On the 4 properties for the data layer of AI applications. Q&A with Andreas Kollegger
Q1. Emil Eifrem identifies ‘extracting structure from unstructured data‘ as a critical property for AI data layers. How does Neo4j’s approach to LLM-driven entity extraction and relationship discovery differ from traditional NLP pipelines? Can you walk through the technical process of how your agentic knowledge graph construction transforms unstructured text into meaningful graph structures while maintaining semantic fidelity and handling entity disambiguation at scale?
Entity extraction and relationship discovery are areas where the best approach remains one that depends on the source data and application domain. Neo4j is exploring how to make this process more accessible by using agentic systems that act as copilots, guiding users from problem statement to a knowledge graph capable of answering questions. With this, prompts can adapt to user goals, and critic agents equipped with verification tools can adjust to the level of strictness in data extraction.
Neo4j’s agentic knowledge graph construction is a reference implementation of this concept. It uses a multi-agent system that mirrors a skilled data engineer’s workflow. Each agent follows a propose/approve workflow, allowing users to provide feedback before moving forward.
The system handles structured and unstructured data, as well as GraphRAG for information retrieval. Structured data flows from user intent → file suggestion → schema proposal, while unstructured data focuses on extracting well-known and discovered entities and their relationships.
The plans for both are proposals that the user can review and modify before approving, rather than being the final graph. This declarative approach enables flexibility while preserving key features, including “converging to code”, “human in the loop”, and “inferred schema.”
Q2. Regarding Emil’s third property about combining memory and application data—in your GraphRAG implementations, how do you technically architect the interaction between Neo4j’s persistent graph storage and LLM working memory? What specific indexing strategies, caching mechanisms, and query optimization techniques ensure that contextual retrieval from both historical knowledge graphs and ephemeral conversation state remains performant during complex reasoning tasks?
In his keynote, Emil Eifrem highlighted that Neo4j supports two key properties: firstly, handling structured, unstructured, and semi-structured data, and secondly, extracting structure from unstructured data. Emil added that a third property is realized through different areas of the graph, though it is currently managed by convention rather than a formal mechanism.
Q3. Emil’s fourth property emphasizes distinguishing between first-party and derived data. In your agentic workflows, how do you implement technical mechanisms to track data provenance and confidence scores as LLMs generate derived insights from source documents? What graph schema patterns and metadata structures do you use to maintain this lineage, especially when agents iteratively refine or contradictory information emerges across multiple extraction passes?
Similar to property 3, Emil Eifrem noted that a fourth property remains an area of active research. For now, the best practice involves adding extra labels to nodes to indicate they have been derived. For example, a ‘Person’ node may also carry an ‘__Entity__’ label to show it was extracted from unstructured data. These nodes typically connect to unstructured data chunks through a ‘MENTIONS’ relationship, with the chunks themselves linked back to their original source document. The focus at this stage is on ensuring information fidelity and accurately capturing a compressed knowledge graph representation of key information from unstructured data.
Q4. Your recent work focuses on combating GenAI hallucinations using graph databases. From a technical perspective, how do you implement graph-based validation constraints and consistency checks that can identify when LLM outputs contradict established relationships in the knowledge graph? What specific Cypher query patterns or graph algorithms do you employ to score and filter LLM-generated content before it gets integrated into production knowledge graphs?
Reducing hallucinations begins with effective context engineering – providing the smallest, most relevant context rather than the largest one, even if it is available in the LLM. Prevention is easier than catching and mitigating mistakes. As such, knowledge graphs play a key role by using their structure to rank and filter the most relevant information for a given question. They also support validation by providing targeted context to an ‘LLM-as-judge’, helping to verify responses before they reach the user.
Q5. Addressing Emil’s first property about handling structured, semi-structured, and unstructured data—how does your technical architecture handle the integration of vector embeddings, traditional graph relationships, and document chunks within a single Neo4j instance? Can you detail the indexing strategies, similarity search algorithms, and query execution plans that enable seamless traversal between graph relationships and vector similarity searches in your GraphRAG implementations?
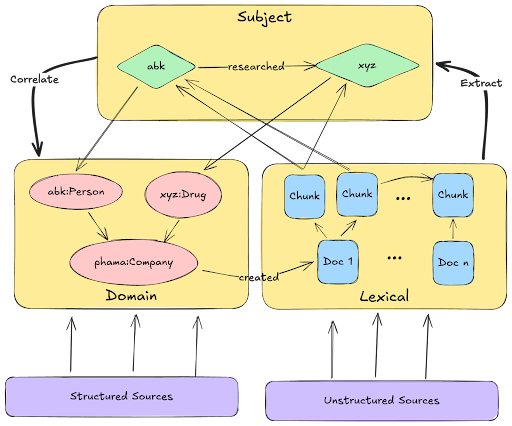
To answer this question effectively, I’ve attached a diagram showcasing the high-level information architecture.
To expand on this, a knowledge graph that spans structured, unstructured, and semi-structured data is built on three foundational graphs:
- Domain graph: This is where structured and semi-structured data are imported. The distinction lies in how the data sources are transformed and mapped as well as in the flexibility of the target schema. While structured data adheres to a strict schema, semi-structured data offers greater flexibility.
- Lexical graph: This graph contains chunked text along with vector embeddings. In some cases, the document structure from the original source is also recreated, with optional summarizations at each level paired with embeddings to enhance retrieval.
- Subject graph: Extracted entities and relationships populate the subject graph. While entities can be merged across the subject and domain graphs, maintaining separation clarifies that the subject graph contains derived data.
In some implementations, a fourth graph is added as a semantic layer to describe what exists within the graph, i.e., how it was created, and how it should be used.
……………………………………………………..

Andreas (ABK) Kollegger
Andreas Kollegger is a Senior Developer Advocate at Neo4j, where he leads the company’s innovations in Generative Artificial Intelligence (GenAI). A cornerstone of the Neo4j team for over a decade, Andreas has contributed across a range of roles, from developer advocacy to driving product innovation. He is widely recognized for his deep expertise in graph database technology and his dedication to empowering developers to harness the power of connected data.
Andreas’s career is marked by unique experiences. He began his professional journey at NASA, designing systems from the ground up to support science missions. Driven by a desire to use technology for good, he later worked in Zambia, where he developed medical informatics systems to improve healthcare in underserved communities.
A sought-after speaker and thought leader, he is celebrated for his engaging presentations and his ability to make complex concepts accessible to audiences of all technical backgrounds.
Andreas holds a unique combination of Bachelor’s degrees in Computer Science and Music from Goucher College in Maryland.
He is based in Cambridge, England.