Kubernetes Service (AKS), Amazon Elastic Container Service for Kubernetes (EKS) and vanilla Kubernetes. Statefulset and anti-affinity guarantee that each Redis Enterprise node resides on a POD that is hosted on a different VM/physical server. This setup is illustrated in the figure below:
- Network-attached persistent storage to guarantee data durability. Kubernetes and cloud native environments require that storage volumes be network-attached to the compute instances. Otherwise, if local storage is used, your data can be lost in a POD failure event. This is illustrated nicely in the figure below:
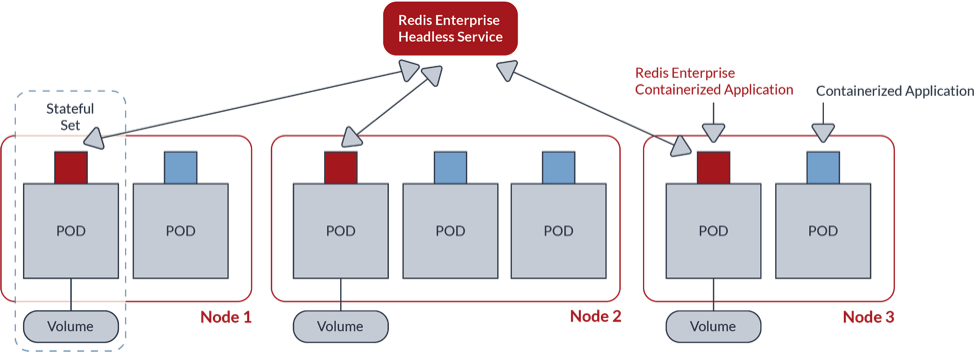
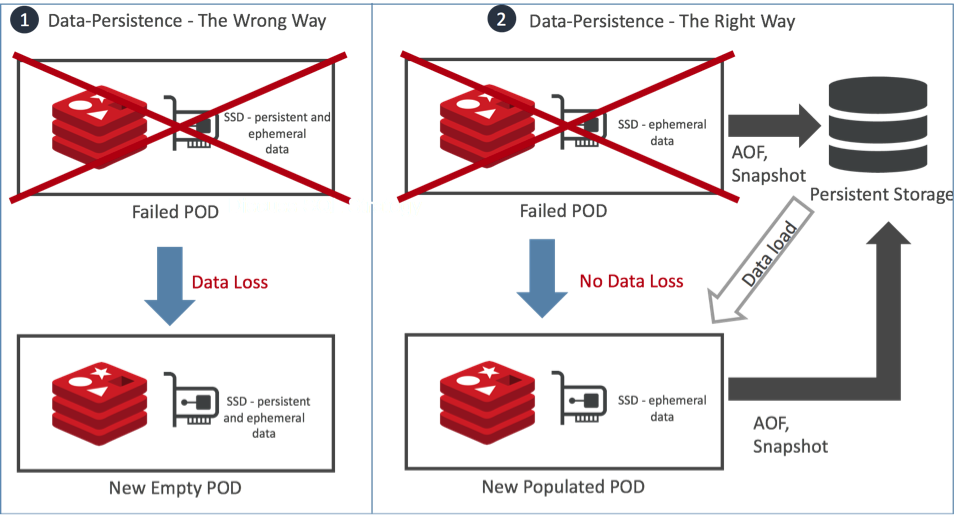
On the left side of the figure (marked #1), Redis uses local ephemeral storage for durability. When the POD fails, Kubernetes launches another POD as a replacement, but this POD comes with empty local ephemeral storage, and your data is just lost.
On the right side of the figure (marked #2), Redis uses network-attached storage for data durability. In this case, when a POD fails, Kubernetes launches another POD and automatically connects it to the storage device used by the failed POD. Redis Enterprise then instructs the Redis instance running on this node to load the data from the network-attached storage, which guarantees a durable setup.
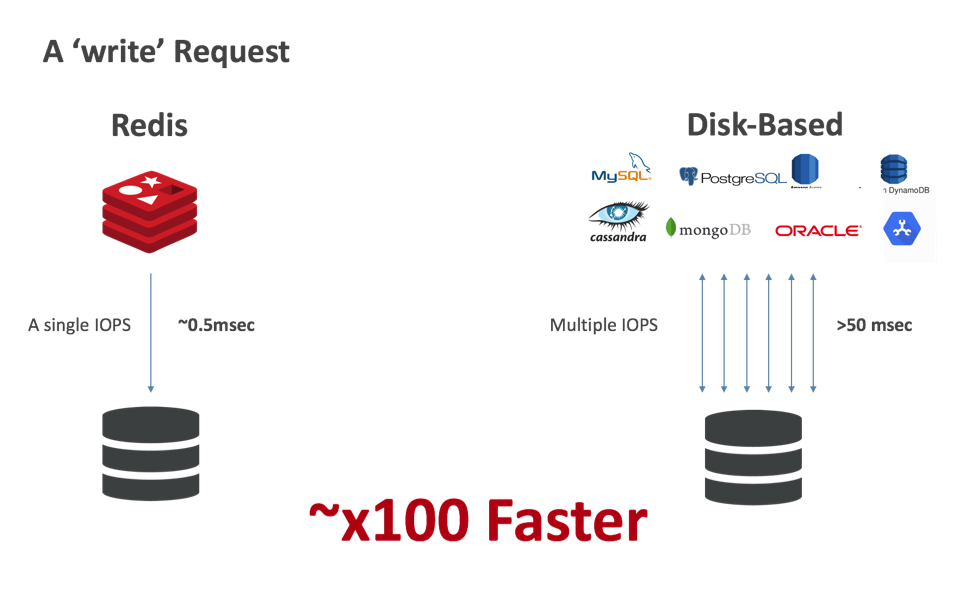
Redis is not only great as an in-memory database, but also extremely efficient in the way it uses persistent storage, even when the user chooses to configure Redis to write every change to the disk. Compared to a disk-based database that requires multiple interactions (in most cases) with a storage device for every read or write operation, Redis uses a single IOPS (in most cases) for a write operation and zero IOPS for a read operation. As such, significant performance improvements are seen in typical Kubernetes environments, as illustrated in the figures below:

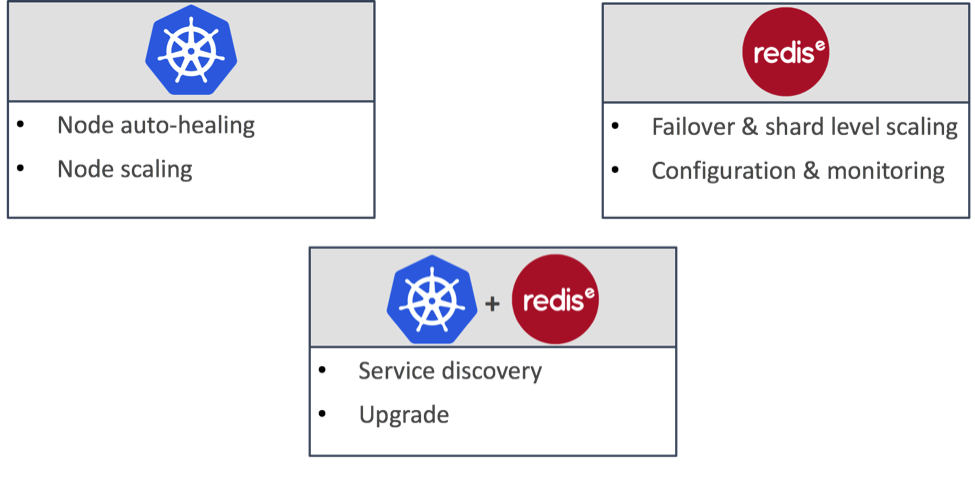
3. A layered orchestrator architecture. Kubernetes is a great orchestration tool but it was not designed to deal with all the nuances associated with operating Redis. Therefore, it can fail to react correctly to internal Redis problems. In addition, Kubernetes orchestration runs outside the Redis cluster deployment, and may fail to trigger a failover event in network split scenarios. To overcome these issues, we created a layered architecture approach that splits responsibilities between the things Kubernetes does well, the things Redis Enterprise cluster is good at and the things both can orchestrate together. This layered architecture is shown in the figure below:
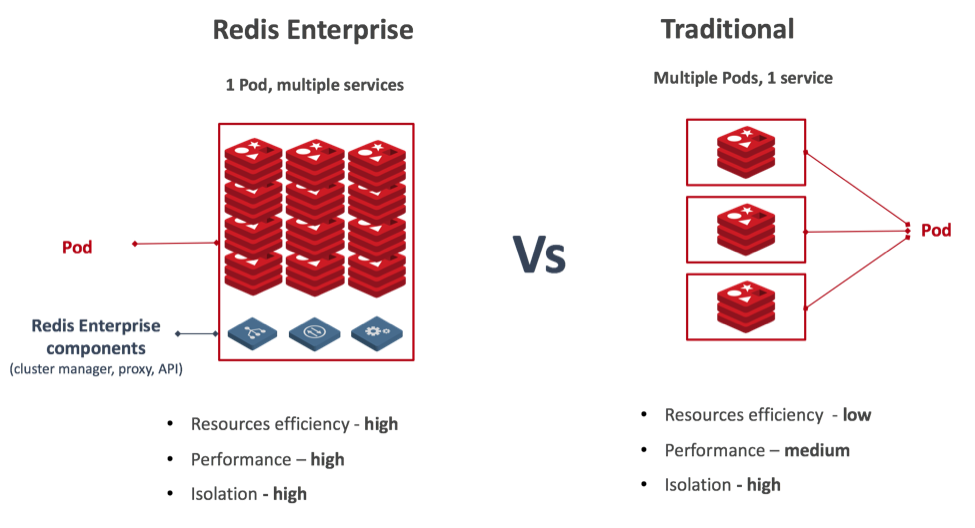
4. Each POD includes multiple Redis instances (multiple services). We found that the traditional method of deploying a Redis database over Kubernetes, in which each POD includes just one Redis instance while preserving a dedicated CPU, is extremely inefficient! Redis is extremely fast and in many cases can use just a fraction of the CPU to deliver requested throughput. Furthermore, when running a Redis cluster with multiple Redis instances across multiple PODs, the Kubernetes network (with its multiple vSwitches) can easily become your bottleneck. Therefore, we took a different approach to manage Redis Enterprise over the Kubernetes environment. This allows us to better utilize the hardware resources used by the POD (CPU, memory and network), while keeping the same level of isolation. Our approach is shown in the figure below:
Q7. How does Redis on Flash take advantage of high-speed storage in the form of Flash SSDs?
Redis on Flash (see more here) extends core Redis by using Flash/SSD memory in addition to DRAM to store your data set while still maintaining Redis’ sub-millisecond latency. This significantly reduces the cost associated with deploying a large data set in DRAM (up to 80%). The beauty of Redis on Flash (RoF) is that it can scale in performance with every new generation of hardware. The figure below compares RoF performance over three Flash/SSD storage media: SATA, NVMe and Intel’s Optane:
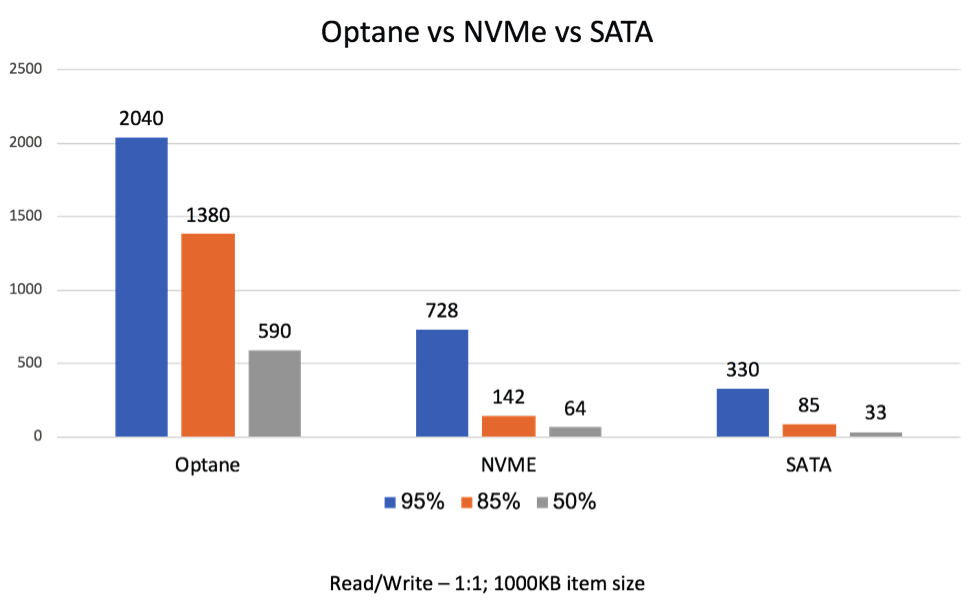
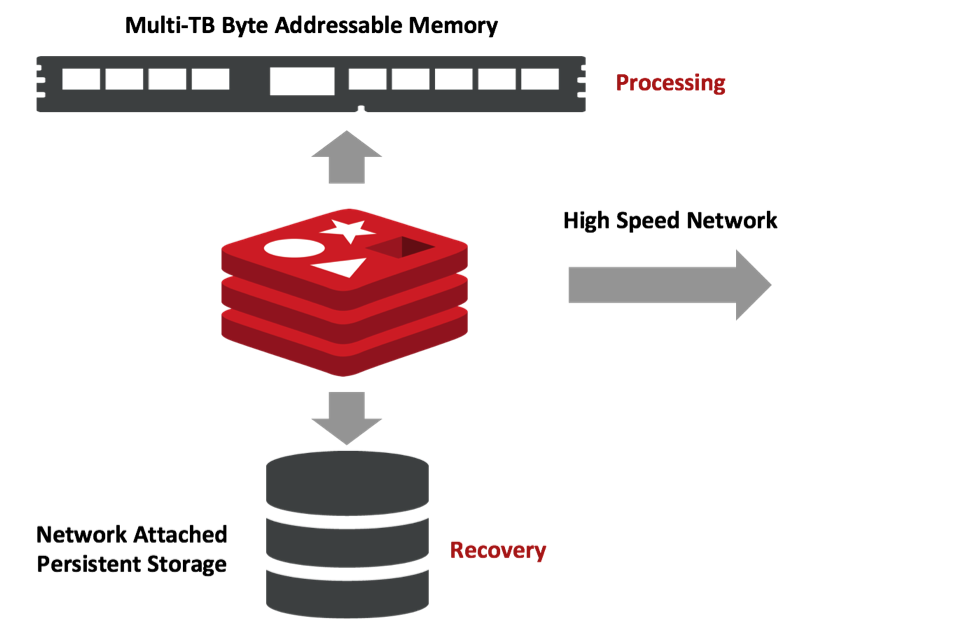
During the last 12 months, we have been working closely with Intel to make Redis on Flash ready for Intel Optane DC Persistent Memory. Through this work, we found that we cannot continue using the same software stack from previous generations of Flash/SSD if we want to fully utilize Intel’s persistent memory capability. So we built a new stack for Redis on Flash and managed to reach very close performance to DRAM performance with persistent memory. Practically, this means that once persistent memory is generally available (not far away), people should start thinking about a completely different architecture for their DBMS. This architecture will be relayed on:
- Persistent memory as a RAM replacement, which allows you to host multi-TB of data on a single server at a much cheaper cost with close to DRAM performance;
- Network-attached storage for data durability (as mentioned in the previous sections, although local storage is persistent, it is not durable in cloud-native environments); and
- High-speed network for high availability and clustering.
We believe Redis and Redis on Flash have all the ingredients to lead this industry shift, as it was built from the ground up to fully utilize this fascinating new generation of hardware architecture.
————————
 Yiftach Shoolman, Founder and CTO of Redis Labs
Yiftach Shoolman, Founder and CTO of Redis Labs
Yiftach is an experienced technologist, having held leadership engineering and product roles in diverse fields from application acceleration, cloud computing and software-as-a-service (SaaS), to broadband networks and metro networks. He was the founder, president and CTO of Crescendo Networks (acquired by F5, NASDAQ:FFIV), the vice president of software development at Native Networks (acquired by Alcatel, NASDAQ: ALU) and part of the founding team at ECI Telecom broadband division, where he served as vice president of software engineering.
Yiftach holds a Bachelor of Science in Mathematics and Computer Science and has completed studies for Master of Science in Computer Science at Tel-Aviv University.