Graph Databases for Beginners: Why Data Relationships Matter
Graph Databases for Beginners: Why Data Relationships Matter
by Bryce Merkl Sasaki, Aspiring Graphista, Neo Technology | July 31, 2015
We live in an ever-more-connected world, and data relationships, will only increase in years to come. If your business is to succeed in a highly connected world, you must learn to leverage those connections for all they’re worth – but you’ll need the right technology.
With so many systems built on relational databases or aggregate NoSQL stores, you may not know of a third option that outperforms them both: graph databases.
In this “Graph Databases for Beginners” blog series, I’ll take you through the basics of graph technology assuming you have little (or no) background in the space. Last week, we tackled why graphs are the future.
This week, we’ll discuss why data relationships matter when choosing a database.
The Irony of Relational Databases
Relational databases (RDBMS) were originally designed to codify paper forms and tabular structures, and they still do this exceedingly well. Ironically, however, relational databases aren’t effective at handling data relationships, especially when those relationships are added or adjusted on an ad hoc basis.
The greatest weakness of relational databases is that their schema is too inflexible. Your business needs are constantly changing and evolving, but the schema of a relational database can’t efficiently keep up with those dynamic and uncertain variables.
To compensate, your development team can try to leave certain columns empty (tech lingo: nullable), but this approach requires more code to handle the greater number of exceptions in your data. Even worse, as your data multiplies in complexity and diversity, your relational database becomes burdened with large join tables which disrupt performance and hinder further development.
Consider the sample relational database below.
In order to discover what products a customer bought, your developers would need to write several join tables which significantly slow the performance of the application. Furthermore, asking a reciprocal question like, “Which customers bought this product?” or “Which customers buying this product also bought that product?” becomes prohibitively expensive. Yet, questions like these are essential if you want to build a proper recommendation engine for your transactional application.
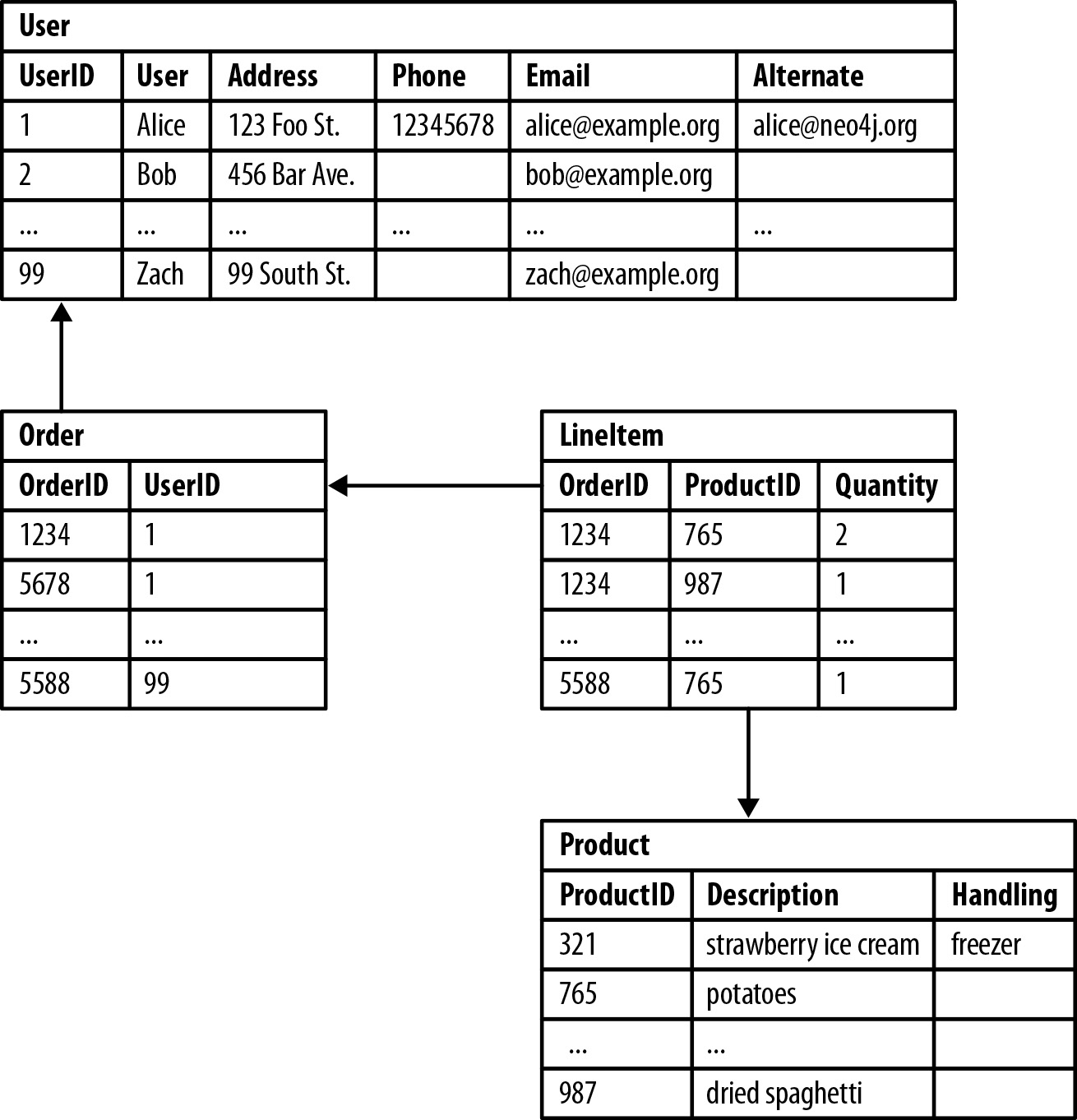
An example relational database where some queries are inefficient-yet-doable (e.g., “What items did a customer buy?”) and other queries are prohibitively slow (e.g., “Which customers bought this product?”).
At a certain point, your business needs will entirely outgrow your current database schema. The problem, however, is that migrating your data to a new scheme becomes incredibly effort-intensive.
Why NoSQL Databases Don’t Fix the Problem Either
NoSQL (or Not only SQL) databases store sets of disconnected documents, values and columns, which in some ways gives them a performance advantage over relational databases. However, their disconnected construction makes it harder to harness data relationships properly.
Some developers add data relationships to NoSQL databases by embedding aggregate identifying information inside the field of another aggregate (tech lingo: they use foreign keys). But joining aggregates at the application level later becomes just as prohibitively expensive as in a relational database.
These foreign keys have another weak point too: they only “point” in one direction, making reciprocal queries too time-consuming to run. Developers usually work around this problem by inserting backward-pointing relationships or by exporting the dataset to an external compute structure, like Hadoop, and computing the result with brute force. Either way, the results are slow and latent.
Graphs Put Data Relationships at the Center
When you want a cohesive picture of your big data, including the connections between elements, you need a graph database. In contrast to relational and NoSQL databases, graph databases store data relationships as relationships. This explicit storage of relationship data means fewer disconnects between your evolving schema and your actual database.
In fact, the flexibility of a graph model allows you to add new nodes and relationships without compromising your existing network or expensively migrating your data. All of your original data (and its original relationships) remain intact.
With data relationships at their center, graph databases are incredibly efficient when it comes to query speeds, even for deep and complex queries. In their book Neo4j in Action, Partner and Vukotic performed an experiment between a relational database and a graph database (Neo4j!).
Their experiment used a basic social network to find friends-of-friends connections to a depth of five degrees. Their dataset included 1,000,000 people each with approximately 50 friends. The results of their experiment are listed in the table below.
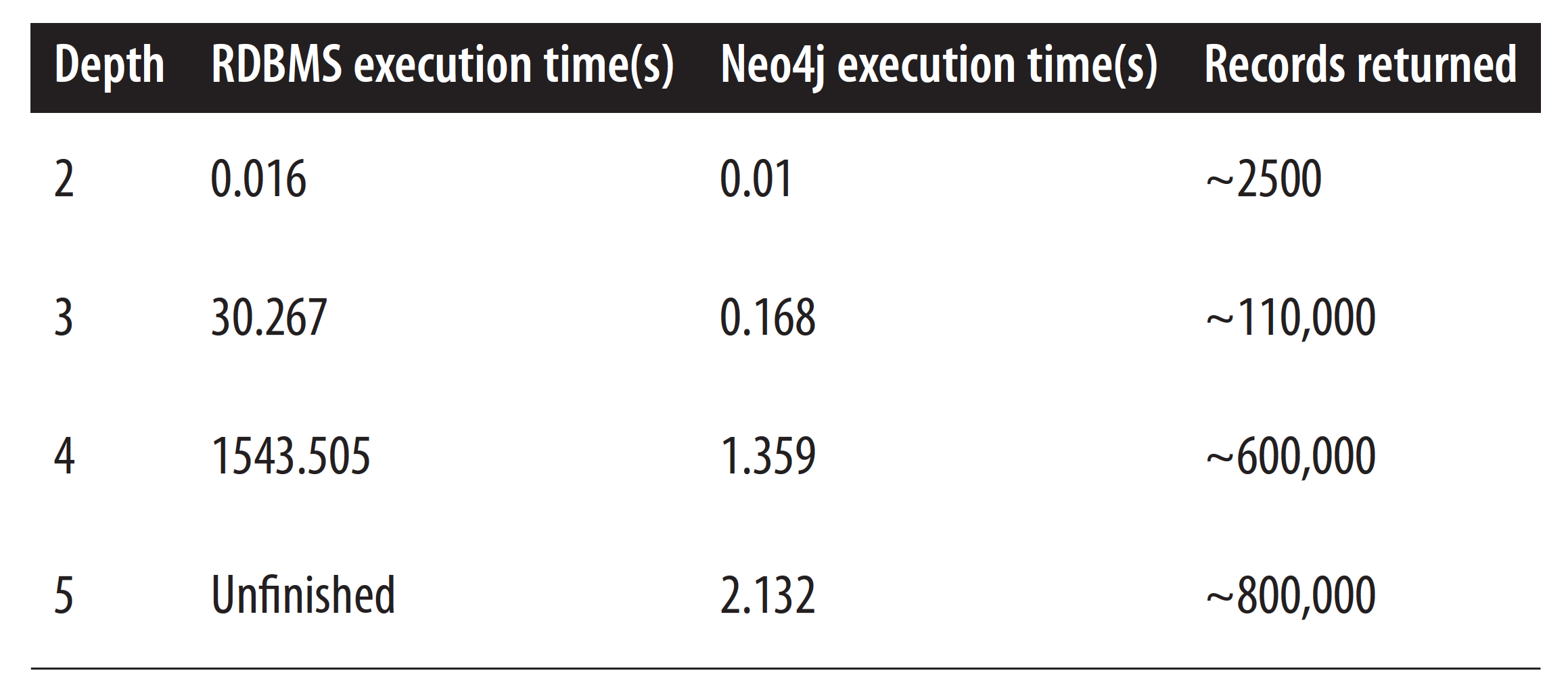
A performance experiment run between relational databases (RDBMS) and Neo4j shows that graph databases handle data relationships extremely efficiently.
At the friends-of-friends level (depth two), both the relational database and graph database performed adequately. However, as the depth of connectedness increased, the performance of the graph database quickly outstripped that of the relational database. It turns out data relationshipsare vitally important.
This comparison isn’t to say NoSQL stores or relational databases don’t have a role to play (they certainly do), but they fall short when it comes to connected data relationships. Graphs, however, are extremely effective at handling connected data.
Want to dive deeper into the world of graph databases? Learn how to apply graph technologies to mission-critical problems with O’Reilly’s Graph Databases. Click below to get your free copy of the definitive book on graph databases and your introduction to Neo4j.
Catch up with the rest of the Graph Databases for Beginners series:
- Graph Databases for Beginners: Why Graphs Are the Future
- Graph Databases for Beginners: The Basics of Data Modeling
- Graph Databases for Beginners: Data Modeling Pitfalls to Avoid
- Graph Databases for Beginners: Why a Database Query Language Matters
About the Author
Bryce Merkl Sasaki, Aspiring Graphista
Bryce Merkl Sasaki is the Content Marketing Manager for Neo Technology. He studied professional and creative writing for undergrad and has been freelancing for 7 years. Recently, he worked at an inbound marketing agency in Philadelphia as a copywriter before moving to California. When not working, he likes to spend his time working on his novel, looking for pickup soccer games and reading voraciously.
Sponsored by Neo Technology