AIOps for Apache Cassandra – Introducing Vector
DATE: June 16, 2020
AUTHOR:

Aaron Morton AIOps DataStax
We created Vector to make it easier for new and existing users of Apache Cassandra™ and DataStax Enterprise (DSE) to be consistently successful. The technology allows DataStax to automate our knowledge base and provide near real-time expert advice, knowledge, and skills to operators and developers. Vector can identify issues before they become problems and turn each interaction into a learning experience, so you can learn what the issue is and how to fix it. Continuous updates to the rules and advice from DataStax and new visualizations make it easier to understand the state of all of your clusters.
Vector is available as a cloud service or on-premise install and makes it easier to be successful with Apache Cassandra and DSE by providing:
1. Automated expert advice
2. Continuous updates
3. Hands-off management
4. Skills development
To see this in action let’s take a look at four of the recommendations Vector can generate. If you want to see it in action, watch the demo. If you are interested in joining the private beta program, contact us through this interest form.
Deliver Hints Before They Expire
This is a great example of expert knowledge that can and should be automated. First a little background to understand the issue…
When a replica node for data is down during a write operation, one of the other nodes will store the write locally to replay when the replica comes back online. This is known as Hinted Handoff, or hints. The length of time hints are collected for after a node goes down is controlled by the max_hint_window_in_ms configuration setting, which defaults to 1080000 or three hours. If a node is down for less than three hours, such as for a restart, all of the writes it missed while down will be replayed to it. If a node is down for longer than the hint window, such as when a disk fails, a manual repair is needed to ensure all the missed updates are present. Regardless of running repair or not, when the QUORUM consistency level is used for reads and writes, the correct value is always returned. Hints and repair make sure that if we lose all data on one node we will continue to have consistency.
When hints are stored they have a time to live (TTL), after which they will not be delivered to the replica when it comes back up. This has to do with the way data is purged from disk by compaction after it is deleted. Because of this, the time to live is set to the gc_grace_seconds value for the table being written to, which controls the minimum time tombstones (deleted data) stay on disk. The default value for gc_grace_seconds is 86400, or 10 days, meaning hints normally have a time to live much longer than the three hours a node can be down before requiring a repair.
So what can go wrong?
If the time to live for hints is less than the window we collect hints for, the recommendation that repair is only needed if the node is down for longer than the hint window is no longer correct. More precisely, if a node is down for longer than the lowest gc_grace_seconds of any table written to while it was down, repair must be run. We can break this down with a small example, where the max_hint_window_in_ms is 3 hours and the gc_grace_seconds (and so the hint time to live) is 1 hour:
- At 1PM node A goes down, all other nodes start collecting hints for it.
- At 3PM node A comes back up, it has been down for 2 hours.
- All other nodes start delivering hints that are no more than 1 hour old.
This results in Node A not receiving the writes from between 1PM and 2PM. Using QUORUMconsistency level means we have consistent results, but we have lost some protection from catastrophic failure until a repair is run.
Note: there is more to think about with hints, see the Hinted Handoff and GC Grace Demystified post from The Last Pickle.
You may want to temporarily, or permanently, reduce the gc_grace_seconds for various reasons. Whatever the reason, Vector will flag it as a potential issue and give you the background knowledge to understand the concerns, as well as customized fixes for you to choose from.
When Vector detects this issue, it is listed as a critical schema issue for the table:
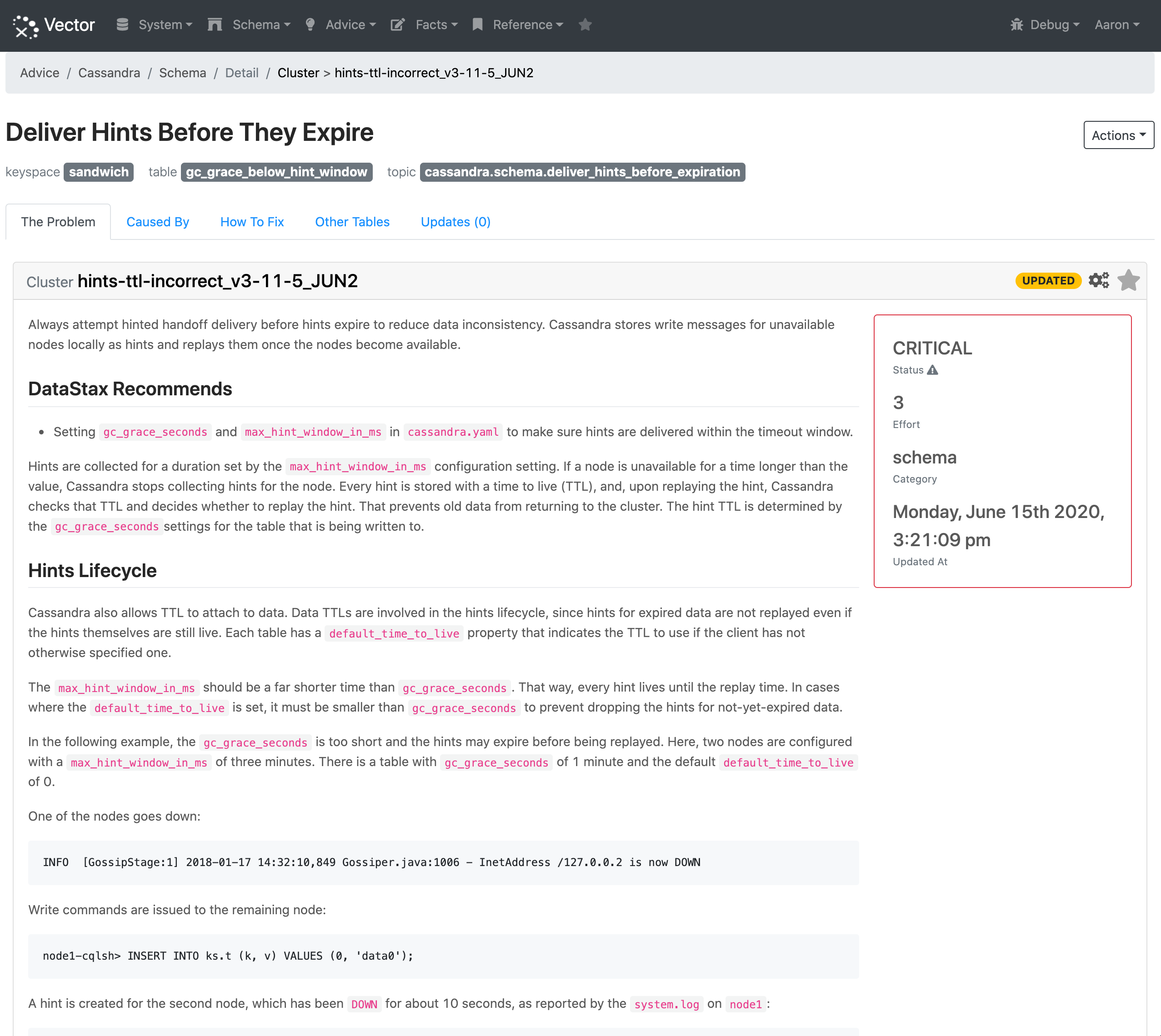
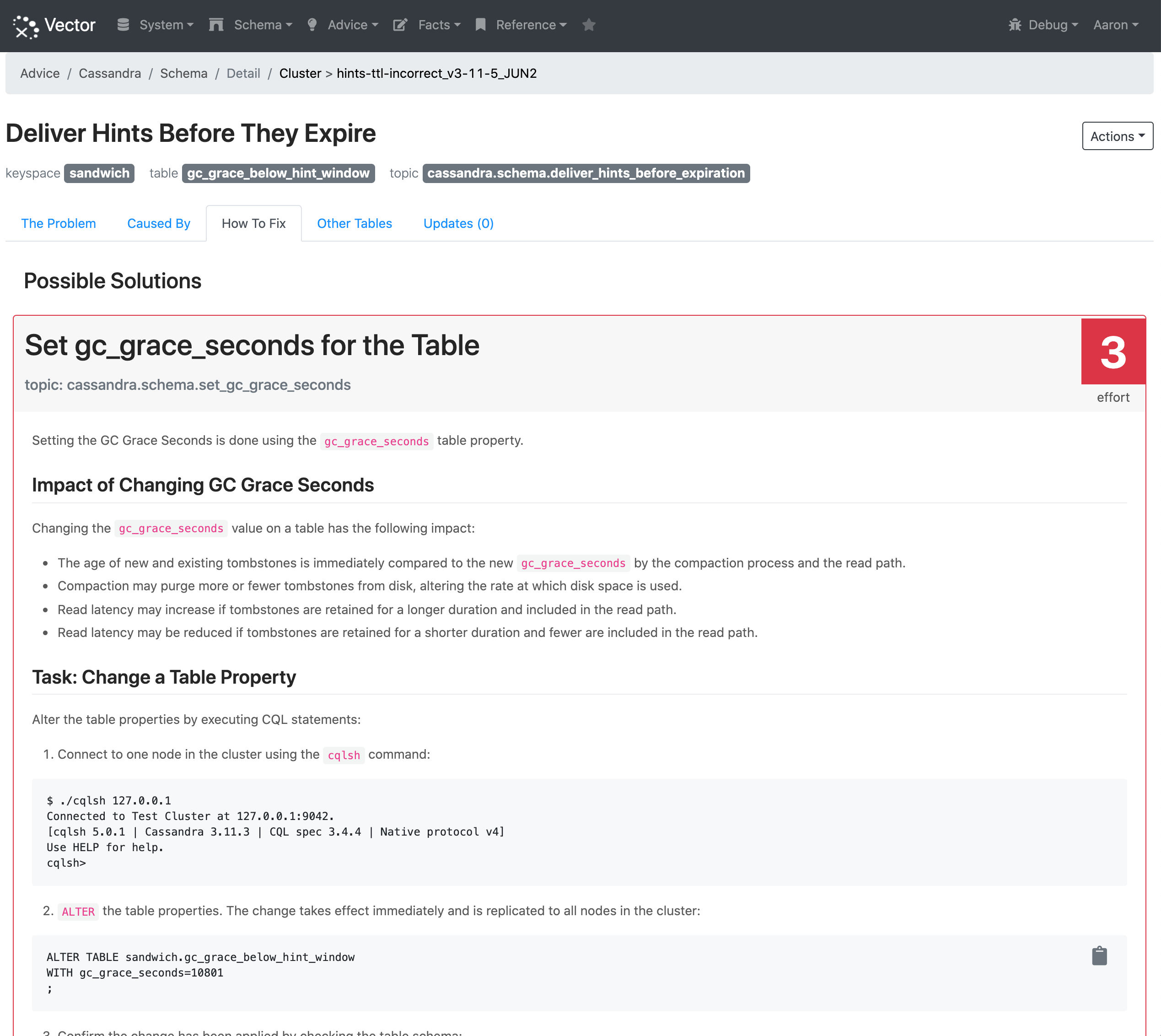
Vector has three possible solutions to fix the issue, but in this scenario it will only recommend two of them (the third is recommended if a default time to live is specified for the table). The first recommendation is to increase the gc_grace_seconds on the table to be above the max_hint_window_in_ms. Like all fixes in Vector there are detailed steps, and as this one includes CQL changes we generate customized CQL statements you can copy and paste to make the change:
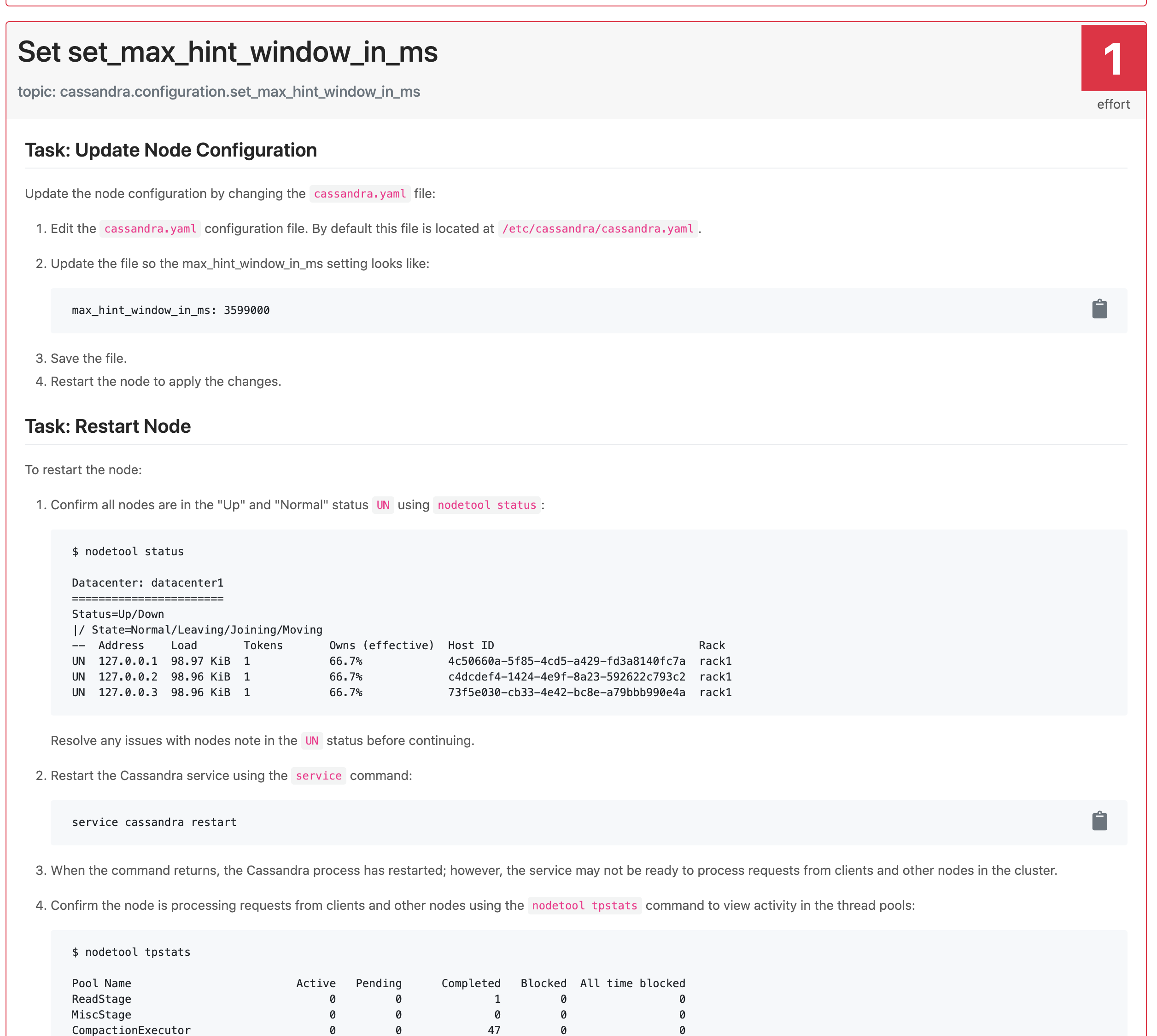
The next possible solution is to reduce the max_hint_window_in_ms:
How Vector Helps
Automatically making this level of expert knowledge about how Cassandra works available at the time you need it is a new and powerful capability. The targeted microlearning and ready to use fixes will make it easier for developers and operators to keep their systems running and performant without help from outside experts.
Disable Asynchronous Read Repair on Tables
Sometimes the way Cassandra works changes from release to release. Features can be added, others deprecated, and sometimes even removed. Asynchronous Read Repair is just such a feature. It actively repairs data that is heavily read by “over reading” from more replicas than required and checking for inconsistencies in the background. Cassandra does this because when it finds an inconsistency during a read it is expensive to fix as the read needs to be run a second time. Asynchronous Read Repair was added very early in Cassandra’s history and at the time seemed like a good idea, but over time it detected fewer inconsistencies as Cassandra improved while the cost of checking stayed the same.
The default setting for read_repair_chance on a new table is 0.1, meaning Asynchronous Read Repair is enabled for 10% of reads. When enabled all replicas are read from rather than those needed to achieve the required Consistency Level, while the read request will only wait for the Consistency Level number of replicas. So when using a Replication Factor of 3, 10% of the reads go to 3 nodes and 90% go to 2 (for QUORUM). Meaning when enabled 10% of the reads in a cluster use 50% more disk IO. It also creates more work for the coordinator as in the background it waits for all results to come in and compares them. The waiting and possible repair can increase Java memory pressure and use more CPU time. After improvements to Hinted Handoff in version 3.x it became less and less needed, eventually being removed in ticket CASSANDRA-13910.
So we advise people to disable asynchronous read repair on clusters running version 3.x and above or when few consistencies are detected. There are two table properties to change, read_repair_chance, which applies to the whole cluster, and dclocalread_repair_chancewhich applies to the datacenter the read coordinator is in. It’s a change that reduces disk IO, memory usage, and CPU utilization across the whole cluster that can be made because of improvements in Cassandra.
How Vector Helps
Vector allows DataStax to continually update the advice we provide. We can automate new knowledge with heuristics and algorithms, combine it with detailed explanations and fixes, and apply it against every node monitored by Vector. This happens automatically when you are running in the cloud, or you can securely pull the new content when running Vector on-premises.
Reduce SSTable Seeks Per Read
I’m sure many developers and operators have been asked to help diagnose problems with a cluster they know nothing about. Quickly understanding which tables are important and their workload helps you identify where to start looking for issues. It’s a task we have done many times at DataStax as well, and a task we wanted Vector to help with. To make this easier we added advanced visualisations including a feature we call Focus Bubbles.
Focus Bubbles allow you to focus on an aspect of table performance, while contextualizing the workload in the keyspace. There is a lot to unpack there, so let’s look at an example:
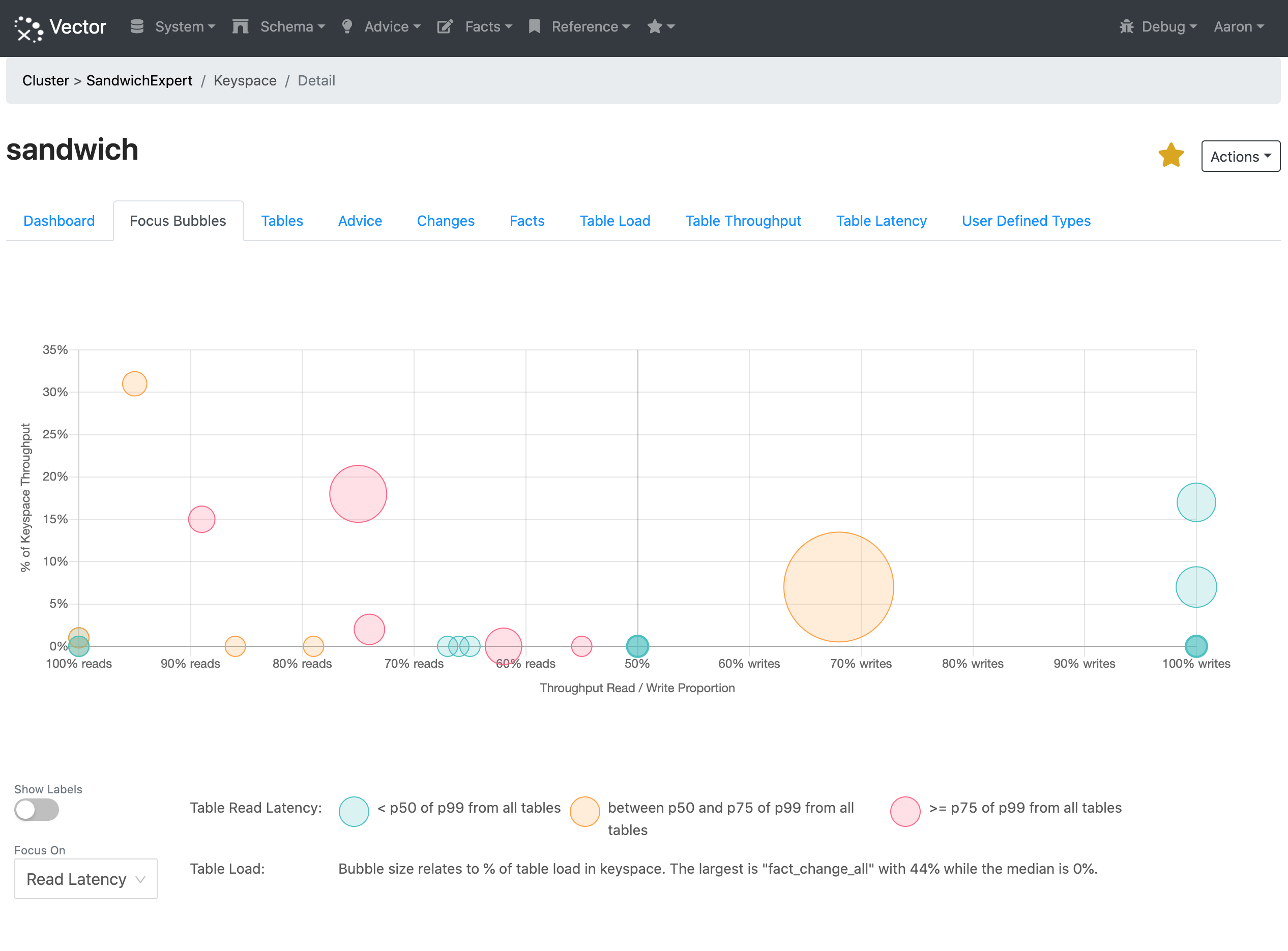
In the Focus Bubble chart, each bubble is a table and shows the:
- Proportion of cluster requests that go to the table as the height of the bubble.
- Read-Write workload mix of the table as left to right position of the bubble.
- Proportion of keyspace data in the table as the size of the bubble.
- Relative performance of the table using colour coding.
In our example above we are focusing on the read request latency. Bubbles colored red are in the top 25th percentile for read latency; they may not be slow to read from, but they are the slowest tables to read from in this keyspace. Orange bubbles are in the 50th to 75th percentile, while those in the bottom 50th percentile are colored green.
So we can quickly see for the table in the top left of the chart:
- It has over 30% of the traffic in the keyspace
- More than 90% of the traffic is reading data
- There are several other tables with more data
- The read latency is in the 50th to 75th percentile for the keyspace
This table gets a lot of traffic, but there are other tables that are slower to read from.
Looking at the table with the next highest throughput:
- It has over 15% of the traffic in the keyspace
- More than 70% of the traffic is reading data
- It has a large amount of the data compared to most other tables
- The read latency is in the top 25th percentile
This table seems like a good place to start looking. We can click on the bubble to look at the schema and see the advice Vector has created.
There are critical performance issues to address:
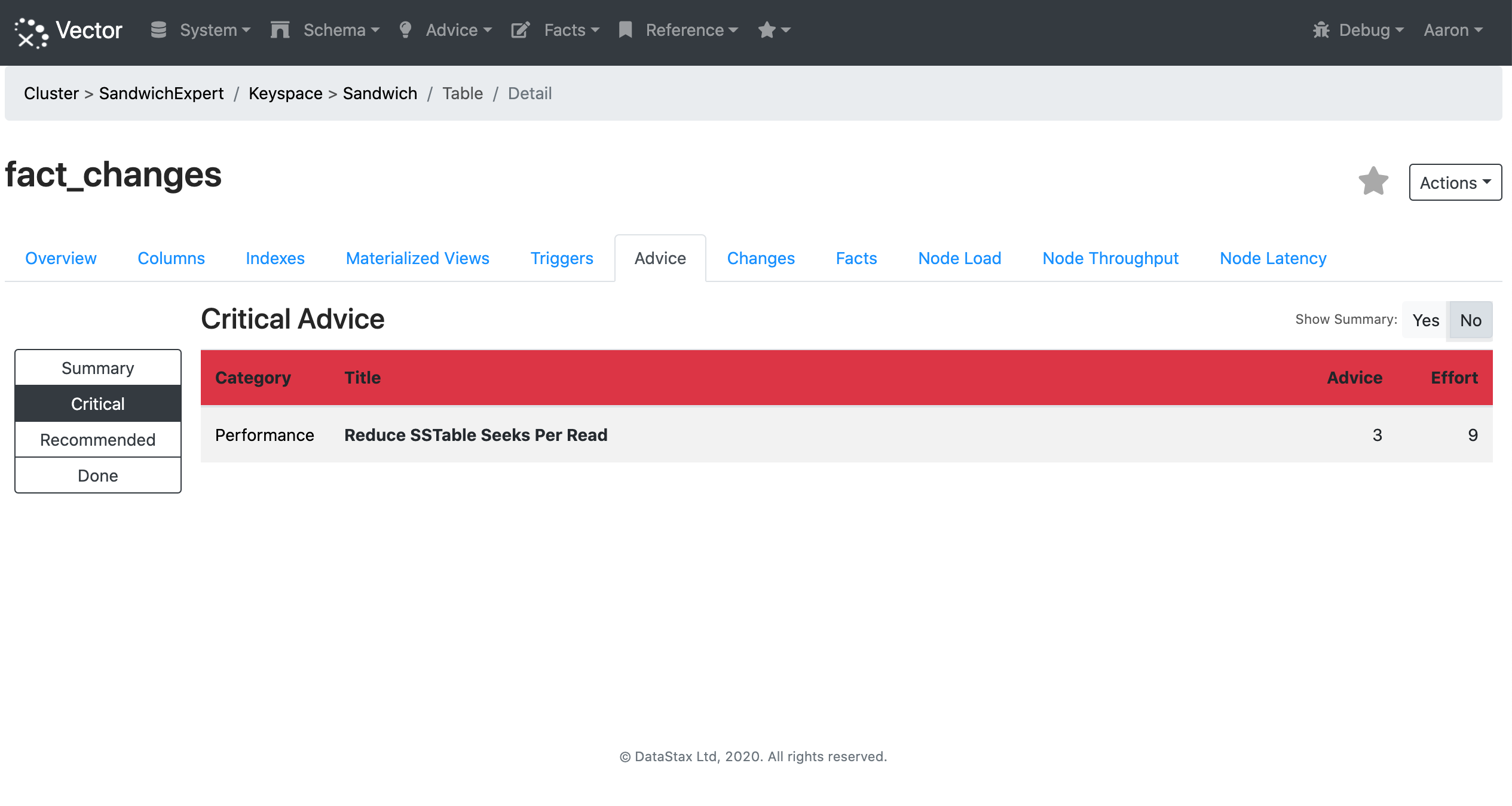
Looking at the advice to “Reduce SSTable Seeks Per Read” Vector shows the information used to make the decision:
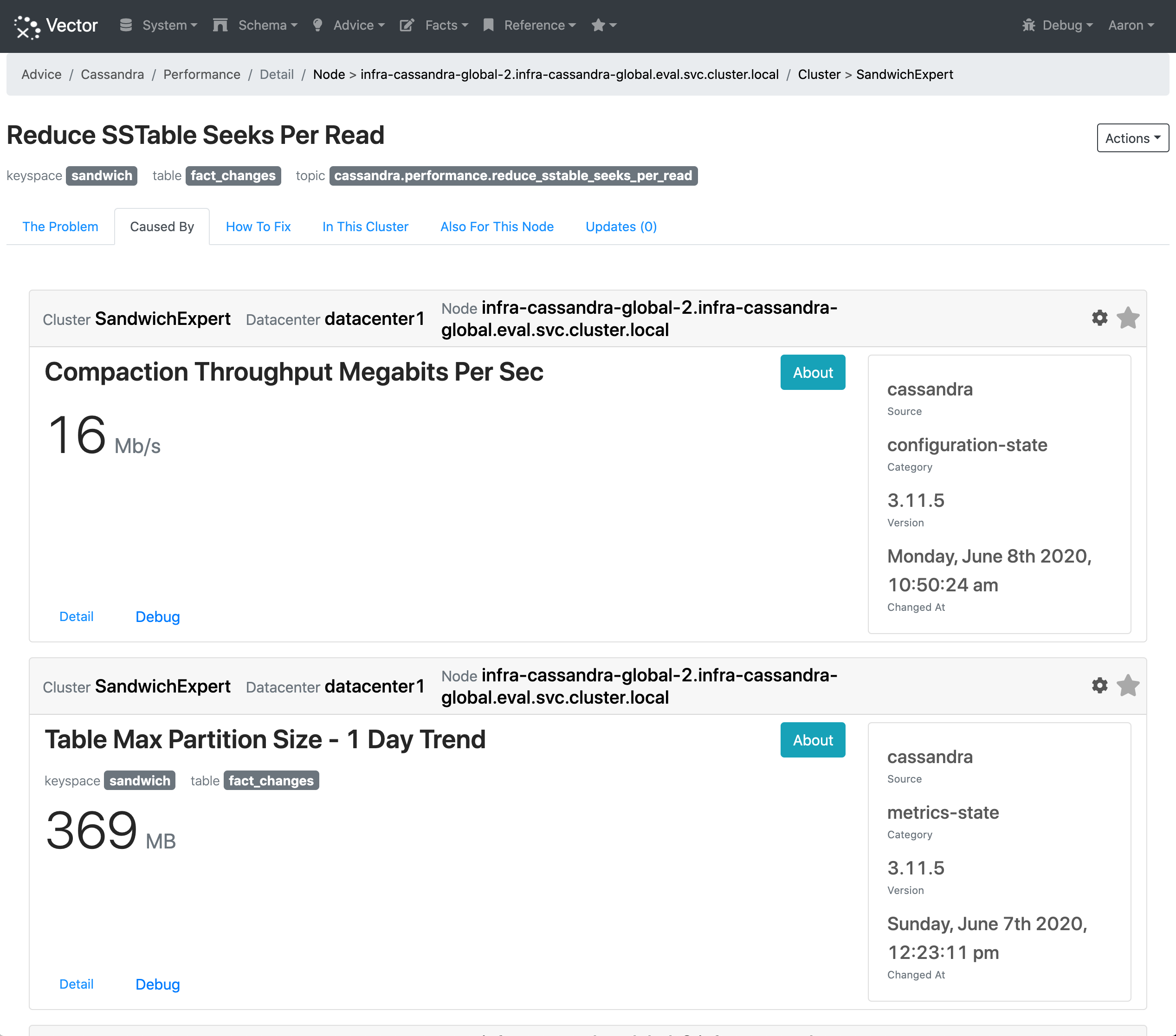
For brevity the image does not include all the information, though it includes:
- Compaction Throughput configuration setting.
- One day trend of the maximum partition size.
- One day trend of the SSTables per read histogram.
- Table schema.
- Dynamic table properties.
How Vector Helps
All of this information can be viewed in the UI, including their history of changes. Vector highlights significant changes in your cluster and provides hands off access to a lot of information from each node, including:
- Schema
- Cassandra configuration
- Operating system configuration
- Java configuration
- Metrics
Focus bubbles, access to configuration, schema, and metrics, as well as new visualisations of throughput, load, and latency all make it easier to manage your clusters.
Limit Use of Collection Types
All databases have best practices and anti-patterns, including Cassandra. It takes time to build the knowledge and skills needed to be successful. And sometimes bad choices do not become issues until much later, when they can quickly jump from an issue to a problem that needs fire fighting. Data modelling is often the source of such problems.
Collections in Cassandra (lists, sets, and maps) are a useful tool to denormalize small amounts of data. They are great for use cases such as storing the email addresses associated with a user, where a table is really not needed. Storing a large amount of data in a collection can dramatically reduce read performance, increase Java memory pressure, and make nodes unstable. If a user of your application controls how much data will be put in the collection, it’s probably best to use a table.
There are also considerations with using a Time To Live (TTL) for the data in Collections. When the data expires the row the data lives on will not be purged from disk, which can result in additional tombstones from the expired data appearing in the read path.
Your use case may be a perfect match for Collection Types, or you may not be aware of the limitations that can cause problems later. Checking a schema and making sure developers understand what they have created often falls to the experts in each team or organization. They review a schema using their years of experience and deep Cassandra knowledge to look for problems that can arise now or in the future. The price of not reviewing the schema can be a later session of fire fighting.
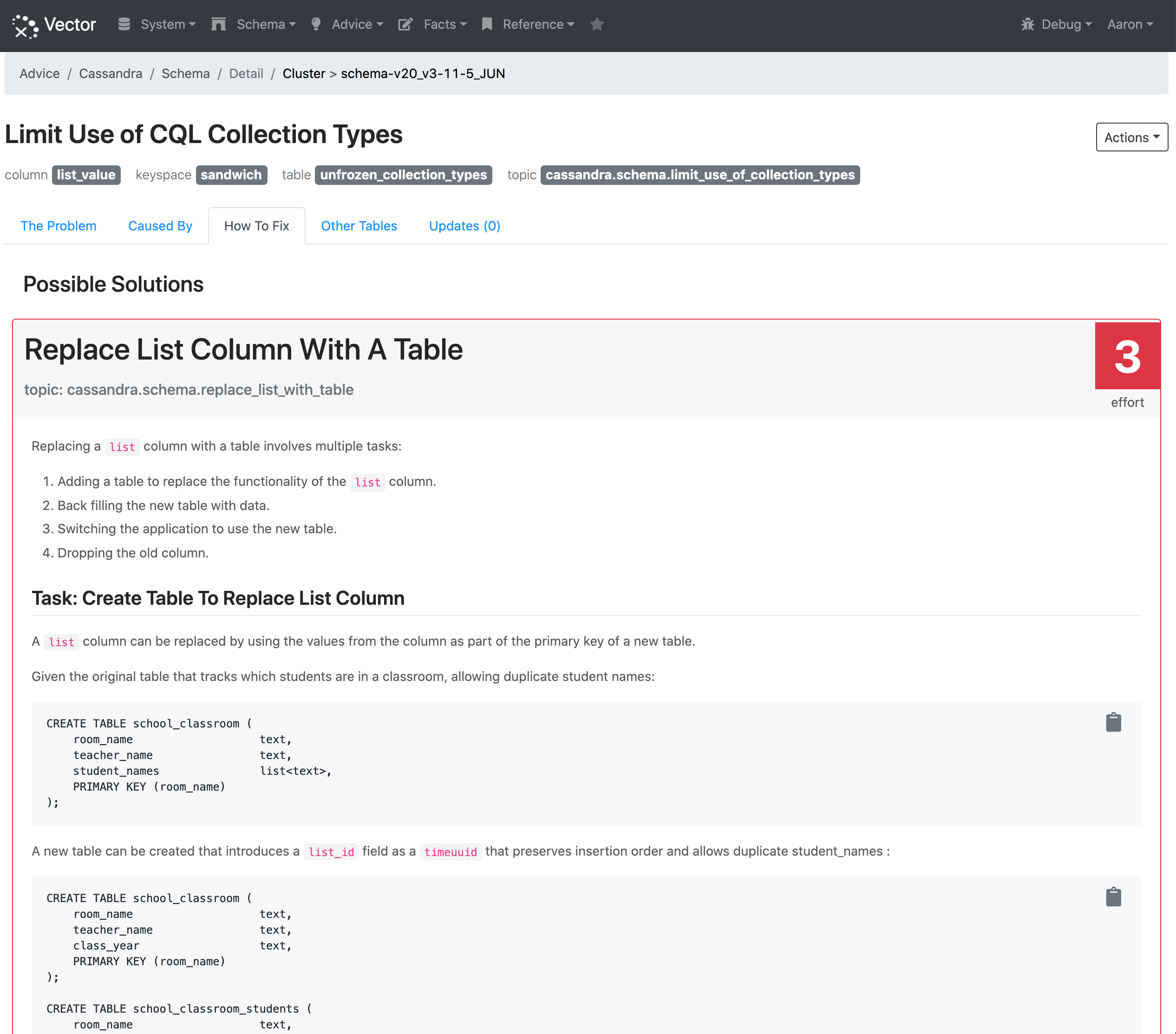
Vector highlights the design considerations with using collection types and provides an example of how to change the data model:
How Vector Helps
This type of knowledge sharing normally involves helping people understand the best use of a feature they have selected. Doing it in near real time helps avoid a problem today, and gives them the skills to be more successful in the future. Automating it with Vector enables developers and operators to strengthen their Cassandra skills. Increasing the skill level across all of your teams reduces fire-fighting, allowing new users and experts to spend more time innovating.
Now In Beta
We are happy to announce Vector is available for beta testing by invitation. To see Vector in action, watch the demo and sign up for the latest updates of the private beta program through this interest form.
Sponsored by Datastax