

On using AI and Data Analytics in Pharmaceutical Research. Interview with Bryn Roberts
” I’m intrigued by the general trend towards empowering individuals to share their data in a secure and controlled environment. Democratisation of data in this way has to be the future. Imagine what we will be able to do in decades to come, when individuals have access to their complete healthcare records in electronic form, paired with high quality data from genomics, epigenetics, microbiome, imaging, activity and lifestyle profiles, etc., supported by a platform that enables individuals to share all or parts of their data with partners of their choice, for purposes they care about, in return for services they value – very exciting! “ —Bryn Roberts
I have interviewed Bryn Roberts, Global Head of Operations for Roche Pharmaceutical Research & Early Development, and Site Head in Basel. We talked about using AI and Data Analytics in Pharmaceutical Research.
RVZ
Q1. What are your responsibilities as Global Head of Operations for Roche Pharmaceutical Research & Early Development, and Site Head in Basel?
Bryn Roberts: I have a broad range of responsibilities that center around creating and operating a highly innovative global R&D enterprise, Roche pRED, where excellent scientific decision making is optimised along with efficiency, effectiveness, sustainability and compliance. Informatics is my largest department and includes workflow platforms in discovery and early development, architecture, infrastructure and software development, data science and digital solutions.
Facilities, infrastructure and end-to-end lab services, including three new R&D center building projects, provide state-of-the-art innovation centers and labs that integrate the latest architectural concepts, instrumentation, automation, robotics and supply chain to facilitate cutting-edge science.
These more tangible assets are complemented by a number of business operations teams, who oversee quality, compliance, risk management and business continuity, information and knowledge management, research contracts, academic and industrial collaborations, change and transformation, procurement, safety-health-environment, etc.
Finally, leadership of our Personalised Healthcare and Medical Genomics strategies and initiatives, ensuring close collaboration and insight sharing across the Roche Group.
As the Site Head for the Roche Innovation Center in Basel, I am, together with my local leadership team, accountable for the engagement and well-being of more than a thousand Research and Early Development colleagues at our headquarter site.
Our task is to create a vibrant environment that attracts, motivates and equips world-class talent. Initiatives range from scientific meetings, wellbeing programmes, workplace improvements, communication and knowledge sharing, celebrations and social events, to engagement of local academic and governmental organizations, sponsorship of local scientific conferences, and contribution to the overall Roche site development in Basel and Kaiseraugst.
Q2. Understanding a disease now requires integrated data and advanced analytics. What are the most common problems you encounter when integrating data from different sources and how you solve them?
Bryn Roberts: The challenges often relate to the topics represented by the FAIR acronym. These are Findability, Accessibility, Interoperability and Reusability. As with all organizations where large data assets have been generated and acquired over a long period of time, across many departments and projects, it is challenging to establish and maintain these FAIR Data principles. We have been committed to FAIR data for many years and continue to increase our investment in ‘FAIRification’, with particular emphasis currently on clinical trial and real-world data. Addressing the challenges requires a well thought through, and robustly implemented, information architecture incorporating data catalogues based on high quality meta-data, a holistic terminology service that enables semantic data integration, curation processes supporting data quality and annotation, appropriate application of data standards, etc.
On the advanced analytics side, it is very helpful to establish mechanisms for sharing algorithms and analysis pipelines, such as code repositories, and for annotating derived data and insights. Applying the FAIR principles to algorithms and analysis pipelines, as well as datasets, is an excellent way of sharing knowledge and leveraging expertise in an organization.
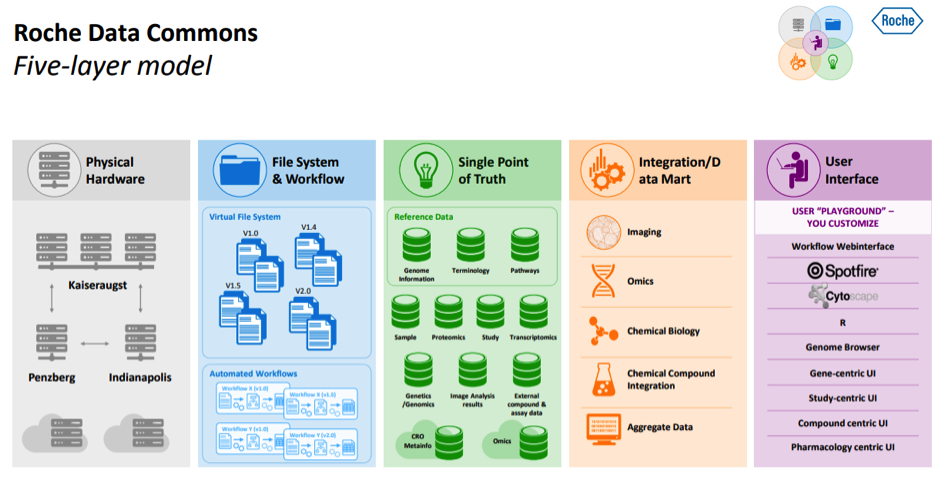
We are currently implementing a ‘Data Commons’ architecture framework to facilitate data management, integration, ‘FAIRification’, and to enable analysts of different types to leverage fully the data, as well as insights and analyses from their colleagues. Frameworks like this are essential in a large R&D enterprise, utilising complex high-dimensional data (e.g. genomics, imaging, digital monitoring), requiring federation of data and/or analyses, robust single-point-of-truth or master data management, access control, etc. In this regard, we are in our second generation architecture for our platform supporting disease understanding. My colleague, Jan Kuentzer, presented an excellent overview at the PRISME Forum last year and the slides are available if people would like to learn more (Roche Data Commons).
Q3. How do you judge the quality of data, before and after you have done data integration?
Bryn Roberts: This question of data quality is even more complicated than it may first appear. Although there are some more elaborate models out there, conceptualising data quality in two broad perspectives may help.
Firstly, what we might call prescriptive quality, where we can test data against pre-determined standards such as vocabularies, ontologies, allowed values or ranges, counts, etc. This is an obvious step in data quality assessment and can be automated to a large degree, including in database schema and constraints. A very challenging aspect of prescriptive quality is judging the upstream processes involved in data collection and pre-processing. For example, determining: if analytical data have been associated with the correct samples, if a manual entry was correctly read and typed, if data from a collaborator have been falsified. The probability of quality issues such as these can be reduced through robust protocols, in-process QA steps, automation, and algorithms to detect systematic anomalies, etc. In the standard data quality models, we might consider prescriptive quality as covering dimensions such as accuracy, integrity, completeness, conformity, consistency and validity.
Secondly, what we might call the interpretive quality perspective, relating to the way the data will be interpreted and used for decision making. For example, the smoking status of patients with lung diseases may be recorded simply as: current, former or never. Despite the data meeting the prescribed standards, being accurate, complete and conforming to the model, they may not be of sufficient quality to address the complexities of the biology underlying the diseases, where one might need information describing the number of cigarettes smoked per day and the time since the individual smoked their last cigarette.
Similarly, when working with derived data from an algorithm, one may need to understand the training set and boundaries of the model to understand how far the derived data can be interpreted for specific input conditions. One can address some of these issues with meta-data describing how data were generated in lab, clinic or silico.
Q4. What are the criteria you use to select the data to be integrated?
Bryn Roberts: Certainly the quality aspects above play a key role. We have, for example, discarded historical laboratory results when, after careful consideration, we decided that the meta-data (lab protocols, association with target information, etc.) were insufficient for anyone to make meaningful use of them. Data derived from old technologies, despite being valuable at some point in the past, may have been superseded or may not meet today’s requirements, so will have lower priority for integration, although may still be archived for specialist reference. Relevance is another critical factor – we prioritise the integration of data relating to our current molecules or disease targets, and data that we deem to have the most valuable content.
Q5. Is there a risk that data integration introduces unwanted noise or bias? If yes, how do you cope with that?
Bryn Roberts: I’m not too concerned about these aspects when the above architectures and principles are applied. There is clearly a risk of bias when the integrated landscape is incomplete, so understanding what you have, and what you don’t, when searching is important. Storing only aggregated or derived data can be risky, as aggregation can mask properties such as skewness and outliers, and there are obviously benefits in having the ability to access and re-analyse upstream and raw data, as models and algorithms improve or an analyst has a specific use-case. Integration, if performed well, should not introduce additional noise, although noise reduction may potentially mask signals in data when they are aggregated or transformed in other ways.
I often hear people talking about Data Lakes and it certainly seems to be one of the hype terms of the last couple of years. This approach to data ‘integration’ does concern me if not implemented thoughtfully, especially for the complex scientific and clinical data used in R&D. Given that the Big Data stack allows for data to be poured into the metaphorical ‘Lake’ with a very low cost of entry, it is tempting to throw everything in, getting caught up with KPIs such as volume captured, with little thought to the backend use-cases and costs incurred when utilising the data. I also wouldn’t advocate the opposite extreme of RDBMS-only data Warehousing, where the front-end costs and timelines escalate to unreasonable levels and the models struggle to incorporate new data types. There is a pragmatic middle-ground, where up-front work on the majority of data has a positive return on investment, but challenging data are not excluded from the integration. This complementary Warehouse+Lake approach allows for continuous refinement, based on ongoing use of the data, to maximize value over the longer-term.
Q6. What specific data analytics techniques are most effective in pharma R&D?
Bryn Roberts: We have so many data types and use-cases, spanning chemistry, biology, clinic, business, etc. that we apply almost every analytic technique you can think of. Classical statistical methods and visual analytics have broad application, as do modelling and simulation. The latter being used extensively in areas from molecular simulations and computational chemistry to genotype-phenotype associations, pharmacokinetics and epidemiology. We are increasingly using Artificial Intelligence (AI), Machine Learning and Deep Learning, in applications such as image analysis, large scale clinico-genomic analysis, phenotypic profiling and analysis of high dimensional time-series data.
Q7. What are your current main projects in the so called “Precision Medicine”?
Bryn Roberts: In Roche we tend to use the term Personalised Healthcare rather than Precision Medicine, since we have both Pharmaceuticals and Diagnostics divisions. However, the intention is similar in that we want to identify which treatments and other interventions will be effective and safe for which patients, based on profiling, which may include genetics, genomics, proteomics, imaging, etc. We have many initiatives ongoing in research, development and for established products. Developing a deeper understanding how mutational and immunological status of tumours influences response to targeted therapeutics, immunotherapies and combinations is one example. Forward and reverse translation in such examples is critical, as we design clinical trials and select participants then, in turn, inform new research initiatives based on data fed back from the clinic. We have made considerable headway in this space thanks to progress in genomic analysis and quantitative digital pathology, supported by collaborations across the Roche Group, including organizations such as Tissue Diagnostics, Foundation Medicine and Flatiron.
Another example is in ophthalmology, where we are trying to identify biomarkers that predict disease progression and drug response to enable appropriate treatment selection, including prophylaxis.
A third quite different example is our application of mobile and sensor technology to monitor symptoms, disease progression and treatment response – the so called “Digital Biomarkers”. We have our most advanced programmes in Multiple Sclerosis (MS) and Parkinson’s Disease (PD), with several more in development. Using these tools, a longitudinal real-world profile is built that, in these complex syndromes, helps us to identify signals and changes in symptoms or general living factors, which may have several potential benefits. In clinical trials we hope to generate more sensitive and objective endpoints with high clinical relevance, with the potential to support smaller and shorter studies, and possibly validate targets in earlier studies that might otherwise be overlooked. In the general healthcare setting, tools like these may have great value for patients, physicians and healthcare systems if they are used to inform tailored treatment regimens and enable supportive interventions such as the timing of home visits or provision of walking aids to reduce falls. For those interested in learning more about our work in MS there is more information available online about our Floodlight Open programme.
Q8. You have been working on trying to detect Parkinson disease. What is your experience of using Deep Learning of that purpose?
Bryn Roberts: The data we collect with the digital biomarker apps fall into two classes: 1) active test data, where the subject performs specific tasks on a daily basis, and 2) continuous passive monitoring data, where the subject carries the device (e.g. smartphone) with them as they go about their daily lives and sensors, such as accelerometers and gyrometers, collect data continuously. These latter data form complex time series, with acceleration and rotation being measured in 3 axes each, many times per second. From these data, we build a picture of the individual’s daily activities and performance, which is ultimately what we hope to improve for patients with our new therapies. We apply Deep Learning to do this activity-performance classification, or Human Activity Recognition (HAR), using deep artificial neural networks that have been trained using well-annotated datasets. Since the data are time-series, the network utilises Long Short-Term Memory (LSTM) layers to provide recurrence, hence the name “Recurrent Neural Network” or RNN. Examples of what we might study here are how well a patient with PD is able to stand up from a chair or climb a staircase.
The advantages of using digital, mobile and AI technologies in this way, compared to infrequent in-clinic assessments, is that they are highly objective and sensitive, have the possibility to detect symptom fluctuations day-to-day, they are performed in the real-world setting providing increased relevance, they have a relatively low burden for patients, and data can be assessed by the patient and/or physician in near real-time so they become better informed and empowered.
Extending the application beyond clinical trials, disease monitoring and management, these technologies have the potential, in some disorders, to deliver solutions with a direct beneficial effect that can be measured objectively through improved outcomes. Thus, this work is also laying the foundation for advances in digital therapeutics, or “digiceuticals”, where we’ve seen a huge increase in interest, and the first regulatory approvals, over the last year or so.
With great power comes great responsibility, so we work closely with the participants and regulators to ensure that data protection and privacy are upheld to the highest standards and that participants are fully informed and consent.
As we have developed the platform over the past few years, the establishment of robust end-to-end data processes and the building of trust has run side-by-side with the technology innovation.
Q9. What kind of public data did you use for training your models?
Bryn Roberts: The Human Activity Recognition (HAR) model was initially trained using two independent public datasets of everyday activity from normal individuals. The first from Stisen et al. (“Smart devices are different: Assessing and mitigating mobile sensing heterogeneities for activity recognition”, Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, 2015.) and the second from Weiss et al. (“The impact of personalization on smartphone-based activity recognition”, AAAI Workshop on Activity Context Representation: Techniques and Languages, 2012.). From these data, 90% were used to train the model and 10% for model validation.
Q10. What results did you obtain so far?
Bryn Roberts: In passive monitoring of gait and mobility we have published, for example, significant differences between healthy subjects and PD patients in parameters such as sitting-to-standing transitions, turning speed when walking and in overall gait parameters. In the active test panel, we have demonstrated correlation with the current standard rating scale for PD (MDS-UPDRS) in symptom areas such as tremor, dexterity, balance and postural stability. However, in some measurements (e.g. rest tremor) the digital biomarker appears to be more sensitive at detecting low-intensity symptoms than the in-clinic rating, and corresponds better with patients’ self-reported data.
For more information, see, for example: “Evaluation of Smartphone-Based Testing to Generate Exploratory Outcome Measures in a Phase 1 Parkinson’s Disease Clinical Trial”, Lipsmeier et al., Movement Disorders, 2018.
Q11. Are there any other technological advances on the horizon that you are excited about?
Bryn Roberts: There’s a lot of activity in the healthcare and pharma sector at the moment around blockchain. Some of the use-cases have potential interest to us in R&D, such as secure sharing of genomic and medical data.
I don’t think blockchain is a requirement to do this effectively but may be an enabler, especially if it gains broad adoption.
I’m intrigued by the general trend towards empowering individuals to share their data in a secure and controlled environment. Democratisation of data in this way has to be the future. Imagine what we will be able to do in decades to come, when individuals have access to their complete healthcare records in electronic form, paired with high quality data from genomics, epigenetics, microbiome, imaging, activity and lifestyle profiles, etc., supported by a platform that enables individuals to share all or parts of their data with partners of their choice, for purposes they care about, in return for services they value – very exciting!
This vision, and even the large datasets available today, are driving a paradigm shift in data management and compute for us. The need to federate, both data and compute, across multiple locations and organisations is a change from the recent past, when we could internalise all the data of interest into our own data centers. Cloud, Hadoop, containers and other technologies that support federation are maturing quickly and are a great enabler to big data and advanced analytics in R&D.
What I’m particularly excited about just now is the potential of universal quantum computing (QC). Progress made over the last couple of years gives us more confidence that a fault-tolerant universal quantum computer could become a reality, at a useful scale, in the coming years. We’ve begun to invest time, and explore collaborations, in this field. Initially, we want to understand where and how we could apply QC to yield meaningful value in our space. Quantum mechanics and molecular dynamics simulation are obvious targets, however, there are other potential applications in areas such as Machine Learning.
I guess the big impacts for us will follow “quantum inimitability” (to borrow a term from Simon Benjamin from Oxford) in our use-cases, possibly in the 5-15 year timeframe, so this is a rather longer-term endeavour.
————————————————–

Dr Bryn Roberts
Bryn gained his BSc and PhD in pharmacology from the University of Bristol, UK. Following post-doctoral work in neuropharmacology, he joined Organon as Senior Scientist in 1996. A number of roles followed with Zeneca and AstraZeneca, including team and project leader roles in high throughput screening and research informatics. In 2004 he became head of Discovery Informatics at the AstraZeneca sites in Cheshire, UK.
Bryn joined Roche in Basel in 2006, and his role as Global Head of Informatics was expanded in 2014 to Global Head of Operations for Pharma Research and Early Development. He is also the Centre Head for the Roche Innovation Centre Basel.
Beyond Roche, Bryn is a Visiting Fellow at the University of Oxford, where he is a member of the External Advisory Board of the Dept. of Statistics and the Scientific Management Committee for the Systems Approaches to Biomedical Sciences Centre for Doctoral Training. He is a member of the Advisory Board to the Pistoia Alliance. Bryn was recognized in the Fierce Biotech IT list of Top 10 Biotech Techies 2013 and in the Top 50 Big Data Influencers in Precision Medicine by the Big Data Leaders Forum in 2016.
Resources
– How artificial intelligence is changing drug discovery. Nature, 30 May 2018
Related Posts
– AI, Mental Health & Youper. Q&A with Jose Hamilton Vargas. ODBMS.org, August 23, 2018
– On Precision Medicine. Q&A with Todd Winey. ODBMS.org, February 14, 2018
Follow us on Twitter: @odbmsorg
##