

On the Industrial Internet of Things. Interview with Leon Guzenda
“With IBM having contributed huge amounts of code and other resources to Spark we are likely to see an explosion in the number of new machine learning components.”–Leon Guzenda
I have interviewed Leon Guzenda, co- founder of Objectivity, Inc. We covered in the interview: the Industrial Internet of Things, Sensor Fusion systems and ThingSpan.
RVZ
Q1. What is the Industrial Internet of Things (IIoT) ? How is it different from the Internet of Things (IoT) ?
Leon Guzenda: The IIoT generally refers to the application of IoT technologies to manufacturing or process control problems. As such it is a subset of IoT with specialized extensions for the problems that it has to tackle.
Q2. What is a sensor fusion system?
Leon Guzenda: A sensor fusion system takes data streamed from multiple sensors and combines it, and possibly other data, to form a composite view of a situation or system. An example would be combining data from different kinds of reconnaissance sources, such as images, signals intelligence and infrared sensors, taken from different viewpoints to produce a 3D visualization for tracking or targeting purposes.
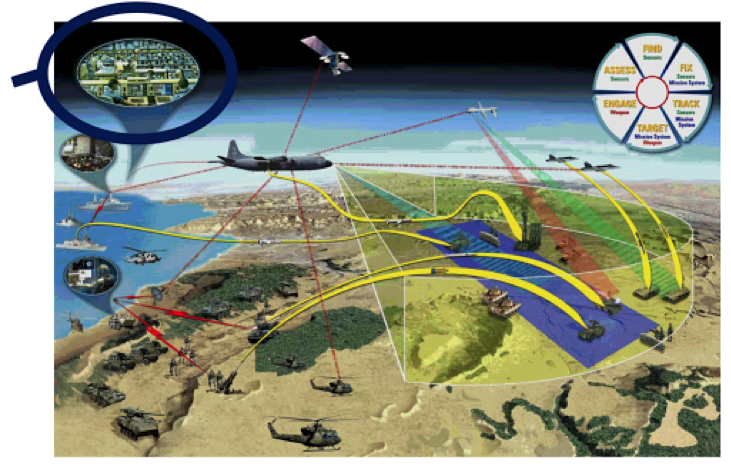
Q3. What are the key requirements for a database software platform for real-time data and sensor fusion systems?
Leon Guzenda: Some sensor fusion systems combine one or a few types of data from multiples sources, such as the detectors in a linear accelerator, or measurements from medical instruments, though there may be many variants of a single kind of data. However, most have to handle a wide variety of data types, ranging from video to documents and streams of financial or other information. The data may be highly interconencted by many types of relationship, forming tree or graph structures. The DBMS must make it easy to track the provenance and quality of data as algorithms are applied to the raw data to make it suitable for downstream processes and queries. The DBMS must have low latency, i.e. the time from receiving data to it being available to multiple users. It has to be able to cope with fast moving streams of data in addition to small transactions and batched inputs. Above all, it must be able to scale and work in distributed environments.
Q4. What are the main technical challenges in capturing and analysing information from many different sources in near real-time for new insights in order to make critical decisions?
Leon Guzenda: The DBMS must have the ability to support compute intensive algorithms, which generally precludes the use of tabular schemas. There is a trend to suing modular, open source components, such as Spark Machine Learning Library (MLlib), so support for Spark Dataframes is important in some applications. It must have a flexible schema so that it can adapt rapidly to deal with new or changed data sources. Maintaining consistent, low latency is challenging when fast moving streams of incoming data have to be merged with and correlated with huge volumes of existing data.
Q5. Why does ‘after the fact analysis’ not work with real-time and data sensor fusion systems?
Leon Guzenda: Processes managed with the help of sensors and fusion systems may fail or get out of control if action isn’t taken immediately when changes occur. In other cases, opportunities may be lost if resources can’t be brought to bear on a problem, be it a cybersecurity or physical threat.
Q6. What is the impact of open source technologies, such as Spark, Kafka, HDFS, YARN, for the Industrial Internet of Things?
Leon Guzenda: Apache Spark provides a scalable, standard and flexible platform for bringing multiple components together to build standard or ad hoc workflows, e.g. with YARN. Kafka and Samza make it easier to split streams of data into pipelines for parallel ingest and query handling. HDFS is good for reliably storing files, but it is far from ideal for handling randomly accessed data as it moves data in 64 MB blocks, increasing latency. Nevertheless, ThingSpan can run on HDFS with data cached by Spark, but we prefer to run it on industry standard POSIX filesystems for most purposes.
With IBM having contributed huge amounts of code and other resources to Spark we are likely to see an explosion in the number of new machine learning components. By combining this with ThingSpan’s graph analytics capabilities, we’ll be able to attack new kinds of problem.
Q7. Why ThingSpan’s offer DO as a query language and not an extension of SQL?
Leon Guzenda: We would like to contribute the graph processing ideas in DO to the SQL community and are seeking partners to try to make that happen. However, our customers need a solution now, so we considered open source options, such as Cypher and SparQL. However, we decided that it would be faster and more controllable to leverage the flexible schema and query handling components within the ThingSpan kernel to give our products a competitive edge, particularly at scale.
Q8. What are the similarities and differences between ThingSpan and Neo4j? They both handle complex graphs.
Leon Guzenda: Both handle Vertex and Edge objects. Neo4j depends on properties whereas ThingSpan can also operate with connections that have no data within them. The ThingSpan declarative query language, DO, incorporates most of the graph querying capabilities of Cypher and extends them with advanced parallel pathfinding capabilities.
However, the main differentiator is performance as a graph scales. Although Neo4j has been introducing some distributed operations and has a port for Spark, it is inherently not a distributed DBMS with a single logical view of all of the data within a repository. Although it is capable of handling graphs with millions of nodes it hasn’t shown the ability to handle very large graphs. Objectivity has customers processing tens of trillions of nodes and connections per day for thousands of analysts.
Q9. ThingSpan and Objectivity/DB: how do they relate with each other (if any)?
Leon Guzenda: ThingSpan uses Objectivity/DB as its data repository. Besides the Java, C++, C# and Python APIs It also has a REST API and adaptors for Spark Dataframes and HDFS. Objectivity/DB is a component of the ThingSpan suite and can be purchased on its own for embedded applications or to run in non-Spark environments.
Q10. What kinds of things are on the roadmap for ThingSpan?
Leon Guzenda: We recently announced the availability of ThingSpan on the Amazon AWS Market Place, making it easier to evaluate and deploy ThingSpan in a resilient, elastic cloud environment.
The next release, which is in QA at the moment, will add high speed pipelining for ingesting streamed data. It also has extensions to DO, particularly in regard to pathfinding and schema manipulation. There is also a new graph visualization tool for developers.
——————————–

Leon Guzenda, Chief Technology Marketing Officer, was one of the founding members of Objectivity in 1988 and one of the original architects of Objectivity/DB.
He worked with Objectivity’s major partners and customers to help them deploy the industry’s highest-performing, most reliable DBMS technology. Leon has over 40 years experience in the software industry. At Automation Technology Products, he managed the development of the ODBMS for the Cimplex solid modeling and numerical control system. Before that he was Principal Project Director for the Dataskil division of International Computers Ltd. in the United Kingdom, delivering major projects for NATO and leading multinationals. He was also design and development manager for ICL’s 2900 IDMS product at ICL Bracknell. He spent the first 7 years of his career working in defense and government systems.
Resources
– Internet of Things From Hype to Reality
– Objectivity Powers the Most Demanding Real-Time Data and Sensor Fusion Systems on the Planet
– Objectivity Enables Complex Configuration Management for Rockwell Collins’ Avionics Product Lines
Related Posts
– McObject’s eXtremeDB® v8.0 adds a suite of new features for the Internet of Things
– Kx Systems Joins the Industrial Internet Consortium
– Sensor Data Storage for Industrial IoT
– KX FUELING IOT REVOLUTION WITH MANUFACTURING WIN
Follow us on Twitter: @odbmsorg
##