On Ontologies and AI. Q&A with Mattia Ferrini
Q1. You’ve spent two decades working on decision science systems, and ontologies play a critical role in both data management and AI. Can you discuss how you approach the generation and maintenance of ontologies in practice—particularly the tension between expert-designed ontologies versus automated approaches that might leverage machine learning or LLMs to discover and evolve ontological structures? When building decision support systems, how do you determine the right level of ontological granularity and formalism, and what are the practical challenges you’ve encountered in getting organizations to adopt and maintain these knowledge structures over time?
Very rarely data modellers operate in a green field. Data modellers have therefore to understand and consolidate the individual data models of existing business applications and legacy systems. Similarly, data models have to capture correctly the complexity of existing business processes. Working in a brown field is a challenge. Hand-crafting a data model without the support of modern methodologies is rarely feasible, almost never cost effective.
Successful data modelling teams leverage automated approaches that
- Identify classes, attributes and relationships in data sources and their metadata;
- Analyze metadata, documents, wikis, and other unstructured sources to produce an ontology;
- Merge the data model generated from data sources with the ontology generated from all available data sources
- Enrich the merged ontology with semantic information to produce a semantic data model
- Integrate third party and domain specific ontologies
Progress in language models has boosted the effectiveness of this approach. The careful hand-crafting of experts focuses uniquely on polishing, through agile iterations, the output of systematic processes. The work of data modelling experts, and their ability to capture business needs, remains highly relevant especially downstream, when crafting the data model of data marts and the data model of self-service consumption layers. Downstream, expert modellers will ensure the user friendliness of the model, striking the right balance between granularity and simplicity, at data aggregation level but also at ontological level. In other words, the right granularity and simplicity depend on the needs of the users and the use-cases that they’ll be working on. Through automation, data modelers win more time to focus on the needs of data consumers, and the crafting of business definitions and KPIs.
So far, we have discussed the development of data models, but you make a valid point: the maintenance of data models is also a challenge. Data models in the underlying data sources might change; business definitions might be revised; processes might be redefined and documents might be amended. In other words, data modellers wrestle with a moving target.
The periodic execution of automated processes that build data models from structured and unstructured data and its metadata flags deviations and changes. This is tremendously useful when third party applications and interfaces are in-scope.
Q2. Data quality is fundamental to sound decision-making, yet it’s often treated as a checklist exercise rather than a rigorous discipline. You’ve worked on applying mathematical models to data quality management—can you explain your approach? How do you formally model data quality dimensions like completeness, consistency, accuracy, and timeliness in ways that enable quantitative reasoning and optimization?
In my opinion, the biggest misconception about data is the idea that data is the new oil. Oil is fungible and has intrinsic value. Data is neither fungible nor has intrinsic value. Data has only value through the use we make of it. From this, we can deduce that data quality requirements depend on the needs of each use-case. For example, think about handling missing data: depending on the use-case, one imputation approach might work better than others. As the size of the use-case portfolio grows, data quality management efforts multiply.
At the same time, data quality management is often solely associated with accuracy. This is incorrect, and this oversimplification leads organizations to underestimate data quality management efforts.
Multiply the number of use-cases with the number of data quality dimensions, and you immediately realize why data quality is a challenge for many organizations. It is obvious that, for data quality to scale, automation and AI are a necessary ingredient.
In my experience, the first step in this journey has been an investigation of modelling approaches: what is the best approach to facilitate the roll out of automation and AI solutions? Graphs work well with data modelling. It feels straightforward to extend semantic data models with data quality requirements, and organizations capture synergies when doing this: data quality requirements increase the semantic information in the data model. For example, knowing that a product quantity needs to be strictly positive helps finance experts recognize that quantity cannot be set to a negative value to represent product returns, and that returns need to be handled through another entity.
Across several projects, a graph-based approach has proven to be the natural way to express requirements across multiple dimensions. For example, graphs can represent complex accuracy requirements for individual entities as well as relationships spanning multiple entities.
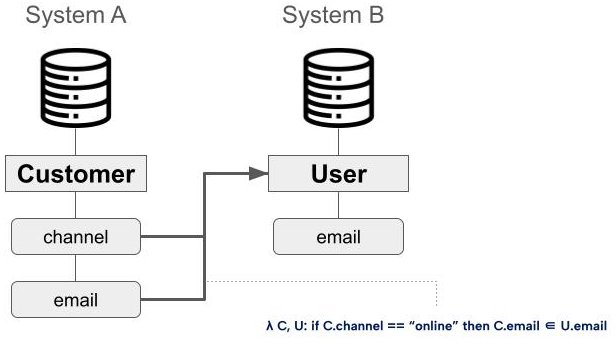
Figure 1: Data quality relationships represented as relationships between classes and properties. This provides a useful abstraction over their potentially multiple implementations, such as rules in data quality tools or assertions in Python frameworks (e.g., Great Expectations). The actual implementation and validation of data quality rules can then be generated through metaprogramming by traversing the graph. Data quality relationships can become integral part of Knowledge Graphs
Similarly, traversing data lineage allows automated identification of potential consistency issues. For instance, if lineage shows that one process transfers customer address data from the CRM system to the ERP, while another process moves the same data back from the ERP to the CRM, this highlights a risk of inconsistencies.
Q3. The integration of symbolic AI (e.g. ontologies, knowledge graphs, rule-based expert systems, solvers) with modern neural approaches (e.g. Deep Learning, LLMs) represents a major frontier in AI research. From your perspective as someone who bridges both worlds, what are the most promising architectural patterns for this integration? Where do you see the complementary strengths?
I have been working on compositionality for well over a decade. Ultimately,the idea that intelligence relies on the ability to use independent modules, skills, or tools dates back at least to the 1980s. I think, for example, about the modularity of mind by Fodor [1]. Initially, monolithic approaches such as large deep neural networks as well as transformer architectures neglected this aspect. Lately, there have been several attempts to improve the compositional properties of models. For example, Mixtures of Experts [2] go in this direction, and are today – in different flavors – a staple in the industry. Interestingly, there have been explicit studies of compositionality in transformer-based models: compositionality is becoming a priority in the roadmap to higher reasoning capabilities.
I like to explore the integration of symbolic AI from a compositionality perspective. My first attempts to train models to compose tools was through reinforcement learning. The progress through this approach rapidly plateaued: it was really difficult to deal with sparse rewards, and the choice of tools – without any additional form of guidance for the models – proved to be an insurmountable combinatorial problem.
In my opinion, it is more effective to train models to generate an intermediate representation of the problem. The intermediate representation accelerates learning, and guides compositionality. I refer to an approach similar to Neural Module Networks (NMN) where an intermediate problem representation defines how task-specific neural networks (modules) are stashed together in a bigger neural network architecture [3]. NMNs are a great example and this framework can be extended to other types of components, including rule-based systems or python functions.
Ontologies and knowledge graphs have successfully been used to improve the ability of a language model to produce an effective intermediate representation for compositionality. Ideas include Graph Attention Networks as well as enriching Chain-of-Thought and its variations (e.g. Tree-of-Thought, Graph-of-Thought) with knowledge graph information – in other words, grounding the reasoning of LLMs with Knowledge Graphs [4, 5, 6, 7]. For example, suppose a user wonders whether Stephen King wrote about India. The knowledge base might not contain a direct answer to this question, nor an explicit list of locations featured in King’s works. However, the relationships between the author and his novels can still guide the AI in generating potential solution paths. This improves the capabilities of AI systems to retrieve information as well as their logical reasoning.
Q4. What are the technical challenges in making these hybrid systems maintainable?
The biggest technical challenge is that hybrid systems have many moving parts. Their components, tools, and services may be developed by different teams, both inside and outside the organization. Think of all the complexity of microservice architectures in software engineering — and on top of that, add an AI system that must dynamically integrate those services on the fly to answer each new user request. This exacerbates the impact of every coordination issue, imprecision in documentation, and misalignment in the use and interpretation of concepts.
Q5. What lessons have you learned about when compositionality breaks down in practice—particularly when dealing with the probabilistic, context-dependent nature of modern AI systems?
The biggest hurdle is dealing with the inherent ambiguities of natural language. Writing a query in SQL forces developers to strictly follow conventions such as table names, column names, and joins. SQL leaves no room for “guessing.” Natural language, on the other hand, is imprecise, and—as you correctly noted—its semantics can shift depending on the context of the request. One could even argue that “natural language programming” is a step backward rather than forward. Dijkstra made strong arguments to this effect as early as 1978 [8]. In practice, however, allowing users to communicate in their natural language of choice is a major driver of adoption. The real question, then, is how to deal with the lack of rigor inherent in natural languages.
Paradoxically, the probabilistic nature of language models is a feature, not a bug: it allows them to explore multiple representations and mappings from language to symbols, thereby probing the solution space. The biggest lesson for me has been that the ultimate goal is to satisfy users’ needs; there’s no point in getting “stuck” on a problem because the AI insists on a rigid translation from language to symbolic representations.
If a user asks, “What is the surface of a triangle with a base of 10 and a height of 7?” compositionality might break because the model could interpret “surface” too literally. Embracing the fact that language—and users—can be imprecise helps deliver a better experience and address user needs more proactively. The system can always point out that “surface” is imprecise wording, but the most important thing is that the system is able to progress towards a solution.
Q6. Operations research (OR) and optimization have traditionally relied on carefully constructed mathematical programs with explicit objective functions and constraints, while LLMs excel at flexible, context-aware reasoning but lack the formal guarantees of optimization systems. You work at the intersection of these domains—can you describe technical approaches for integrating optimization systems with language models? For example, how might an LLM help formulate optimization problems from natural language descriptions, or how could optimization solvers be invoked by LLMs to ensure decisions satisfy hard constraints?
We could expect that LLMs might, at one point, provide the same capabilities of optimization solvers. My take is that we’re really far from that. A second approach would be to wonder whether LLMs might be capable of producing a mathematical program that can be efficiently solved (if feasible) by a solver. I periodically evaluate the program synthesis capabilities of LLMs as soon as LLMs hit the market. My take is that LLMs can draft a mathematical program, for example in Pyomo or AMPL; unfortunately, though, the mathematical programs produced by LLMs are often buggy, and LLMs, despite expert feedback, still struggle to fix them.
My work at the intersection of AI and Operations Research focuses on building AI models that produce the necessary intermediate representations that capture the nuances of optimization problems from natural language requirements, and then ensure that specialized models translate the intermediate representation into a correct mathematical program. Language models can also explain the output of the solver to a user in plain language.
I am very excited about my work in this space: solver performance has increased several billion times in the past 30 years. However, adoption in the consumer as well as the business world is still poor. My take is that most of the time solvers sit behind horrible user interfaces, crowded with buttons, text boxes and toggles. Such interfaces are necessary when a human is required to communicate his needs and amend the assumptions behind an optimization problem. Today, operations research projects are simply discontinued because users don’t manage to communicate to optimization systems what they need. Conversational agents can reduce the barriers to the adoption of operations research applications. Conversational agents will finally put operations research in the hands of non-OR experts.
References
[1] Fodor, Jerry A. The modularity of mind. MIT press, 1983.
[2] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[3] Andreas, Jacob, et al. “Deep compositional question answering with neural module networks. CoRR abs/1511.02799 (2015).” Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
[4] Veličković, Petar, et al. “Graph attention networks.” arXiv preprint arXiv:1710.10903 (2017).
[5] Yao, Shunyu, et al. “Tree of thoughts: Deliberate problem solving with large language models.” Advances in neural information processing systems 36 (2023): 11809-11822.
[6] Besta, Maciej, et al. “Graph of thoughts: Solving elaborate problems with large language models.” Proceedings of the AAAI conference on artificial intelligence. Vol. 38. No. 16. 2024.
[7] Amayuelas, Alfonso, et al. “Grounding LLM Reasoning with Knowledge Graphs.” arXiv preprint arXiv:2502.13247 (2025).
[8] Edsger W. Dijkstra. 1978. On the Foolishness of “Natural Language Programming”. In Program Construction, International Summer School. Springer-Verlag, Berlin, Heidelberg, 51–53.
…………………………………………

Mattia Ferrini has two decades of experience in Machine Learning and AI. He has worked across several industries at the intersection of AI, operations research, and decision sciences. His main interests include compositionality and the integration of symbolic systems with modern AI methodologies.